Jan 11, 2017 · interview
Thomas Wiecki on Probabilistic Programming with PyMC3
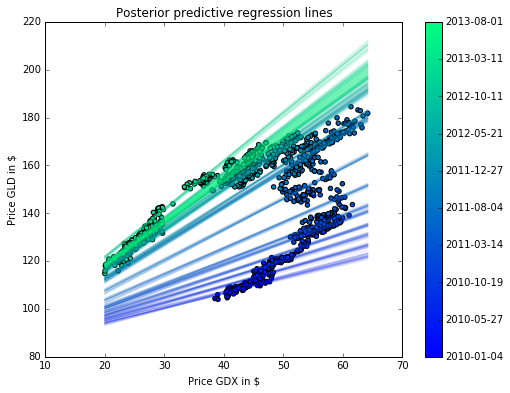
A rolling regression with PyMC3: instead of the regression coefficients being constant over time (the points are daily stock prices of 2 stocks), this model assumes they follow a random-walk and can thus slowly adapt them over time to fit the data best.
Probabilistic programming is coming of age. While normal programming languages denote procedures, probabilistic programming languages denote models and perform inference on these models. Users write code to specify a model for their data, and the languages run sampling algorithms across probability distributions to output answers with confidence rates and levels of uncertainty across a full distribution. These languages, in turn, open up a whole range of analytical possibilities that have historically been too hard to implement in commercial products.
One sector where probabilistic programming will likely have significant impact is financial services. Be it when predicting future market behavior or loan defaults, when analyzing individual credit patterns or anomalies that might indicate fraud, financial services organizations live and breathe risk. In that world, a tool that makes it easy and fast to predict future scenarios while quantifying uncertainty could have tremendous impact. That’s why Thomas Wiecki, Director of Data Science for the crowdsourced investment management firm Quantopian, is so excited about probabilistic programming and the new release of PyMC3 3.0.
We interviewed Dr. Wiecki to get his thoughts on why probabilistic programming is taking off now and why he thinks it’s important. Check out his blog, and keep reading for highlights!
A key benefit of probabilistic programming is that it makes it easier to construct and fit Bayesian inference models. You have a history working with Bayesian methods in your doctoral work on cognition and psychiatry. How did you use them?
One of the main problems in psychiatry today is that disorders like depression or schizophrenia are diagnosed based purely on subjective reporting of symptoms, not biological traits you can measure. By way of comparison, imagine if a cardiologist were to prescribe heart medication based on answers you gave in a questionnaire! Even the categories used to diagnose depression aren’t that valid, as two patients may have completely different symptoms, caused by different underlying biological mechanisms, but both fall under the broad category “depressed.” My thesis tried to change that by identifying differences in cognitive function – rather than reported symptoms – to diagnose psychiatric diseases. Towards that goal, we used computational models of the brain, estimated in a Bayesian framework, to try to measure cognitive function. Once we had accurate measures of cognitive function, we used machine learning to train classifiers to predict whether individuals were suffering from certain psychiatric or neurological disorders. The ultimate goal was to replace disease categories based on subjective descriptions of symptoms with objectively measurable cognitive function. This new field of research is generally known as computational psychiatry, and is starting to take root in industries like pharmaceuticals to test the efficacy of new drugs.
What exactly was Bayesian about your approach?
We mainly used it to get accurate fits of our models to behavior. Bayesian methods are especially powerful when there is hierarchical structure in data. In computational psychiatry, individual subjects either belong to a healthy group or a group with psychiatric disease. In terms of cognitive function, individuals are likely to share similarities with other members of their group. Including these groupings into a hierarchical model gave more powerful and informed estimates about individual subjects so we could make better and more confident predictions with less data.
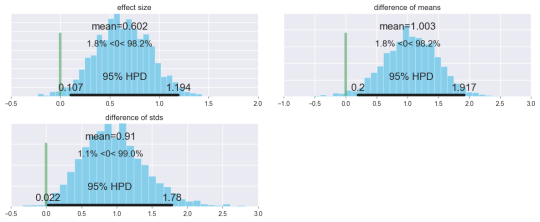
Bayesian inference provides robust means to test hypotheses by estimating how different two different groups are from one another.
How did you go from computational psychiatry to data science at Quantopian?
I started working part-time at Quantopian during my PhD and just loved the process of building an actual product and solving really difficult applied problems. After I finished my PhD, it was an easy decision to come on full-time and lead the data science efforts there. Quantopian is a community of over 100.000 scientists, developers, students, and finance professionals interested in algorithmic trading. We provide all the tools and data necessary to build state-of-the-art trading algorithms. As a company, we try to identify the most promising algorithms and work with the authors to license them for our upcoming fund, which will launch later this year. The authors retain the IP of their strategy and get a share of the net profits.
What’s one challenging data science problem you face at Quantopian?
Identifying the best strategies is a really interesting data science problem because people often overfit their strategies to historical data. A lot of strategies thus often look great historically but falter when actually used to trade with real money. As such, we let strategies bake in the oven a bit and accumulate out-of-sample data that the author of the strategy did not have access to, simply because it hadn’t happened yet when the strategy was conceived. We want to wait long enough to gain confidence, but not so long that strategies lose their edge. Probabilistic programming allows us to track uncertainty over time, informing us when we’ve waited long enough to have confidence that the strategy is actually viable and what level of risk we take on when investing in it.
It’s tricky to understand probabilistic programming when you first encounter it. How would you define it?
Probabilistic programming allows you to flexibly construct and fit Bayesian models in computer code. These models are generative: they relate unobservable causes to observable data, to simulate how we believe data is created in the real world. This is actually a very intuitive way to express how you think about a dataset and formulate specific questions. We start by specifying a model, something like “this data fits into a normal distribution”. Then, we run flexible estimation algorithms, like Markov Chain Monte Carlo (MCMC), to sample from the “posterior”, the distribution updated in light of our real-world data, which quantifies our belief into the most likely causes underlying the data. The key with probabilistic programming is that model construction and inference are almost completely independent. It used to be that those two were inherently tied together so you had to do a lot of math in order to fit a given model. Probabilistic programming can estimate almost any model you dream up which provides the data scientist with a lot of flexibility to iterate quickly on new models that might describe the data even better. Finally, because we operate in a Bayesian framework, the models rest on a very well thought out statistical foundation that handles uncertainty in a principled way.
Much of the math behind Bayesian inference and statistical sampling techniques like MCMC is not new, but probabilistic tooling is. Why is this taking off now?
There are mainly three reasons why probabilistic programming is more viable today than it was in the past. First is simply the increase in compute power, as these MCMC samplers are quite costly to run. Secondly, there have been theoretical advances in the sampling algorithms themselves, especially a new class called Hamiltonian Monte Carlo samplers. These are much more powerful and efficient in how they sample data, allowing us to fit highly complex models. Instead of sampling at random, Hamiltonian samplers use the gradient of the model to focus sampling on high probability areas. By contrast, older packages like BUGS could not compute gradients. Finally, the third required piece was software using automatic differentiation – an automatic procedure to compute gradients on arbitrary models.
What are the skills required to use probabilistic programming? Can any data scientist get started today or are there prerequisites?
Probabilistic programming is like statistics for hackers. It used to be that even basic statistical modeling required a lot of fancy math. We also used to have to sacrifice the ability to really map the complexity in data to make models that were tractable, but just too simple. For example, with probabilistic programming we don’t have to do something like assume our data is normally distributed just to make our model tractable. This assumption is everywhere because it’s mathematically convenient, but no real-world data looks like this! Probabilistic programming enables us to capture these complex distributions. The required skills are the ability to code in a language like Python and a basic knowledge of probability to be able to state your model. There are also a lot of great resources out there to get started, like Bayesian Analysis with Python, Bayesian Methods for Hackers, and of course the soon-to-be-released Fast Forward Labs report!

Congratulations on the new release of PyMC3! What differentiates PyMC3 from other probabilistic programming languages? What kinds of problems does it solve best? What are its limitations?
Thanks, we are really excited to finally release it, as PyMC3 has been under continuous development for the last 5 years! Stan and PyMC3 are among the current state-of-the-art probabilistic programming frameworks. The main difference is that Stan requires you to write models in a custom language, while PyMC3 models are pure Python code. This makes model specification, interaction, and deployment easier and more direct. In addition to advanced Hamiltonian Monte Carlo samplers, PyMC3 also features streaming variational inference, which allows for very fast model estimation on large data sets as we fit a distribution to the posterior, rather than trying to sample from it. In version 3.1, we plan to support more variational inference algorithms and GPUs, which will make things go even faster!
For which applications is probabilistic programming the right tool? For which is it the wrong tool?
If you only care about pure prediction accuracy, probabilistic programming is probably the wrong tool. However, if you want to gain insight into your data, probabilistic programming allows you to build causal models with high interpretability. This is especially relevant in the sciences and in regulated sectors like healthcare, where predictions have to be justified and can’t just come from a black-box. Another benefit is that because we are in a Bayesian framework, we get uncertainty in our parameters and in our predictions, which is important for areas where we make high-stakes decisions under very noisy conditions, like in finance. Also, if you have prior information about a domain you can very directly build this into the model. For example, let’s say you wanted to estimate the risk of diabetes from a dataset. There are many things we already know even without looking at the data, like that high blood sugar increases that risk dramatically – we can build that into the model by using an informed prior, something that’s not possible with most machine learning algorithms.
Finally, hierarchical models are very powerful, but often underappreciated. A lot of data sets have an inherent hierarchical structure. For example, take individual preferences of users on a fashion website. Each individual has unique tastes, but often shares tastes with similar users. For example, people are more likely to have similar taste if they have the same sex, or are in the same age group, or live in the same city, state, or country. Such a model can leverage what it has learned from other group members and apply it back to an individual, leading to much more accurate predictions, even in the case where we might only have few data points per individual (which can lead to cold start problems in collaborative filtering). These hierarchies exist everywhere but are all too rarely taken into account properly. Probabilistic programming is the perfect framework to construct and fit hierarchical models.
Interpretability is certainly an issue with deep neural nets, which also require far more data than Bayesian models to train. Do you think Bayesian methods will be important for the future of deep learning?
Yes, and it’s a very exciting area! As we’re able to specify and estimate deep nets or other machine learning methods in probabilistic programming, it could really become a lingua franca that removes the barrier between statistics and machine learning, giving a common tool to do both. One thing that’s great about PyMC3 is that the underlying library is Theano, which was originally developed for deep learning. Theano helps bridge these two areas, combining the power nets have to extract latent representations out of high-dimensional data with variational inference algorithms to estimate models in a Bayesian framework. Bayesian deep learning is hot right now, so much so that NIPS offered a day-long workshop. I’ve also written about the benefits in this post and this post, explaining how Bayesian methods provide more rigor around the uncertainty and estimations of deep net predictions and provides better simulations. Finally, Bayesian Deep Learning will also allow to build exciting new architectures, like Hierarchical Bayesian Deep Networks that are useful for transfer learning. A bit like the work you did to get stronger results from Pictograph using the Wordnet hierarchy.
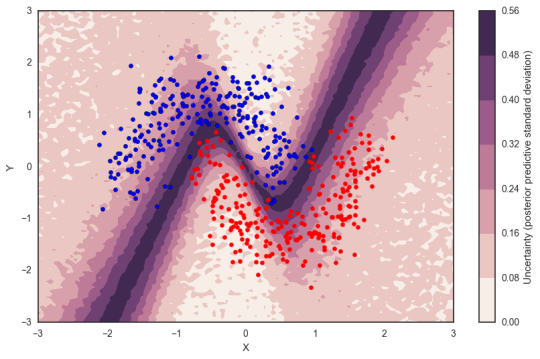
Bayesian deep nets provide greater insight into the uncertainty around predicted values at a given point. Read more here.
What books, papers, and people have had the greatest influence on you and your career?
I love Dan Simmons’ Hyperion Cantos series, which got me hooked on science fiction. Michael Frank (my PhD advisor) and EJ Wagenmakers first introduced me to Bayesian statistics. The Stan guys, who developed the NUTS sampler and black-box variational inference, have had a huge influence on PyMC3. They continue to push the boundaries of applied Bayesian statistics. I also really like the work coming out of the labs of David Blei and Max Welling. We hope that PyMC3 will also be an influential tool on the productivity and capabilities on data scientists across the world.
How do you think data and AI will change the financial services industry over the next few years? What should all hedge fund managers know?
I think it’s already had a big impact on finance! And as the mountains of data continue to grow, so will the advantage computers have over humans in their ability to combine and extract information out of that data. Data scientists, with their ability to pull that data together and build the predictive models will be the center of attention. That is really at the core of what we’re doing at Quantopian. We believe that by giving people everywhere on earth a platform that’s state-of-the-art for free we can find that talent before anyone else can.









