May 23, 2016 · guest post
Evaluating Summarization Systems

We’re excited for tomorrow’s online discussion about automatic text summarization! You can register here.
During the event, Mohamed AlTantawy, CTO of Agolo, will explain the tech behind their summarization tool. In this blog post, he describes how his team evaluates the quality of summaries produced by their system. Join us tomorrow to learn more and ask questions about the approach!
Evaluating the quality of algorithmically created summaries is a very hard task. There are two main approaches to evaluating summaries: automatic and manual. While both approaches need human input, the automatic approach only needs human effort to build the reference summaries. Once we have the reference or gold standard summaries, there are metrics that can automatically determine the quality of the generated summaries by comparing them to the human created references. Automatic evaluation of summaries has been an active area of research for a long time and it is still far from being solved.
At Agolo, we are always tuning and improving our summarization engines. Without a systematic approach for evaluating our work, it would be impossible to measure our progress. In this blog post, will focus on the methods we use to evaluate our multi-document news summarizer. Some of the automatic evaluation methods discussed below do not lend themselves to evaluating some of our other systems, such as our engine for summarizing long-format reports or our domain-specific summarizers. This is due to the lack of a human-created gold standard. The widely different formats (and sometimes genres) of documents makes it hard to evaluate different summarization tasks on the same standard. For example, most of the highly adopted Document Understanding Conference (DUC) datasets are newswire documents which make it unfit to evaluate the summaries of SEC filings. In these cases, we opt to use human evaluations with the goal of understanding and learning new evaluation methods to fully automate them.
Rouge
Since being introduced by Chin-Yew Ling in 2004, Rouge has become the de facto metric for automatic summarization evaluation. Rouge stands for Recall-Oriented Understudy of Gisting Evaluation. It is a recall-based metric to automatically determine the quality of an algorithmically generated summary by comparing it to other gold-standard summaries created by humans. This metric measures content overlap between two summaries which means that the distance between two summaries can be established as a function of their vocabulary and how this vocabulary is used.
Rouge has a couple of limitations:
- To use Rouge, one has to use reference summaries that typically involve expensive human effort. Moreover, selecting content to serve as summaries is not a deterministic problem. Human inter-agreement is low when it comes to choosing sentences that best represent a document, let alone a group of documents. Lin and Hovy investigated the DUC 2001 human assessment data and found that humans expressed agreement about 82% of the time in 5,921 total judgments on the single document summarization evaluation task.
- Semantic equivalence is another problem. Two sentences may express the same meaning using different words. Such scenarios will be harshly penalized by Rouge. ParaEval is another approach to automatically evaluating summaries using paraphrases.
Readability
Our summarization engines are mostly extractive. However, in many cases, we change the original sentences to make the summaries more readable. For example, coreference resolution is often used to replace pronouns and other references with their original entities, for example, the following sentence:
“The market is maturing,” and opening retail stores in India helps “form the building blocks” for the firm in the country, he said.
would change to:
“India’s smartphone market is maturing,” and opening retail stores in India helps “form the building blocks” for the firm in the country, Rushabh Doshi said.
As a result, we want to ensure that the modified sentence will not affect the readability of the summaries. The Gunning Fox Index measures the readability of English writing. The index estimates the years of formal education needed to understand the text on a first reading. It is a linear equation of the average sentence length and percentage of complex words whose scale provides an estimate of grade level. Complex words are defined as words with three or more syllables. Text with a Fog Index value over 18 is generally considered unreadable.
Fog Index = 0.4 (average number of words per sentence + percent of complex words)
For the purpose of this task, we are not interested in the absolute values of the Fox Index, but rather in the relative score of the modified text when compared to the original text. We ensure that that the difference in readability score between the original text and the modified text remains within a 10% scale. This method will become useful as we move from extractive to abstractive summaries.
Speed and Complexity
The speed of the summarization engine is another aspect that we continuously evaluate. As the amounts of text we summarize daily grows, we have to make to make sure that our engines will work efficiently and scale with big volume of data.
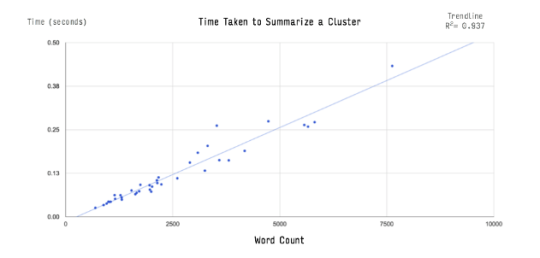
Our summarization algorithm transforms the input text into high-dimensional sparse vectors, which can be efficiently analyzed in linear time O(n) to produce the final summaries. The theoretical analysis is borne out in our performance logs, which shows the processing time increasing linearly with respect to the size of the input documents. For examples, summarizing a little more than 7,500 words (7 news articles), takes less than half a second.
- Mohamed AlTantawy, Agolo









