Welcome to the August Cloudera Fast Forward Labs newsletter. This month, new research, a new webinar, and we welcomed Daniel, a new research engineer 🎉
New research! Inferring Concept Drift Without Labeled Data
After iterations of development and testing, deploying a well-fit machine learning model often feels like the final hurdle for an eager data science team. In practice however, a trained model is never final because the complex relationships that it abstracts are likely to evolve over time causing the model’s performance to deteriorate if not accounted for.
To combat this divergence between static models and dynamic environments, teams often adopt an adaptive learning strategy that is triggered by the detection of a drifting concept. This involves monitoring a performance metric of interest (such as accuracy) and alerting a retraining pipeline when the metric falls below some designated threshold. While this strategy proves to be effective, it requires immediate access to an abundance of labels at inference time in order to quantify a change in system performance - a requirement that may be cost prohibitive or outright impossible in many real-world machine learning applications.
Our latest research report focuses on approaches for dealing with concept drift when labeled data is not readily accessible. Check it out here: Inferring Concept Drift Without Labeled Data
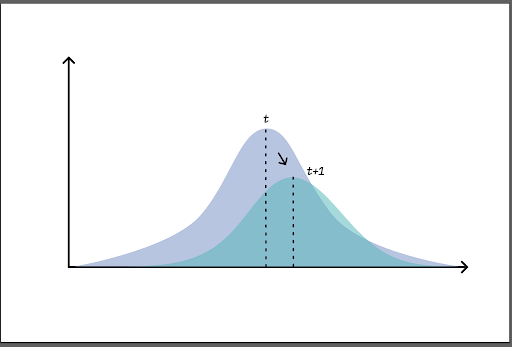
Changes in the statistical properties of a target domain are referred to as concept drift and will cause the predictive performance of a trained model to degrade over time, making it obsolete for the task it was initially intended to solve.
Fast Forward Live!
This month our research lead Chris recently joined the Head of Developer Relations at Streamlit, Randy Zwitch, to demonstrate building and hosting interactive web apps in Cloudera Machine Learning. Read more about Enterprise Data Science Workflows with AMPs and Streamlit and check out the Automating Sharable AI Web Apps with Streamlit and Cloudera webinar replay!
Our previous livestreams:
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended reading
Our research engineers share their favourite reads of the month:
-
Autopilot Network Design from Tesla AI Day
Tesla’s recent AI Day shaped up as more of a ML conference presentation rather than shareholder pitch. In the opening segment linked above, Tesla’s director of Autopilot Vision, Andrej Karpathy, shares the evolution of the company’s neural network design over the past four years. Andrej highlights the limitations of single-image inference networks for the task of full self-driving, and visually demonstrates the design journey the team has been on to arrive at the current architecture today - where predictions are made in a projected, multi-camera vector space and combined with temporal video features in near real-time. An inspiring glimpse into the innovative engineering feats that have shaped this developing ML capability. - Andrew
-
Deep Work, book by Cal Newport
It is refreshing to read a critique of technological trends by nothing less than a professor of computer science. In his book Deep Work, Cal Newport argues for the benefits of performing professional activities “in a state of distraction-free concentration that push your cognitive capabilities to their limit”. He defines “deep work” in this way, and argues that some of the technologies used in the work place can act as hindrances towards it. The first part of the book presents economic, psychological, neurological and philosophical reasons to do deep work. The second half discusses strategies that facilitate this modus operandi. The book is easy to read, enjoyable, and can be useful both in terms of motivation and strategies for deep work. Minor criticisms include weakness in some reasonings (e.g. the ‘winner-takes-all’ in the first chapter), shallowness, no pun intended, of philosophical explanations, and misnomers for the rules — which don’t seem to match their descriptions. Overall I’d recommend this book to everyone working in a knowledge-based economy. - Daniel
-
Fairness and Machine Learning: Limitations and Opportunities
This book-in-progress entered my radar early last year while I was working on Causality for Machine Learning. It will take me some time yet to read, but it does provide a pretty comprehensive introduction to fairness in machine learning. From atop my soapbox, I was pleased to find an entire chapter dedicated to Causality. I believe many disagreements about fairness in AI, especially among those who are not researching the subject, are rooted in participants having different causal models in their minds. The book provides enough causal background to express causal assumptions. However, fairness is a deep subject, and as Moritz Hardt (one of the authors) highlights in his MLSS2020 tutorial on Fairness, even causality does not resolve the question of “what is fair”. - Chris
-
Machine learning is going real-time I only recently came across this blog series by Chip Huyen (Snorkel AI, NVIDIA, Netflix, and Stanford Lecturer) but this post from late last year is my favorite. In it, she drops a massive knowledge bomb on all things Real-Time ML. From online inference to online learning, she breaks down the concepts, challenges, and solutions, including pointers on software tools that get the job done. As a researcher, I’m comfortable digging into academic papers, pouring over mathematical equations, and scouring code — but none of these things translates to the practical challenges inherent to real-time machine learning systems. If it’s new to you too, then this is a great place to start! - Melanie
-
Feature Stores and the Coming Wave of Embedding Ecosystems
Industrializing ML requires managing a ML pipeline which in turn involves iterating on model features, training, deployment and monitoring these models at scale. Feature Stores (FS) arose out of the need to address some of the challenges in each of these phases of the ML cycle. For instance, the need to have consistent feature definitions that are up-to-date as the data changes over time or aiding model reproducibility or some guidance on what features need to be corrected when faced with distributional shifts post model deployment. Primarily they serve as a centralized repository of reusable features across the ML pipeline and automate the management of this pipeline. In addition, some of the FSs support model provenance and reproducibility, online feature serving, model quality metrics and much more. That said, when it comes to embeddings FSs face some unique challenges and are unable to support end-to-end embedding management. While these self-supervised pre-trained embeddings are part of many products at large technology companies, the standard metrics and tools for managing tabular data are no longer adequate for them. For instance, just like tabular features embeddings get retrained and updated and thus affect downstream models. Any inherent embedding quality issue is hard isolate with the current FSs. The authors of this paper propose making embeddings a first class citizen of the FSs and suggest how they should evolve to provide a native support for them. However, as noted by the authors this could be tricky especially given the growing sizes of embeddings and their associated models. - Nisha
That’s all from us this month! Be excellent to each other ✌️