December 2021
Welcome to the December edition of the Cloudera Fast Forward Labs newsletter. This month we dive into the world of Video Understanding and share our favorite reads.
New research!
For the past few months, we’ve been diligently digging into a newly-emerging capability: Video Understanding! While working with video data has considerable overlap with image understanding, information extraction from video presents a new level of complexity and a new world of possibilities.
An Introduction to Video Understanding: Capabilities and Applications
Video understanding is an umbrella term for a wide range of technologies that automatically extract information from video. Readers familiar with computer vision, as applied to still images, might wonder what the main differences between image and video processing are. Can’t we just apply still image algorithms to each frame of the video sequence, and extract meaning in that way? The short answer is “yes, but…”. While it is indeed possible to apply image methods to each frame in a video (and some approaches do), considering temporal dependencies results in tremendous gains of predictive capabilities. This blog post provides an introduction to a slew of these capabilities as well as some nascent applications that harness these technologies in the real world.
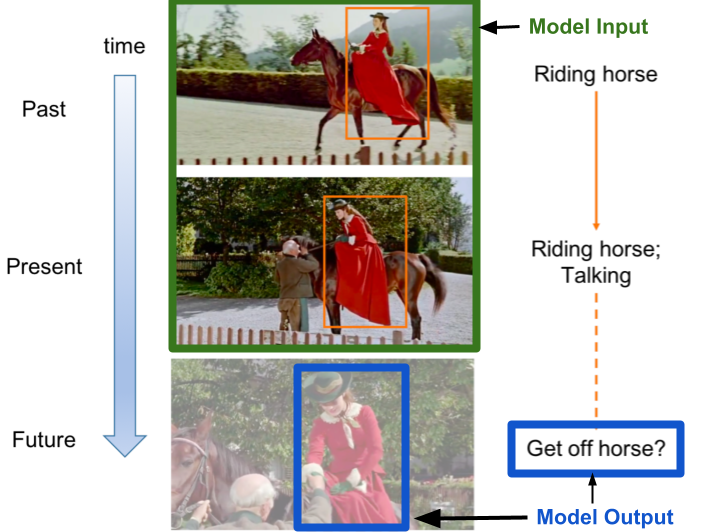
Action forecasting is just one emerging capability in the vast world of video understanding.
New Applied Machine Learning Prototypes!
Those familiar with our work know that here at CFFL, we don’t just write about the latest ML, we also love to build things with it! While our prototypes now live in Cloudera’s data science products, our repos are always intended for a broad audience. To that end, we thought it was high time that we added this section to our newsletter to highlight some of these projects. Here you’ll find links to repos we’re currently working on, as well as polished prototypes. Keep in mind that projects under development are subject to change, while finalized repos provide stable releases with long-term support.
Video Classification (under development)
This project accompanies the video understanding blog above and provides two ways to explore the specific task of video classification. The first is an interactive Jupyter Notebook that allows the user to investigate the data and models behind video classification, as well as to highlight some of the challenges and considerations of working with video data. The second is a script that allows the user to evaluate video classification models on a handful of standardized video datasets.
Continuous Model Monitoring (under development)
To combat concept drift in production systems, it’s important to have robust monitoring capabilities that alert stakeholders when relationships in the incoming data or model have changed. In this Applied Machine Learning Prototype (AMP), we demonstrate how this can be achieved on CML. Specifically, we leverage CML’s Model Metrics feature in combination with Evidently.ai‘s Data Drift, Numerical Target Drift, and Regression Performance reports to monitor a simulated production model that predicts housing prices over time.
Fast Forward Live!
Check out replays of livestreams covering some of our research from this year.
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended reading
Our research engineers share their favorite reads of the month:
-
Distilling large, complex topics into concise, easily digestible explanations truly is an art. In this excellent blog post, Brandon Rohrer does just that. By introducing fundamental concepts with visual examples and then stacking those ideas together as building blocks, Brandon helps the reader intuit not only how modern Transformers work, but also why design choices were made to reach the ultimate architecture. This is one of the best resources I’ve come across on the topic. -Andrew
-
PolyViT: Co-training Vision Transformers on Images, Videos and Audio
The authors of this paper open with a question: Can we train a single transformer model capable of processing multiple modalities and datasets, whilst sharing almost all of its learnable parameters?
And apparently, the answer is yes.
This paper, a collaboration by teams from Google Research, University of Cambridge, and the Alan Turing Institute, combines Vision Transformers (ViT) with the technique of co-training to produce the PolyViT model which can perform image, audio, and video classification!
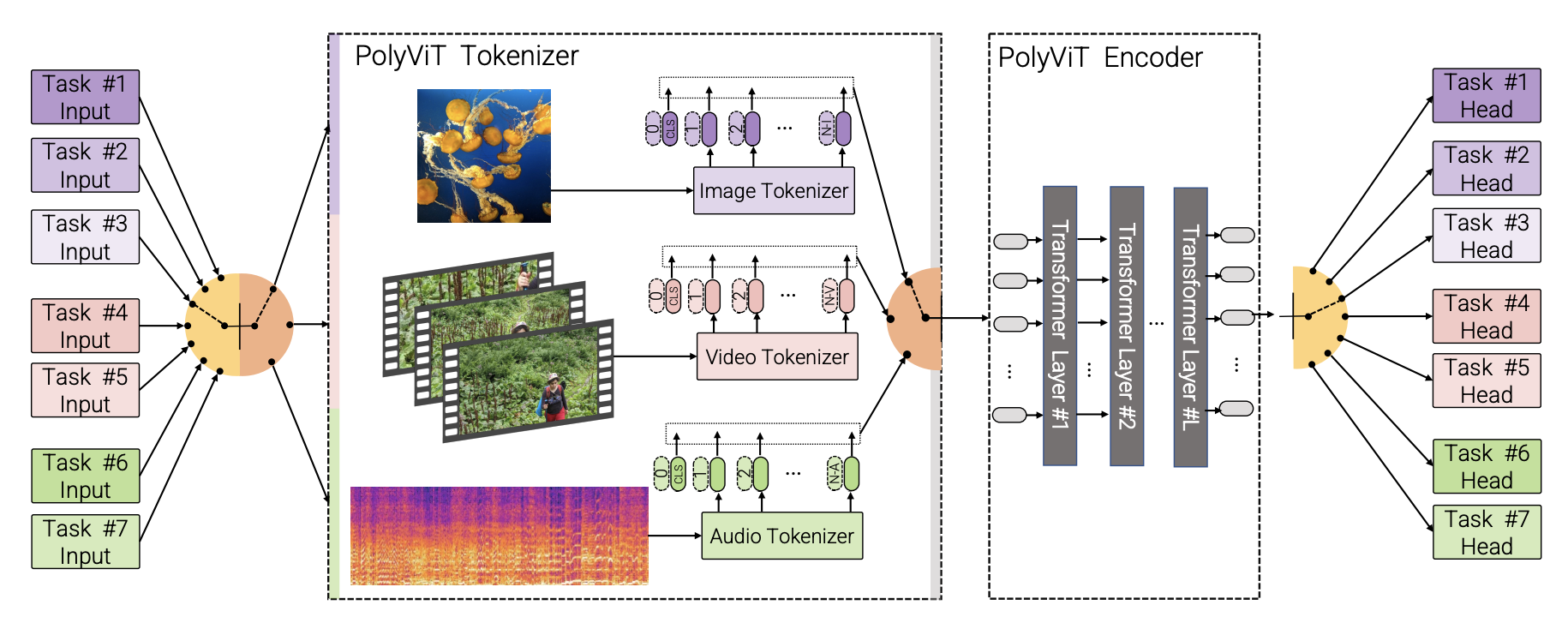
They accomplish this by training a single ViT architecture to accept multiple input tasks and to predict on multiple output classification heads. This allows a single model’s learned parameters to be used for multiple modalities — image, audio, and video. The success of their model hinges largely on the specific co-training methodology employed, and the paper does a good job explaining the various strategies they experimented with. While their model can only perform a single task at a time (it cannot combine audio and video, for example), this work represents a big step forward for models that can generalize not only to new datasets but also to entirely new tasks! - Melanie