FF24
Text Style Transfer

The NLP task of text style transfer (TST) aims to automatically control the style attributes of a piece of text while preserving the content, which is an important consideration for making NLP more user-centric. In this report, we explore text style transfer through an applied use case — neutralizing subjectivity bias in free text. Along the way, we describe our sequence-to-sequence modeling approach leveraging HuggingFace Transformers, and present a set of custom, reference-free evaluation metrics for quantifying model performance. Finally, we conclude with a discussion of ethics centered around our prototype: Exploring Intelligent Writing Assistance.
FF22
Inferring Concept Drift Without Labeled Data

Concept drift occurs when the statistical properties of a target domain change overtime causing model performance to degrade. Drift detection is generally achieved by monitoring a performance metric of interest and triggering a retraining pipeline when that metric falls below some designated threshold. However, this approach assumes ample labeled data is available at prediction time - an unrealistic constraint for many production systems. In this report, we explore various approaches for dealing with concept drift when labeled data is not readily accessible.
FF19
Session-based Recommender Systems

Being able to recommend an item of interest to a user (based on their past preferences) is a highly relevant problem in practice. A key trend over the past few years has been session-based recommendation algorithms that provide recommendations solely based on a user’s interactions in an ongoing session, and which do not require the existence of user profiles or their entire historical preferences. This report explores a simple, yet powerful, NLP-based approach (word2vec) to recommend a next item to a user. While NLP-based approaches are generally employed for linguistic tasks, here we exploit them to learn the structure induced by a user’s behavior or an item’s nature.
FF18
Few-Shot Text Classification

Text classification can be used for sentiment analysis, topic assignment, document identification, article recommendation, and more. While dozens of techniques now exist for this fundamental task, many of them require massive amounts of labeled data in order to be useful. Collecting annotations for your use case is typically one of the most costly parts of any machine learning application. In this report, we explore how latent text embeddings can be used with few (or even zero) training examples and provide insights into best practices for implementing this method.
FF16
Structural Time Series
Time series data is ubiquitous. This report examines generalized additive models, which give us a simple, flexible, and interpretable means for modeling time series by decomposing them into structural components. We look at the benefits and trade-offs of taking a curve-fitting approach to time series, and demonstrate its use via Facebook’s Prophet library on a demand forecasting problem.
FF15
Meta-Learning
In contrast to how humans learn, deep learning algorithms need vast amounts of data and compute and may yet struggle to generalize. Humans are successful in adapting quickly because they leverage their knowledge acquired from prior experience when faced with new problems. In this report, we explain how meta-learning can leverage previous knowledge acquired from data to solve novel tasks quickly and more efficiently during test time
FF14
Automated Question Answering
Automated question answering is a user-friendly way to extract information from data using natural language. Thanks to recent advances in natural language processing, question answering capabilities from unstructured text data have grown rapidly. This blog series offers a walk-through detailing the technical and practical aspects of building an end-to-end question answering system.
FF13
Causality for Machine Learning

The intersection of causal inference and machine learning is a rapidly expanding area of research that's already yielding capabilities to enable building more robust, reliable, and fair machine learning systems. This report offers an introduction to causal reasoning including causal graphs and invariant prediction and how to apply causal inference tools together with classic machine learning techniques in multiple use-cases.
FF06-2020
Interpretability
Interpretability, or the ability to explain why and how a system makes a decision, can help us improve models, satisfy regulations, and build better products. Black-box techniques like deep learning have delivered breakthrough capabilities at the cost of interpretability. In this report, recently updated to include techniques like SHAP, we show how to make models interpretable without sacrificing their capabilities or accuracy.
FF12
Deep Learning for Anomaly Detection
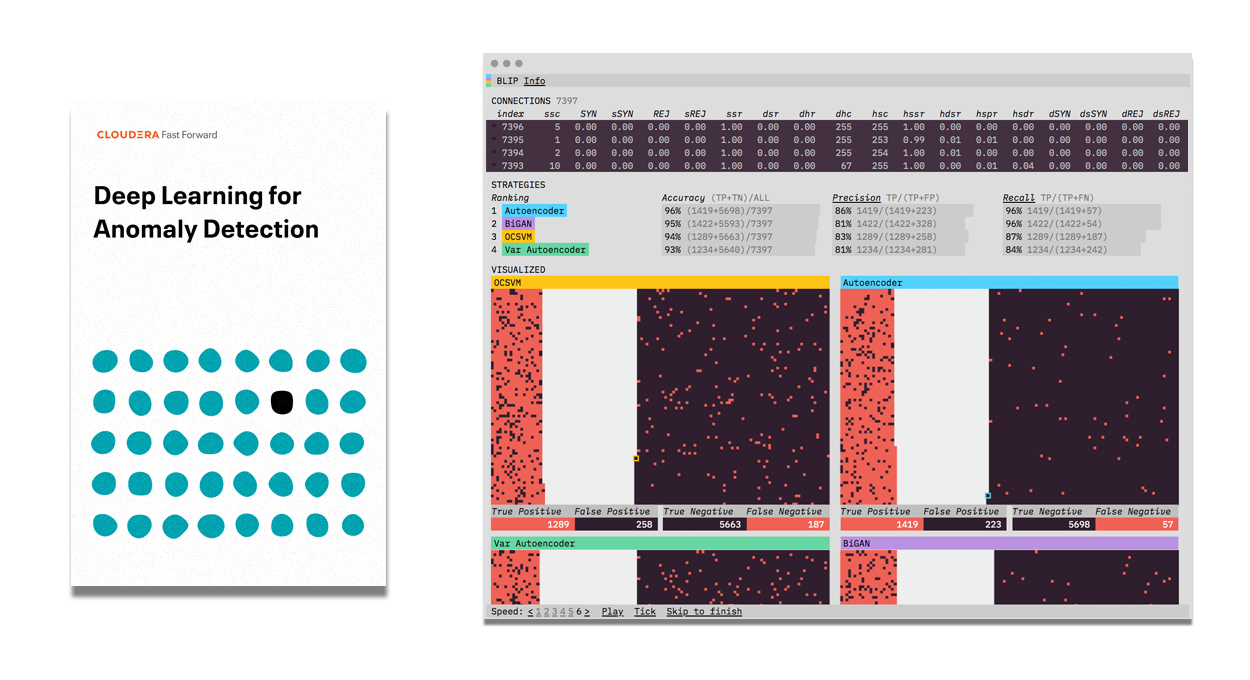
From fraud detection to flagging abnormalities in imaging data, there are countless applications for automatic identification of abnormal data. This process can be challenging, especially when working with large, complex data. This report explores deep learning approaches (sequence models, VAEs, GANs) for anomaly detection, when to use them, performance benchmarks, and product possibilities.
FF11
Transfer Learning for Natural Language Processing
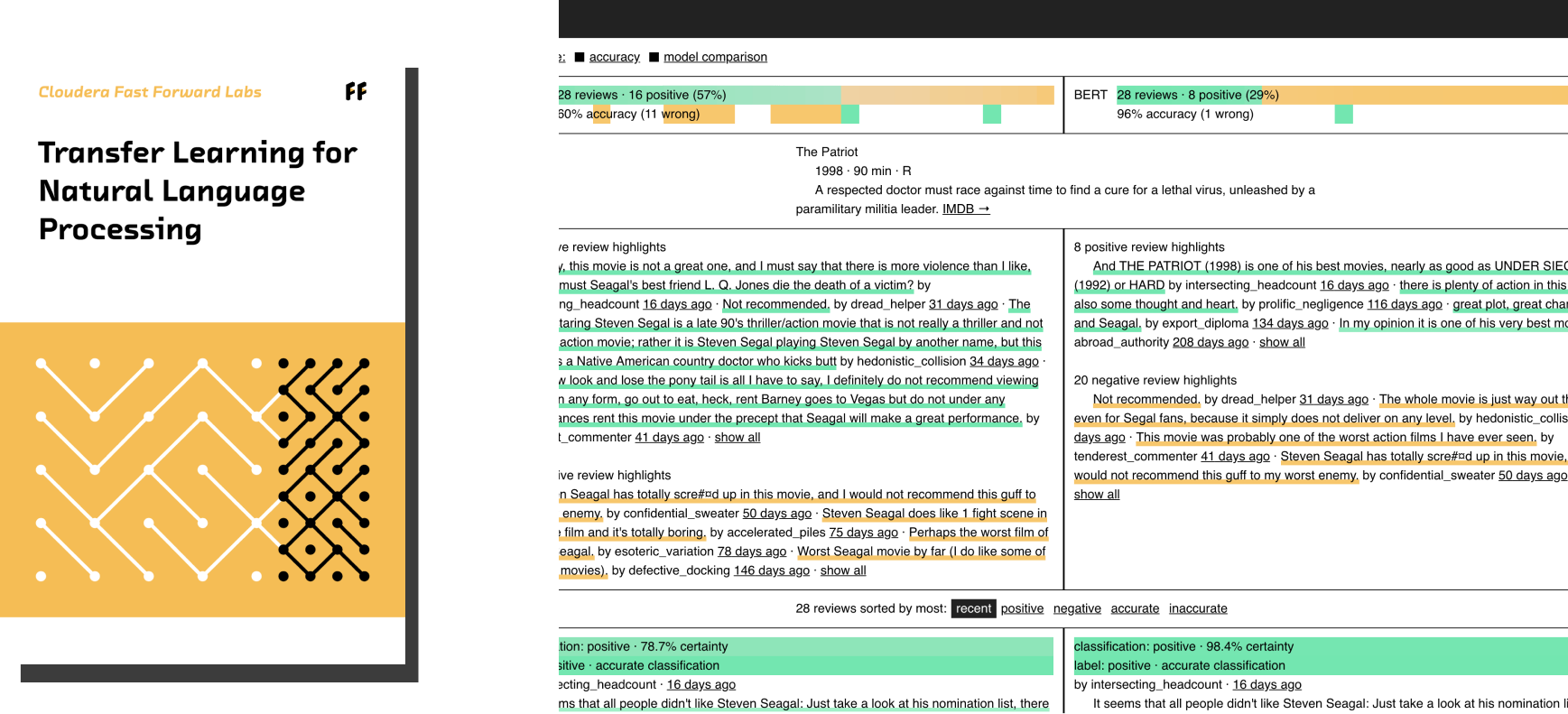
Natural language processing (NLP) technologies using deep learning can translate language, answer questions, and generate human-like text But these deep learning techniques require large, costly labeled datasets, expensive infrastructure, and scarce expertise. Transfer learning lifts these constraints by reusing and adapting a model’s understanding of language. Transfer learning is a good fit for any NLP application. In this report, we show how to use transfer learning to build high-performance NLP systems with minimal resources.
FF10
Learning with Limited Labeled Data
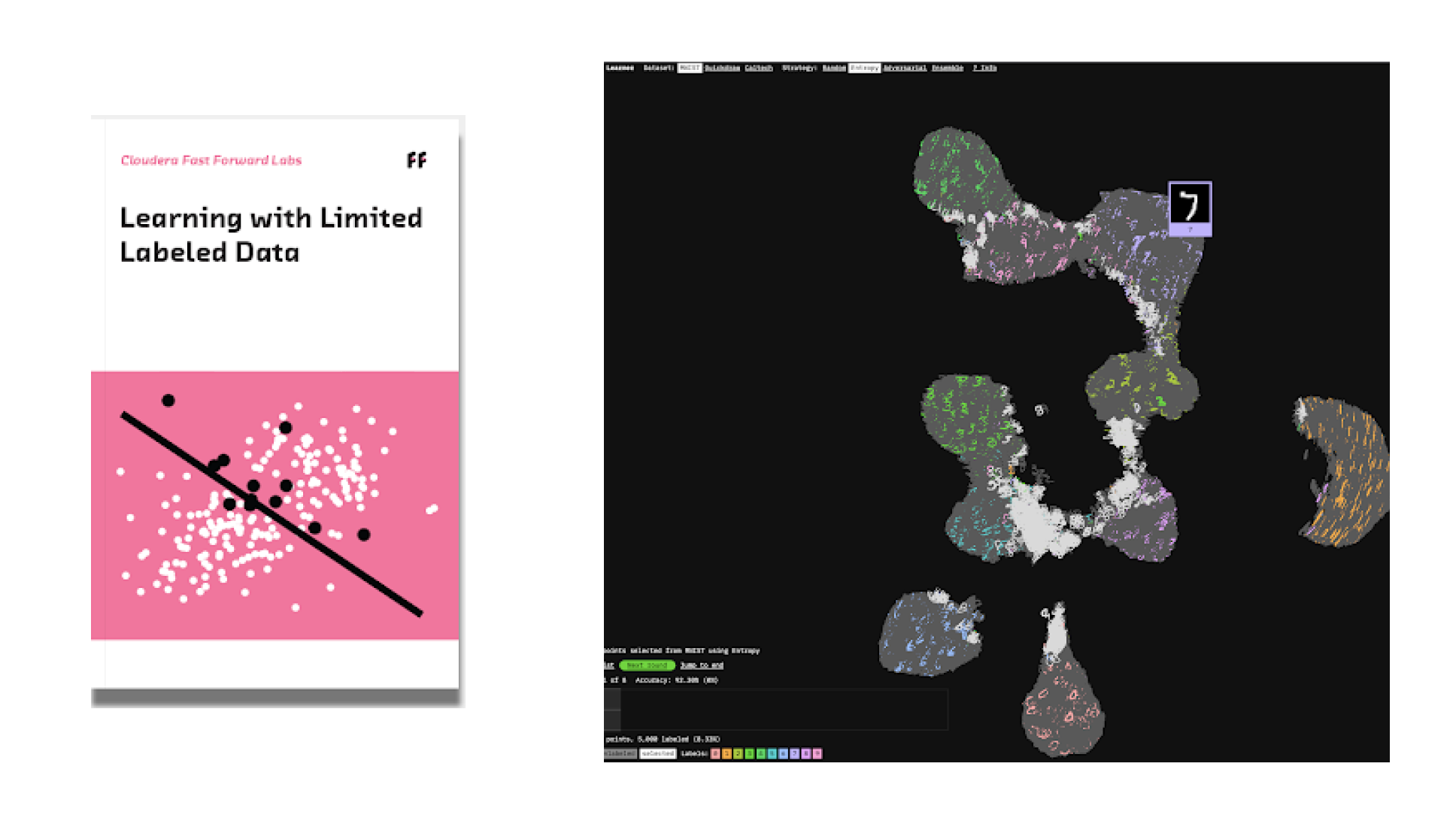
Being able to learn with limited labeled data relaxes the stringent labeled data requirement for supervised machine learning. This report focuses on active learning, a technique that relies on collaboration between machines and humans to label smartly. Active learning reduces the number of labeled examples required to train a model, saving time and money while obtaining comparable performance to models trained with much more data. With active learning, enterprises can leverage their large pool of unlabeled data to open up new product possibilities.
FF09
Federated Learning
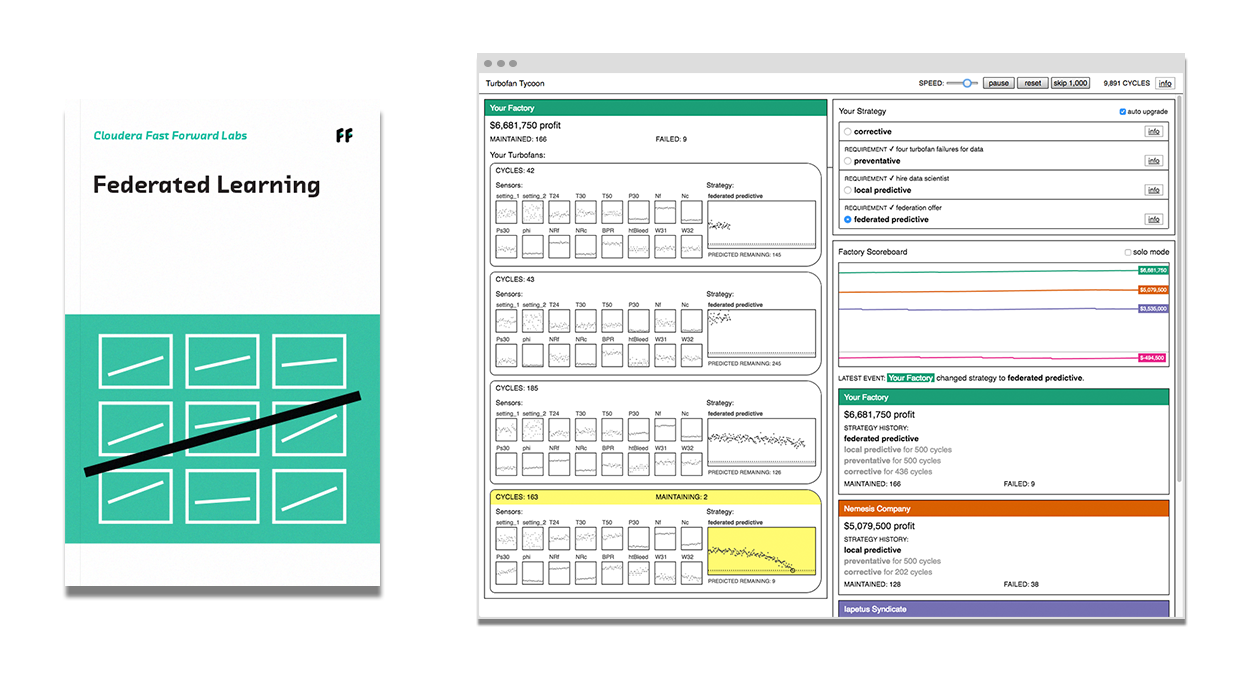
Federated Learning makes it possible to build machine learning systems without direct access to training data. The data remains in its original location, which helps to ensure privacy and reduces communication costs. Federated learning is a great fit for smartphones and edge hardware, healthcare and other privacy-sensitive use cases, and industrial applications such as predictive maintenance.
FF07
Semantic Recommendations

The internet has given us an avalanche of options for what to read, watch and buy. Because of this, recommendation algorithms, which find items that will interest a particular person, are more important than ever. In this report we explore recommendation systems that make use of the semantic content of items and users to deliver richer recommendations across multiple industries.
FF04
Summarization

This report explores methods for extractive summarization, a capability that allows one to automatically summarize documents. This technique has a wealth of applications: from the ability to distill thousands of product reviews, extract the most important content from long news articles, or automatically cluster customer bios into personas.
FF03-2019
Deep Learning for Image Analysis: 2019 Edition
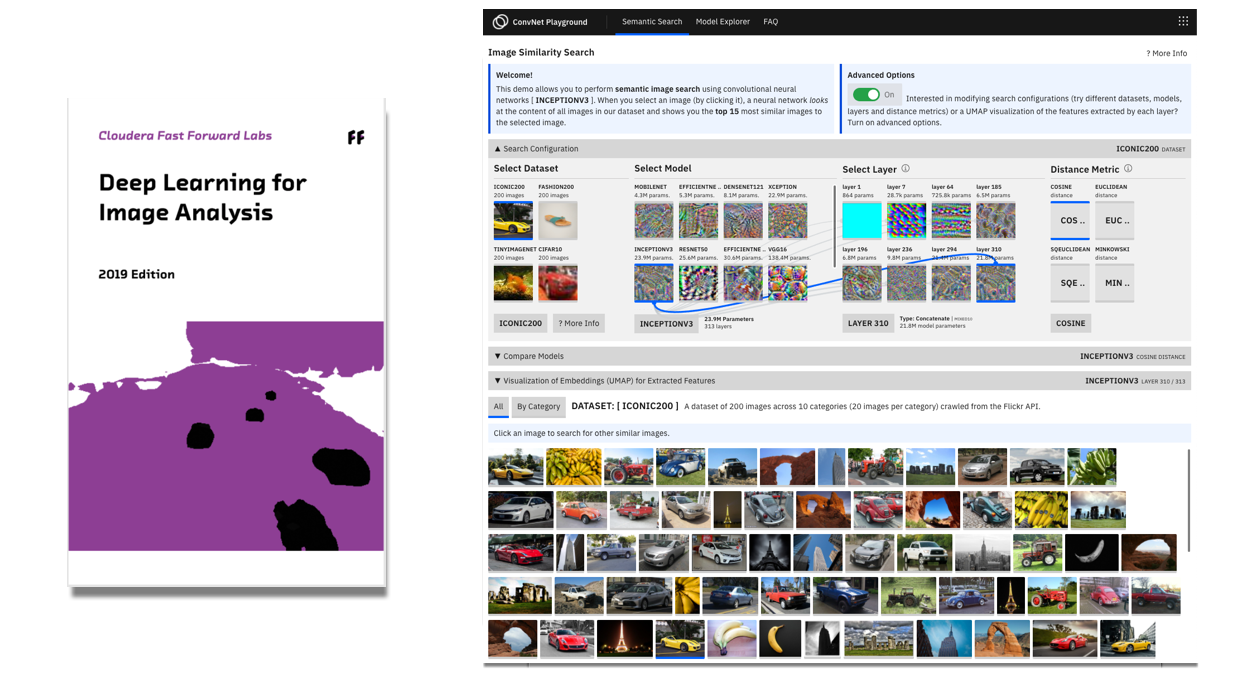
Convolutional Neural Networks (CNN) excel at learning meaningful representations of features and concepts within images. These capabilities make CNNs extremely valuable for solving problems in domains such as medical imaging, autonomous driving, manufacturing, robotics, and urban planning. In this report, we show how to select the right deep learning models for image analysis tasks and techniques for debugging deep learning models.
FF03
Deep Learning: Image Analysis
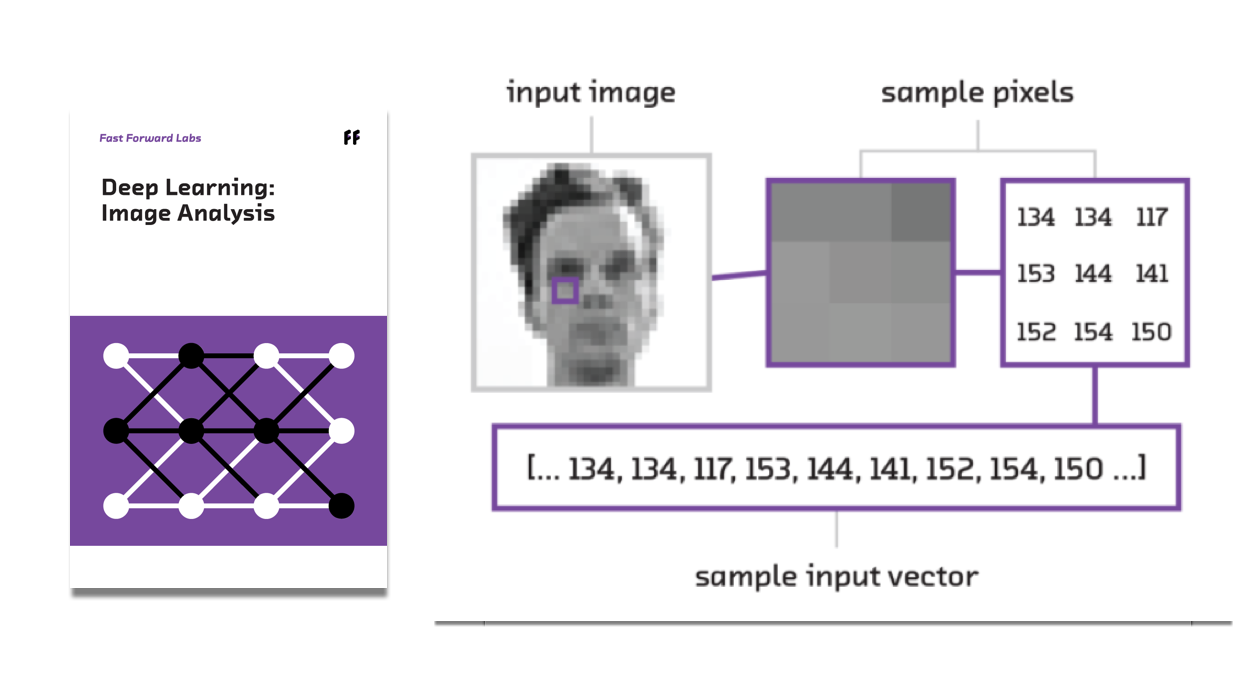
Deep learning, or highly-connected neural networks, offers fascinating new capabilities for image analysis. Using deep learning, computers can now learn to identify objects in images. This report explores the history and current state of the field, predicts future developments, and explains how to apply deep learning today.
FF02
Probabilistic Methods for Realtime Streams
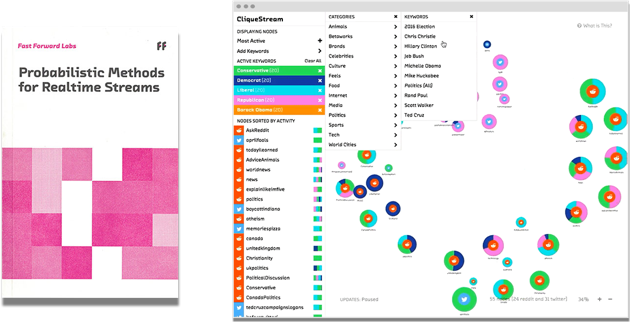
Since the days of analog computers built on cams and gears, we’ve been engineering systems around the flow of data and the critical calculations we must perform. While the philosophy of our designs has remained consistent, our engineering constraints are constantly evolving. In the past five years we’ve seen the emergence of “big data,” or the ability to use commodity infrastructure to analyze very large data sets in a batch. We’re currently in the midst of a significant step forward in the tools, methods, and technologies available for working with realtime streams of data.
Cloudera Fast Forward Labs
Making the recently possible useful.
Cloudera Fast Forward Labs is an applied machine learning research group. Our mission is to empower enterprise data science practitioners to apply emergent academic research to production machine learning use cases in practical and socially responsible ways, while also driving innovation through the Cloudera ecosystem. Our team brings thoughtful, creative, and diverse perspectives to deeply researched work. In this way, we strive to help organizations make the most of their ML investment as well as educate and inspire the broader machine learning and data science community.
Cloudera Blog Twitter©2022 Cloudera, Inc. All rights reserved.