Apr 2, 2019 · featured post
A Guide to Learning with Limited Labeled Data
We are excited to release Learning with Limited Labeled Data, the latest report and prototype from Cloudera Fast Forward Labs.
Being able to learn with limited labeled data relaxes the stringent labeled data requirement for supervised machine learning. Our report focuses on active learning, a technique that relies on collaboration between machines and humans to label smartly.
Active learning makes it possible to build applications using a small set of labeled data, and enables enterprises to leverage their large pools of unlabeled data. In this blog post, we explore how active learning works. (For a higher level introduction, please see our previous blogpost.)
The active learning loop
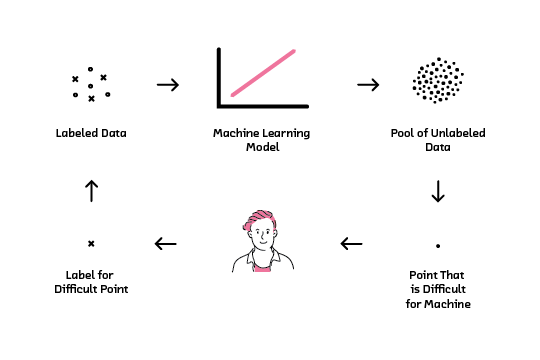
Active learning takes advantage of the collaboration between humans and machines to smartly select a small subset of datapoints for which to obtain labels. It is an iterative process, and ideally access is available to some initial labels to start. These initial labels allow a human to build a baseline machine learning model, and use it to predict outputs for all the unlabeled datapoints. The model then looks through all its predictions, flags the one with which it has the most difficulty, and requests a label for it. A human steps in to provide the label, and the newly labeled data is combined with the initial labeled data to improve the model. Model performance is recorded, and the process repeats.
The active learning loop
How to select datapoints
At the heart of active learning is a machine (learner) that requests labels for datapoints that it finds particularly hard to predict. The learner follows a strategy, and uses it to identify these datapoints. To evaluate the effectiveness of the strategy, a simple approach for choosing datapoints needs to be defined. A good starting point is to remove the intelligence of the learner; the datapoints are chosen independently of what the learner thinks.
Random sampling
When we take the learner out of the picture, what is left is a pool of unlabeled data and some labeled data from which a model can be built. To improve the model, the only reasonable option is to randomly start labeling more data. This strategy is known as random sampling, and selects unlabeled datapoints from the pool according to no particular criteria. You can think of it as being akin to picking a card from the top of a shuffled deck, then reshuffling the deck without the previously chosen card and repeating the action. Because the learner does not help with the selection process, random sampling is also known as passive learning.
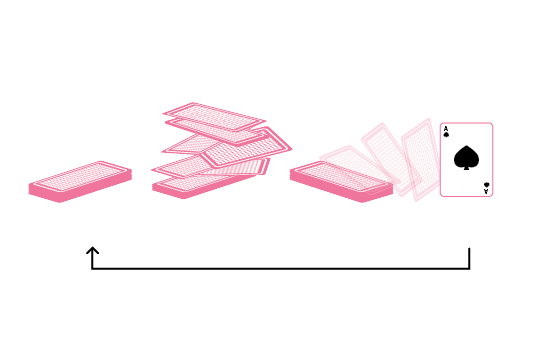
Random sampling is like picking the top card from a shuffled deck
Uncertainty sampling
A slightly more complex strategy is to select datapoints that the model is uncertain about. In uncertainty sampling, the learner looks at all unlabeled datapoints and surfaces the ones about which it is uncertain. Labels are then provided by a human, and fed back into the model to refine it.
But how do we quantify uncertainty? One way is to use the distance between the datapoint and the decision boundary. Datapoints far away from the decision boundary are safe from changes in the decision boundary. This implies that the model has high certainty in these classifications. Datapoints close to the boundary, however, can easily be affected by small changes in the boundary. The model (learner) is not certain about them; a slight shift in the decision boundary will cause them to be classified differently. The margin sampling strategy therefore dictates that we surface the datapoint closest to the boundary and obtain a label for it.
There are many other selection strategies that can be used with active learning. Our report explores some of them in detail.
When to stop
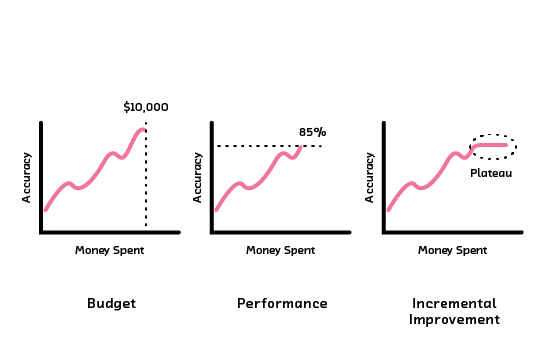
Because active learning is an iterative process, when should we stop? Each label comes with a cost of acquisition - the amount of money and time it takes to acquire the label. With this cost in mind, the stopping criteria can either be static or dynamic. A static criteria sets a budget limit or performance target in the beginning. A dynamic criteria looks at the incremental gain in performance over each round of active learning and stops when it is no longer worthwhile to acquire more labels (the incremental performance plateaus).
Stopping criteria for active learning
Does it work for deep learning?
Deep learning introduces a couple of wrinkles that make direct application of active learning ineffective. The most obvious issue is that adding a single labeled datapoint does not have much impact on deep learning models, which train on batches of data. In addition, because the models need to be retrained until convergence after each point is added, this can become an expensive undertaking – especially when viewed in terms of the performance improvement vs. acquisition cost (time and money) trade-off. One straightforward solution is to select a very large subset of datapoints to label. But depending on the type of heuristics used, this could result in correlated datapoints. Obtaining labels for these datapoints is not ideal – datapoints that are independent and diverse are much more effective at capturing the relationship between input and output.
The second problem is that existing criteria used to help select datapoints do not translate to deep learning easily. Some require computation that does not scale to models with high-dimensional parameters. These approaches are rendered impossible with deep learning. For the criteria that are computationally viable, reinterpretation under the light of deep learning is necessary.
In our report, we take the idea of uncertainty and examine it in the context of deep learning.
Practical considerations
Active learning sounds tempting - with this approach, it is possible to build applications previously constrained by lack of labeled data. But active learning is not a silver bullet.
Choosing a learner and a strategy
Active learning relies on a small subset of labeled data at the beginning to choose both the learner and strategy. The learner is used to make predictions for all the unlabeled data and the strategy selects the datapoints that are difficult. Choosing a learner (or model) for any machine learning problem is difficult, but it is made even more difficult with active learning for two reasons. First, the choice of a learner needs to be made very early on when we only have a small subset of labeled data. Second, the learner is not just used to make predictions, it is used in conjunction with the strategy to surface datapoints that will help refine itself. This tight feedback loop amplifies the effect of a wrong learner.
In addition, some selection strategies result in a labeled dataset that is biased. Margin sampling, for example, surfaces datapoints right around the decision boundary to be labeled. Most datapoints far from the boundary might not even be used in building the model, resulting in a labeled dataset that may not be representative of the entire pool of unlabeled data.
Human biases
Because a human needs to step in to provide labels, this restricts the type of use cases to which active learning can be applied. Humans can label images and annotate text, but we cannot tell if a financial transaction is fraudulent just by looking at the data.
In addition, the data that requires human labeling is by definition more difficult. Under these circumstances, it is easy for a human to inject his own bias and judgement when making labeling decisions.
A pause between iterations
When applying active learning in real life, surfaced datapoints will need to be sent to a human for labeling. The next round of active learning cannot proceed until the newly labeled datapoints are ready.
The length of time between each active learning iteration varies depending on who provides the label. In a research scenario, a data scientist who builds the model and also creates labels will be able to iterate through each round of active learning quickly. In a production scenario, an outsourced labeling team will need more time for data exchange and label (knowledge) transfer to occur.
For active learning to be successful, the pause between iterations should be as small as practically possible. In addition to considering different types of labeling workforce, an efficient pipeline needs to be set up. This pipeline should include a platform for exchanging unlabeled datapoints, a user interface for creating labels, and a platform for transferring the labeled datapoints.
Active Learner
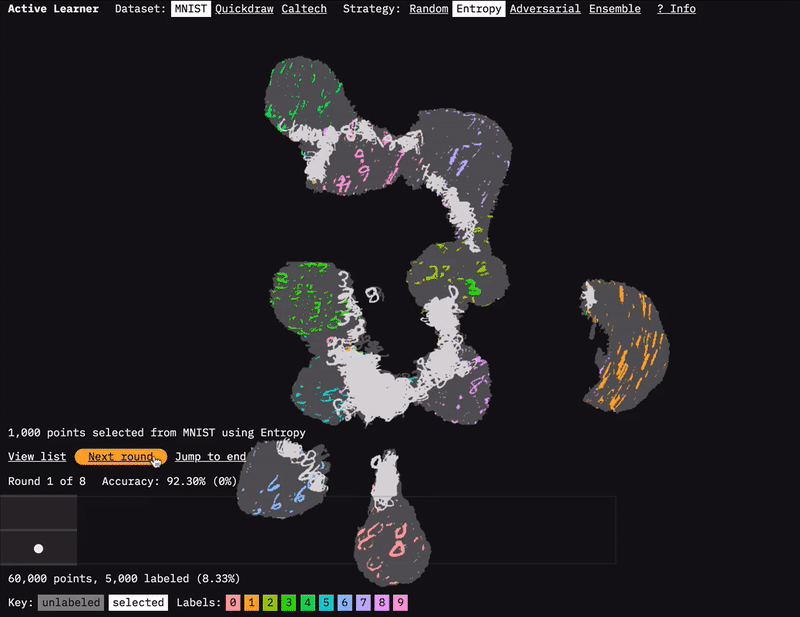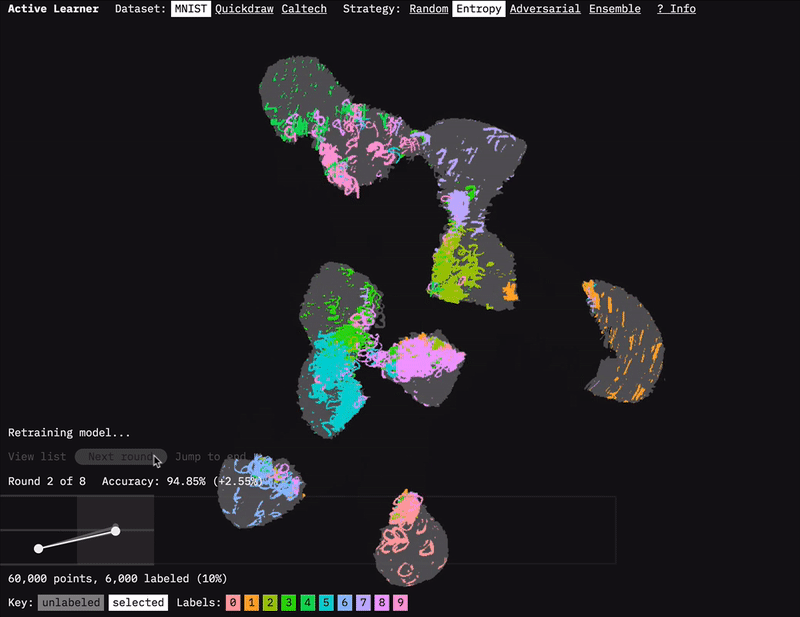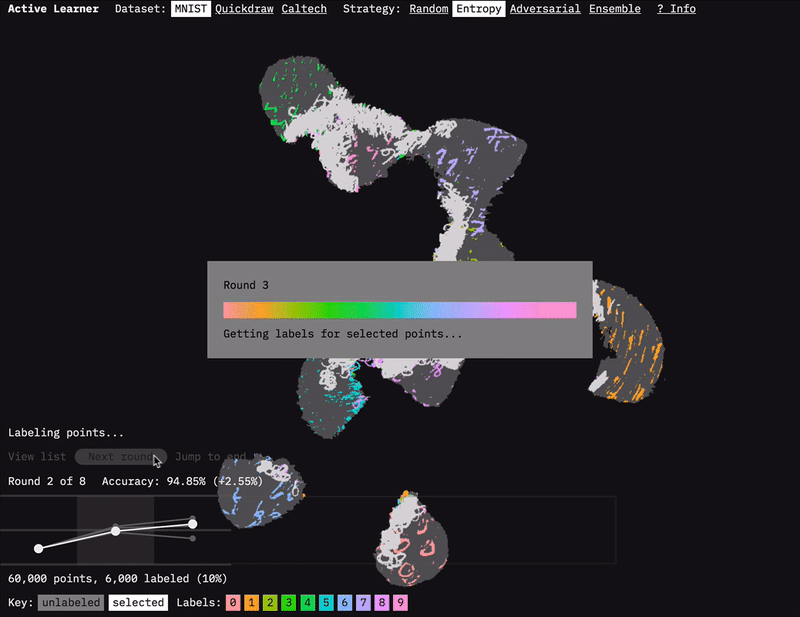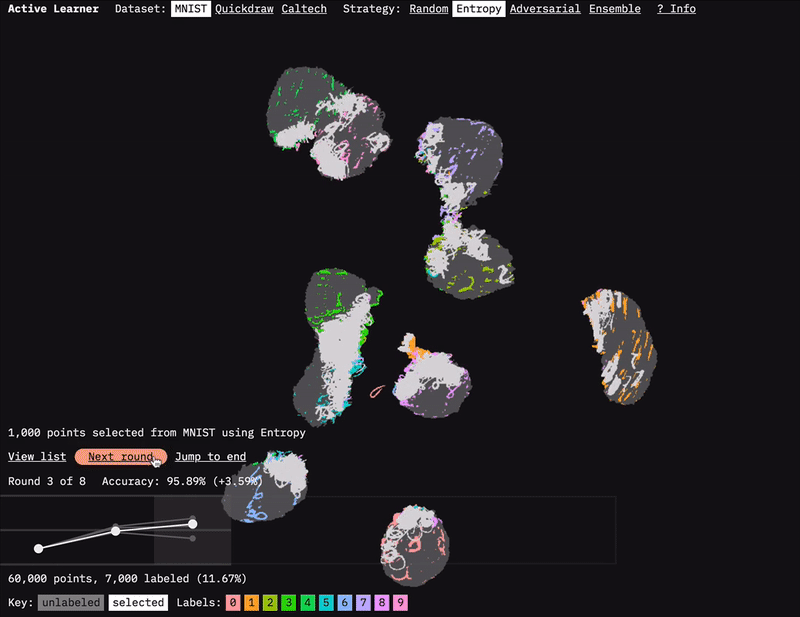
We built the Active Learner prototype to accompany this report.
Every Cloudera Fast Forward Labs report comes with a prototype. We don’t just write about a new exciting capability in machine learning; we also experiment with it to understand what it can and cannot do.
The prototype for our report on Learning with Limited Labeled Data is called Active Learner. It is a tool that sheds light on and provides intuition for how and why active learning works. The prototype allows one to visualize the process of active learning over different types of datasets and selection strategies. We hope you enjoy exploring it.
Conclusion
Active learning makes it possible to build machine learning models with a small set of labeled data. It offers one way for enterprises to leverage their large pools of unlabeled data for building new products, but it is not the only solution to learning with limited labeled data.
Our report goes into much more detail (including strategies specific to deep learning, resources and recommendations for setting up an active learning production environment, and technical and ethical implications). Join our webinar to learn more, explore the prototype and get in touch if you are interested in accessing the full report (which is available by subscription to our research and advising services).









