Welcome to the March Cloudera Fast Forward Labs newsletter.
It’s been a busy month for us here in the virtual Fast Forward lab. Supporting our launch of Applied ML Prototypes (read more on the Cloudera blog: Change The Way You Do ML With Applied ML Prototypes), working on growing the team, and starting our first research cycle of 2021. More on that soon! We’re also excited to announce our latest hijinks:
Fast Forward Live!
On April 1st (no joke) at 9am PT/12pm ET/5pm BST we’re hosting our first ever live stream: Representation Learning for Software Engineers.
Good representations of data (e.g., text, images) are critical for solving many tasks (e.g., search or recommendations). But what exactly are representations, how can they be built and why are deep learning models useful? In this livestream, we will discuss these questions from a software engineering perspective and walk through a live example!
Since this is a livestream, there’s nowhere to register ahead of time. Just watch our social feeds and we’ll meet you there.
Recommended Reading
Our research engineers share what we’ve found interesting this month.
-
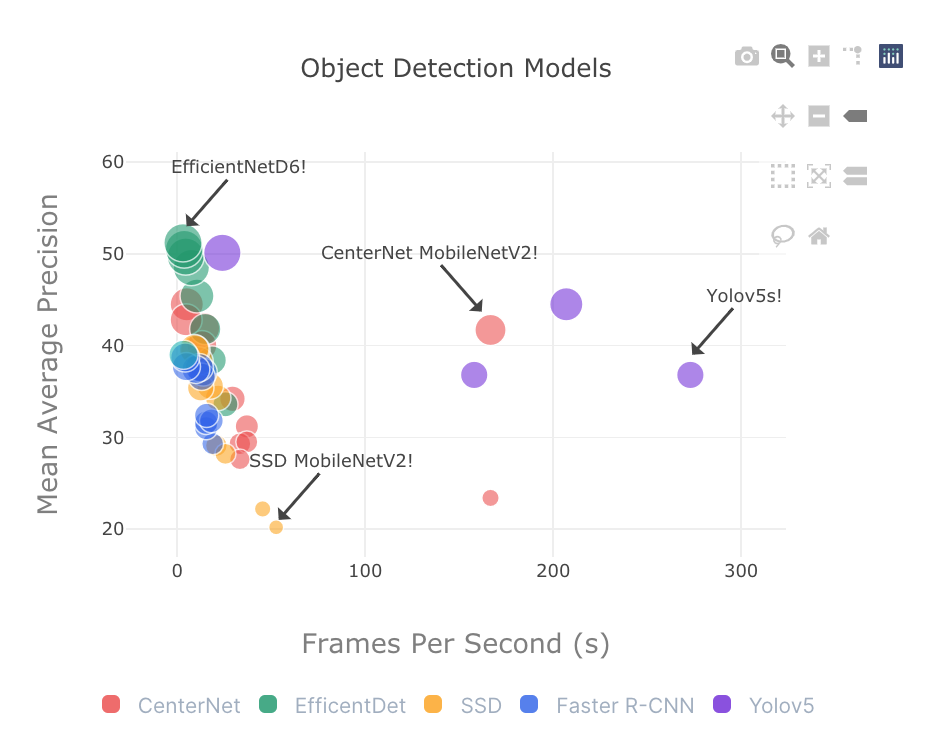
State of Practical Object Detection Models in 2021 - Why You Should Consider CenterNets If you have not looked at research advances in object detection, a few things have changed - especially for low latency applications. The rise of anchor-free approaches to single stage detection (e.g. ConerNets and CenterNets) have translated to increased speed and accuracy. For example, compared to MobileNet SSDV2 (previous low latency SOTA), CenterNets (keypoint version) provide 3.15x increase in speed, and 2.06x increase in performance (MAP). There have also been advances in Yolo - Yolov5 with similar speed/accuracy improvements. - Victor
-
Uber’s Journey Toward Better Data Culture from First Principles While organizational data practices may not stand out as the most exciting topic for machine learning enthusiasts, their importance in scaling data systems effectively cannot be overstated. In this article, Uber’s engineering team recounts the common pitfalls and lessons learned along their data first journey - emphasizing the importance of a holistic approach that extends beyond just the tools used to manage data and into the people and processes surrounding those tools. Prioritizing concepts like data as code, data discovery, and clear data ownership upfront in an organization’s data journey will save time and duplication of effort as data footprint scales. - Andrew
-
Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models Researchers from Stanford University and OpenAI got together last October and had a good long chat about extremely large language models, like GPT3. This informal paper serves as a summary of their discussion, which focused on a broad range of concerns under two main umbrellas: the technical limitations, and the societal impacts due to widespread adoption. It should be noted that this discussion explored the problems; the solutions remain to be developed. Furthermore, not all problems were addressed — for example, there was no mention of the considerable carbon footprint required to train large language models. Nevertheless, it’s encouraging to see the language model gatekeepers turn their attention to the potential consequences of the models they develop. - Melanie
-
2021 AI Index Report The Stanford Institute for Human-Centered AI has released its 2021 index. The report provides many data-backed insights and trends relating to artificial intelligence, ranging from the “brain drain” of AI PhDs into industry, to the increasing ubiquity of surveillance technology, to the state of AI ethics. For those who, like myself, do not have 200+ pages of reading time readily available for it, the report also lists its top nine takeaways (why nine? we may never know) in a single page. The report is well organised and each chapter contains a highlight section, so I recommend virtually leafing through to see what takes your interest. - Chris