Welcome to the October Cloudera Fast Forward Labs newsletter. This month, some old research, and new recommended reading.
New (old) research!
This month, we’re opening the vault and releasing a report from back in April 2019 from behind the paywall.
Learning with Limited Labeled Data
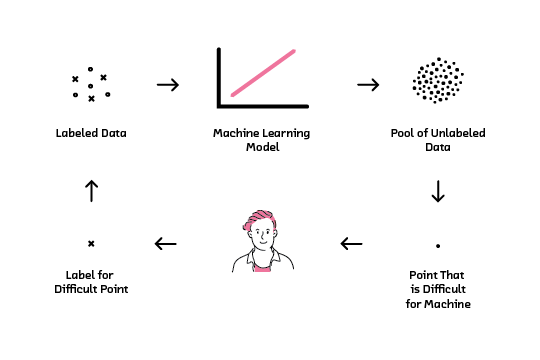
Being able to learn with limited labeled data relaxes the stringent labeled data requirement for supervised machine learning. This report focuses on active learning, a technique that relies on collaboration between machines and humans to label smartly. Active learning reduces the number of labeled examples required to train a model, saving time and money while obtaining comparable performance to models trained with much more data. With active learning, enterprises can leverage their large pool of unlabeled data to open up new product possibilities.
Fast Forward Live!
Check out replays of livestreams covering some of our research from this year.
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended reading
Our research engineers share their favourite reads of the month:
-
The 2021 Machine Learning, AI and Data (MAD) Landscape
In their 8th annual release, Matt Turck and John Wu of FirstMark Capital map out the machine learning, AI, and data (MAD) landscape of 2021 from an investors point of view. While funding is only one peg by which technological progress can be measured, there is much to be learned from macro investment trends. In this post, the authors present a well researched market map of startup, private, and public sector players in the MAD ecosystem broken down by market segment - including several key trends for 2021 including data mesh, dataOps, feature stores, the rise of MLOps, and AI content generation. A great resource to help track and make sense of the emerging data and ML space over time. - Andrew
-
Multitask Prompted Training Enables Zero-shot Task Generalization This is the first modeling paper from BigScience, a one-year-long research workshop on NLP consisting of members of HuggingFace, as well as 250 other research institutions from 50 countries! It’s well known that massive language models like T5 or GPT-3 generalize surprisingly well to new tasks. The leading hypothesis for this performance is that these models implicitly undergo multitask learning thanks to the massive corpora they are trained on. In this paper, researchers explicitly perform multitask training by first mapping a large set of supervised NLP datasets into a human-readable prompted format, which allows the model to learn multiple tasks with consistent inputs and outputs.
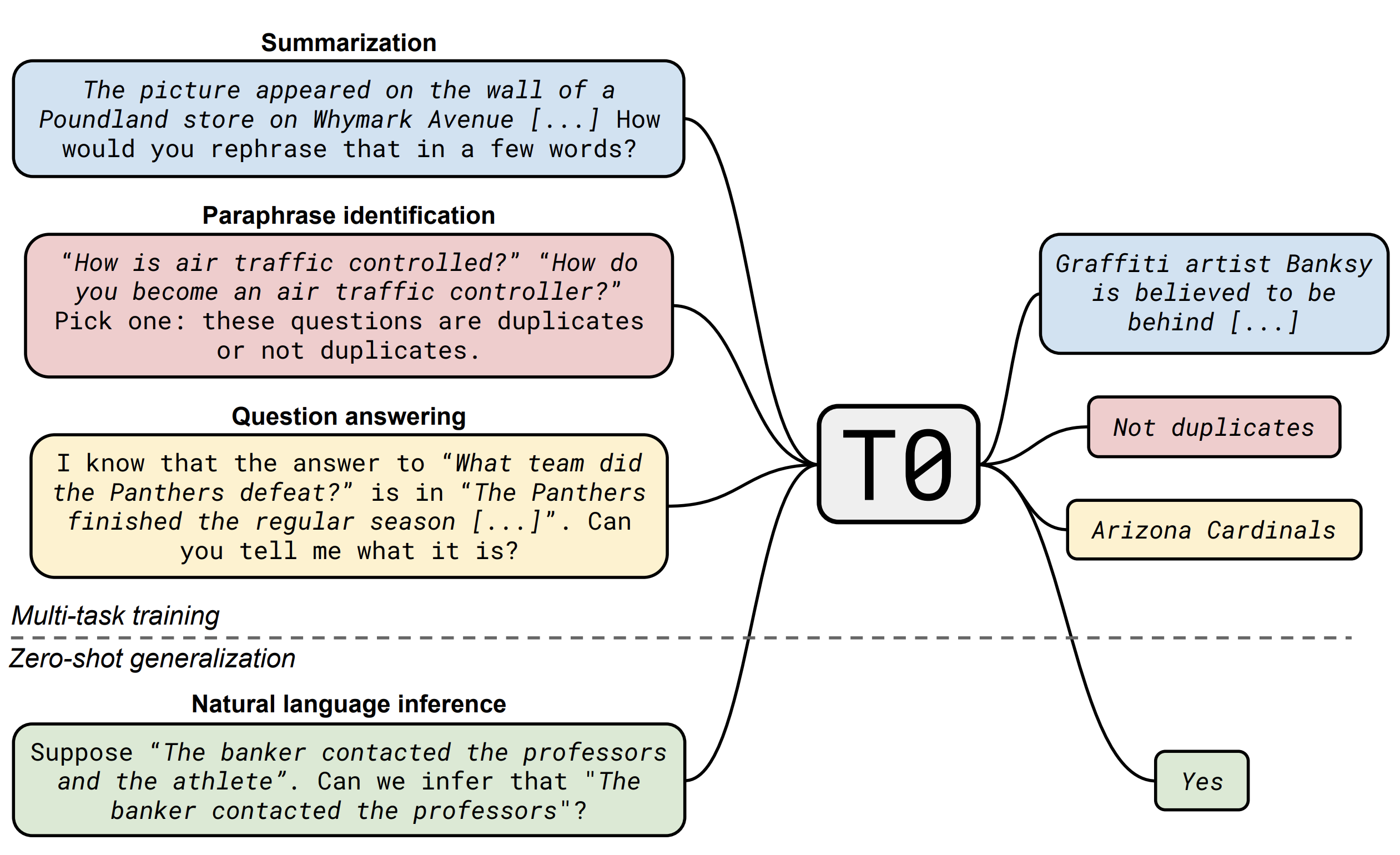
They train their model on several NLP capabilities (like summarization and question answering) and evaluate the zero-shot performance of the model on tasks it was not allowed to train on, like natural language inference. Their model outperforms GPT-3 on 8 out of 11 unseen datasets; all the more impressive since the largest GPT-3 model they compare against is 16x larger than their model! This paper demonstrates a way to gain the benefits of ultra-massive language models at a fraction of the cost: Their model has fewer parameters, is trained on a smaller dataset, and ultimately requires less computational time and energy. (Though, let’s be honest — it’s still a huge model. 😉) - Melanie
-
Self-Supervised Learning: The Dark Matter of Intelligence
The authors of this blog argue that self-supervision is one of the most promising ways to give AI systems a kind of “common sense”. If human common sense consists of prior knowledge that helps people solve a variety of problems with limited teaching, then AI common sense is the capacity of AI systems to learn to perform diverse tasks with limited amounts of human annotations. After explaining the basics of self-supervision, the authors discuss why it isn’t straightforward to apply to Computer Vision (CV) the methodologies that have proven successful in NLP: the reasons have to do with large dimensionality and the representation of uncertainty in CV. The last part of the blog argues that one of the most promising ways to advance self-supervision in CV is through the use of non-contrastive methods applied to joint embedding architectures. The blog is a good introduction to self-supervision, especially for people interested CV. - Daniel.
-
Declarative Machine Learning Systems
When it comes to operationalizing ML, Sculley et al. have well highlighted the idiosyncrasies that may lead to substantial increase in technical debt. The primary reason for these idiosyncrasies is the amount of uncertainty involved at every step in ML development, from feature engineering to model selection. To some extent both researchers and industry have managed to distill common patterns that abstract the most mechanical parts of the processes to help with wider ML adoption. Without tools like scikit-learn, PyTorch, TensorFlow and many others it would have been impossible to standardize and easily implement some of these processes. Despite all the successes, training models and using them in products generally belongs to a small subset of highly skilled people in an organization. This is where the authors of the paper propose that the future wave of ML Systems should leverage the extensive work done in compilers, operating systems and databases. For instance, just like a database management system hides all the complexity of data storage, indexing and retrieval behind a declarative query language, the future ML systems should steer towards hiding complexity and separation of interest to bring ML to non-coders. And although Auto-ML might seem as a promising direction, the authors suggest (and rightly so) that they are often centered around single steps of the pipeline, example, hyper-parameter tuning, feature engineering and such. The authors talk about the two declarative ML systems they have built - Ludwig and Overton and how they could be used to help with some of the current challenges that these ML systems are facing. Along the way they also cover the current ML processes and what factors contribute towards a successful ML project, what would lead to wider adoption and what they believe the next generation systems will look like. - Nisha
-
Learning in High Dimension Always Amounts to Extrapolation
I need to spend some more time with this paper, so this recommendation is mostly based on curiosity. I strongly recommend anyone reading this paper to also read Keras creator François Chollet’s excellent thread about interpolation in machine learning. My view of interpolation is as put forward in the thread: when we say interpolate, we mean on the latent manifold of the data, not the encoding dimension. MNIST, for instance, is a much lower dimensional dataset than natural images. However, this is not because it has fewer pixels (the encoding dimension). It is because the thing being represented (handwritten digits) is intrinsically lower dimensional than the space of all images of the world. The above paper provides empirical and theoretical evidence that for high dimensional datasets (it includes discussion of both encoding- and latent-space being high dimensional), almost any new test point will lie outside the convex hull of the training data. Since the volume of a convex hull decreases relative to the total volume as more dimensions are added, this is not surprising.
The paper seems designed to counter claims that ML only works when it is interpolating, but I am unconvinced. As far as I can tell, the work does not learn a representation from a dataset (to say, approximate the latent manifold) and assess the resulting model’s performance on images selected to be inside and outside the convex hull of that manifold, which would provide a much better test of extrapolation. In my own view, it’s obvious that ML will sometimes work in extrapolated regimes, but that when it does, it says more about the generative process of the data than a fundamental ability of neural nets. - Chris