Apr 25, 2018 · newsletter
Simple Architectures Outperform Complex Ones in Language Modeling
Are novel, complex, and specialized neural network architectures always better for language modeling? Recent papers have shown otherwise. Language models are used to predict the next token given the preceeding tokens. Most operate at word-level or character-level. Word-level models have large vocabulary sizes (how many words are there in the English language?) compared to character-level models (there are 26 letters in the English language). This means that character-level models require less memory. On the other hand, when processing a sentence, character-level models see a large number of tokens (each character is a token) compared to word-level models. A large number of tokens (long sequence) is harder for neural networks because of the vanishing gradients problem.
A paper by Salesforce research shows that a properly regulated vanilla recurrent neural network (LSTM or a cheaper counter part QRNN) can achieve state-of-the-art results on both character-level and word-level datasets. The architecture is simple: the model consists of a trainable embedding layer, one or more layers of stacked recurrent neural network, and a softmax classifier. The embedding and softmax classifier layers utilize tied weights, meaning that these two layers share the same weight. To speed up the model (slow because of large vocabulary sizes), a version of adaptive softmax extended to allow for tied weights is used. The network is regularized using DropConnect (generalization of DropOut where the weights, rather than nodes, are set to zero) on the recurrent hidden-to-hidden weight matrices to prevent overfitting on the recurrent connections. This regularization approach does not require any modifications to an RNN’s formulation and allows black box RNN implementations to be used. Black box implementations are preferred because they often run faster due to low-level hardware-specific optimizations.
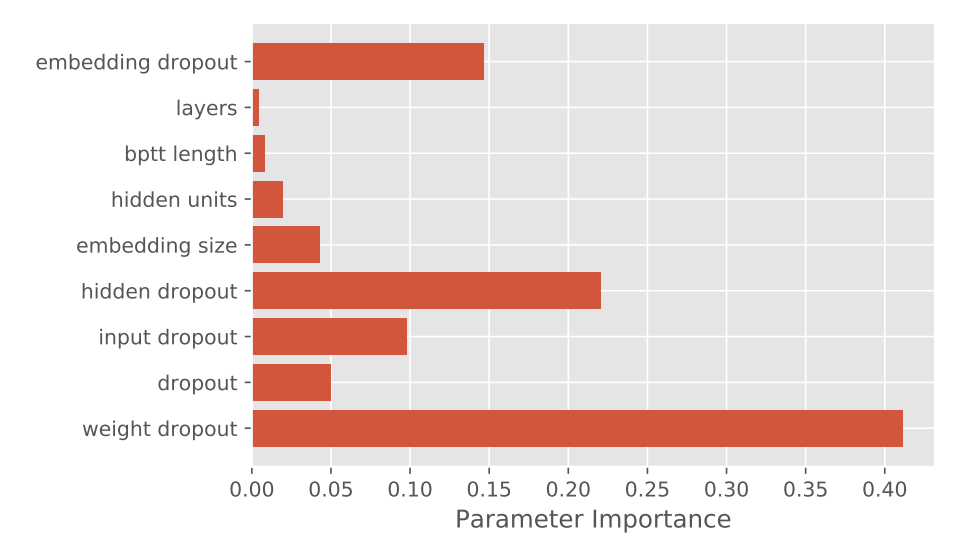
Relative importance of hyperparameters for word-level task on the smaller WikiText-2 dataset using QRNN (image source)
In addition to achieving state-of-the-art results, experiments with the above model show that QRNN is less successful than LSTM at character-level tasks, even with substantial hyperparameter tuning. QRNN combines the best of convolutional neural network (CNN) and recurrent neural network (RNN). It allows for parallel computation across both timestep and minibatch dimensions (CNN) while retaining sequential information (RNN). In doing so, it uses a simplified hidden-to-hidden transition function which is element-wise rather than full-matrix multiplication. The authors conjecture that this simplified transition function prevents full communication between hidden units in the RNN, making it less suitable for character-level language models. The experiments on QRNN also show that weight dropout is the most important hyperparameter - the number of layers and dimension sizes matters relatively less. We think the paper is interesting because it: i) confirms that novel and complex is not always better; ii) shows character-level and word-level models are not easily transferable; and iii) attempts to rank hyperparameter importance (useful!)









