Dec 8, 2016 · post
Dimensionality Reduction and Intuition

“I call our world Flatland, not because we call it so, but to make its nature clearer to you, my happy readers, who are privileged to live in Space.”
So reads the first sentence of Edwin Abbott Abbott’s 1884 work of science fiction and social satire, Flatland: A Romance of Many Dimensions. At the time, Abbott used contemporary developments in the fields of geometry and topology (he was a contemporary of Poincaré) to illustrate the rigid social hierarchies in Victorian England. A century later, with machine learning algorithms playing an increasingly prominent role in our daily lives, Abbott’s play on the conceptual leaps required to cross dimensions is relevant again. This time, however, the dimensionality shifts lie not between two human social classes, but between the domains of human reasoning and intuition and machine reasoning and computation.
Much of the recent excitement around artificial intelligence stems from the fact that computers are newly able to process data historically too complex to analyze. At Fast Forward Labs, we’ve been excited by new capabilities to use computers to perceive objects in images, extract the most important sentences from long bodies of text, and translate between languages. But making complex data like images or text tractable for machines involves representing the data in high-dimensional vectors, long strings of numbers that encode the complexity of pixel clusters or relationships between words. The problem is these vectors become so large that it’s hard for humans to make sense of them: plotting them often requires a space of way more than the three dimensions we live in and perceive!
On the other hand, machine learning techniques that entirely remove humans from the loop, like automatic machine learning and unsupervised learning, are still active areas of research. For now, machines perform best when nudged by humans. And that means we need a way to reverse engineer the high-dimensionality vectors machines compute in back down to the two and three dimensional spaces our visual systems have evolved to make sense of.
What follows is a brief survey of some tools available to reduce and visualize high-dimensional data. Send us a note at contact@fastforwardlabs.com if you know of others!
Google’s Embedding Projector
Yesterday, Google open-sourced the Embedding Projector, a web application for interactive visualization and analysis of high-dimensional data that is part of TensorFlow. The release highlights how the tool helps researchers navigate embeddings, or mathematical vector representations of data, which have proved useful for tasks like natural language processing. A popular example is to use embeddings to do “algebra” on words, using the space between vectors as a proxy for semantic relationships like man:king::woman:queen. Embedding Projector includes a few dimensionality reduction techniques like Principal Component Analysis (PCA) and t-SNE. Here’s an example of using PCA on an image data set (done before Google’s release).
t-SNE
t-Distributed Stochastic Neighbor Embedding (t-SNE) is an increasingly popular non-linear dimensionality reduction technique useful for exploring local neighborhoods and finding clusters in data. As explained in this post, t-SNE algorithms adapt transformations to the structure of the input data they work on, and have a tuneable parameter called “perplexity” that “says (loosely) how to balance attention between local and global aspects of your data.” While the algorithms are powerful, their output representations must be read with care, as the perplexity parameter can create confusion.

Visualization of how distance between clusters vary widely under different parameters on a t-SNE algorithm.
Mike Tyka, a machine learning artist, has used t-SNE to cluster images per similarity in Deep Dream’s neural network architecture. The resulting “map” reveals some interesting conclusions, showing, for example, that Deep Dream clusters violins near trombones. As the shapes of these two instruments differ to our eyes, their proximity in the neural network space may mean that Deep Dream uses the context of “people playing instruments” as a discriminatory feature for classification.
Topological Data Analysis
Palo Alto-based Ayasdi uses theory from topology, the study of geometrical properties that stay constant even when shapes are transformed, to help humans find patterns in large data sets. As CEO Gurjeet Singh explains in this O’Reilly interview, the two key benefits of using topology for machine learning are:
- The ability to combine results from different machine learning algorithms, while still maintaining guarantees about the underlying shapes or distributions
- The ability to discover the underlying shape of data so you don’t assume it and, thereby, impact the parameters for an optimization problem
Ayasdi’s product visualizes relationships in data as graphs, enabling users to visually perceive relationships that would be hard to uncover in the language of formal equations. We love the parallel insight that we, as humans, excel at what topologists call “deformation invariance,” the property that the letter A is still the letter A in different fonts.
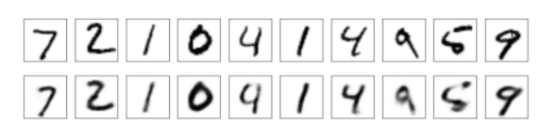
Machines using an autoencoder to reconstruct digits with moderate deformation invariance, as we explained in this blog post.
Data Visualization for the 3-D Web
Finally, Datavized is working on a data analytics tool fit for the 3-D web. While they’ve yet to work on dimensionality reduction, they have embarked on projects to give consumers of data a more empathic, first-person interpretation of statistics and conclusions. We look forward to the release of their product in 2017!
Conclusion
Our ability to represent rich, complex data, like images and text, in numbers required for mathematical functions on computers requires a Mephistophelean deal with the devil. These high-dimensional vectors are impossible to understand and interpret. But there’s been great progress in dimensionality reduction and visualization tools that enable us, in our Flatland, to make sense of the strange, cold world of machine intelligence.
- Kathryn









