August 2022
Welcome to the August edition of the Cloudera Fast Forward Labs newsletter. This month we’re thrilled to introduce a new member of the FFL team, share TWO new applied machine learning prototypes we’ve built, and, as always, offer up some intriguing reads.
New Research Engineer!
If you’re a regular reader of our newsletter, you likely noticed that we’ve been searching for new research engineers to join the Cloudera Fast Forward Labs team. This month we’re thrilled to introduce the Mike Gallaspy!
Michael Gallaspy has approved the release of the following vital details:
- I live and die by one immutable rule: stay cool.
- I hail from the harsh desert planet of Las Vegas.
- My preferred form of communication is sketching.
- My favorite album right now is All Hail West Texas by the Mountain Goats.
- My favorite food today is yogurt.
A picture is worth one thousand words, so please enjoy the following self portrait:

He has a great recommended reading suggestion toward the bottom of this newsletter and you’ll be hearing more from him in the near future.
New Applied ML Prototypes!
This month we have some new projects to share. These prototypes are now included in the Cloudera Machine Learning AMP catalog and they demonstrate several features of the platform. However these repos are open source and you can explore many aspects of them on your own laptop!
Distributed XGBoost with Dask on CML
In this Applied ML Prototype, we go beyond what we can achieve with a single laptop and use the Cloudera Machine Learning Workers API to spin up an on-demand Dask cluster to distribute the training of an XGBoost model for a credit card fraud detection use case.
This Jupyter Notebook AMP demonstrates a scenario in which the data is larger than can comfortably fit into memory and must instead be distributed across the nodes of your cluster. This necessitates distributing your ML model across those same nodes, a feature of ensemble models like XGBoost. This sets us up for machine learning at scale!
Exploring Intelligent Writing Assistance
This prototype provides a demonstration of how the NLP task of text style transfer can enhance the human writing experience using HuggingFace Transformers and Streamlit. Specifically, this project peels back the curtains on how an intelligent writing assistant might function — walking through the logical steps needed to automatically re-style a piece of text (from informal-to-formal or subjective-to-neutral) — while building up confidence in the model output.
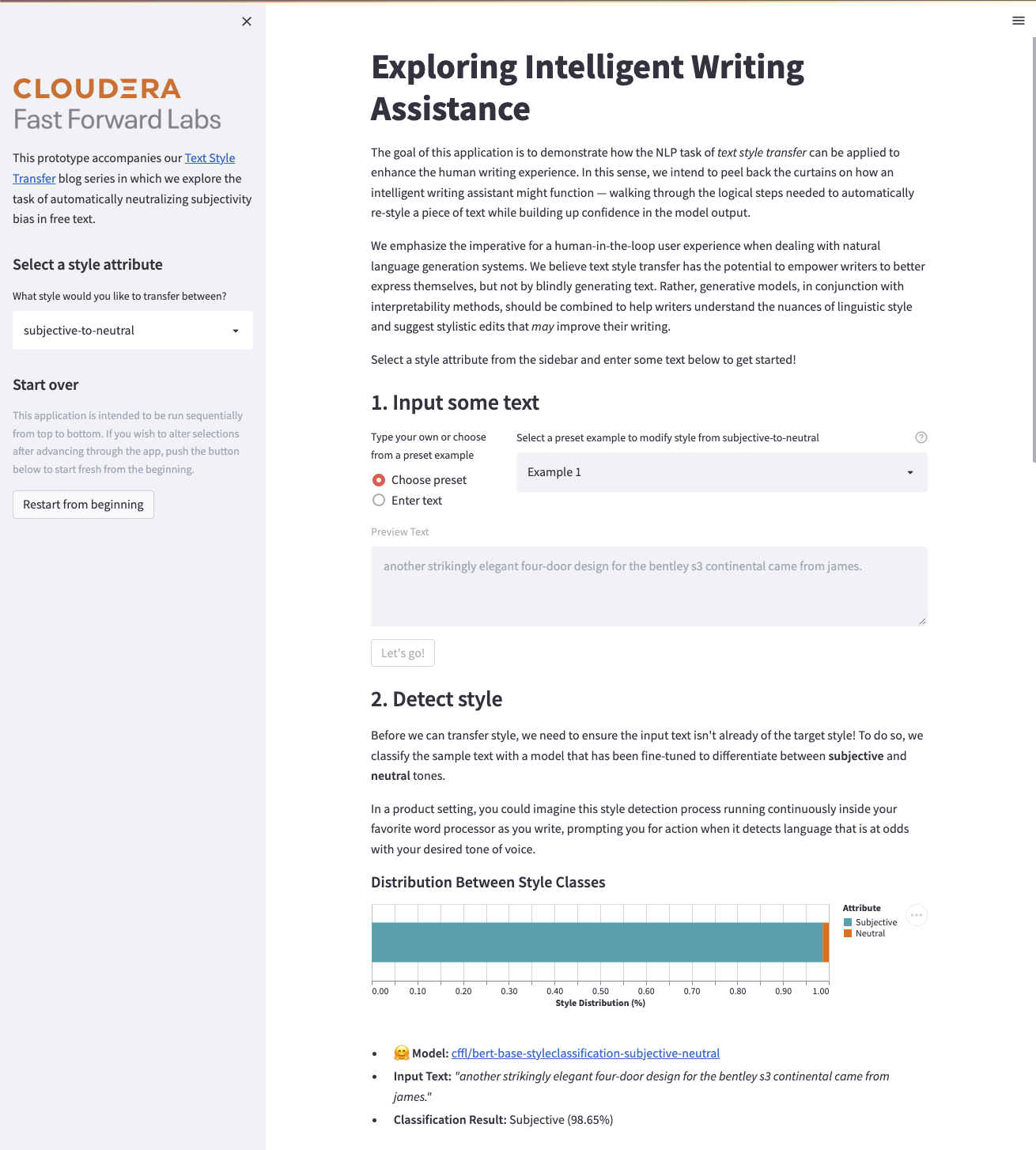
CFFL is now on HuggingFace!
Our recent exploration into the natural language processing task of text style transfer was an incredibly fruitful endeavor and we wanted to ensure that others could benefit from our experience, which is why we created the Applied Machine Learning Prototype above. While you can take this prototype for a spin on CML or even on your own laptop, we wanted to make it even easier!
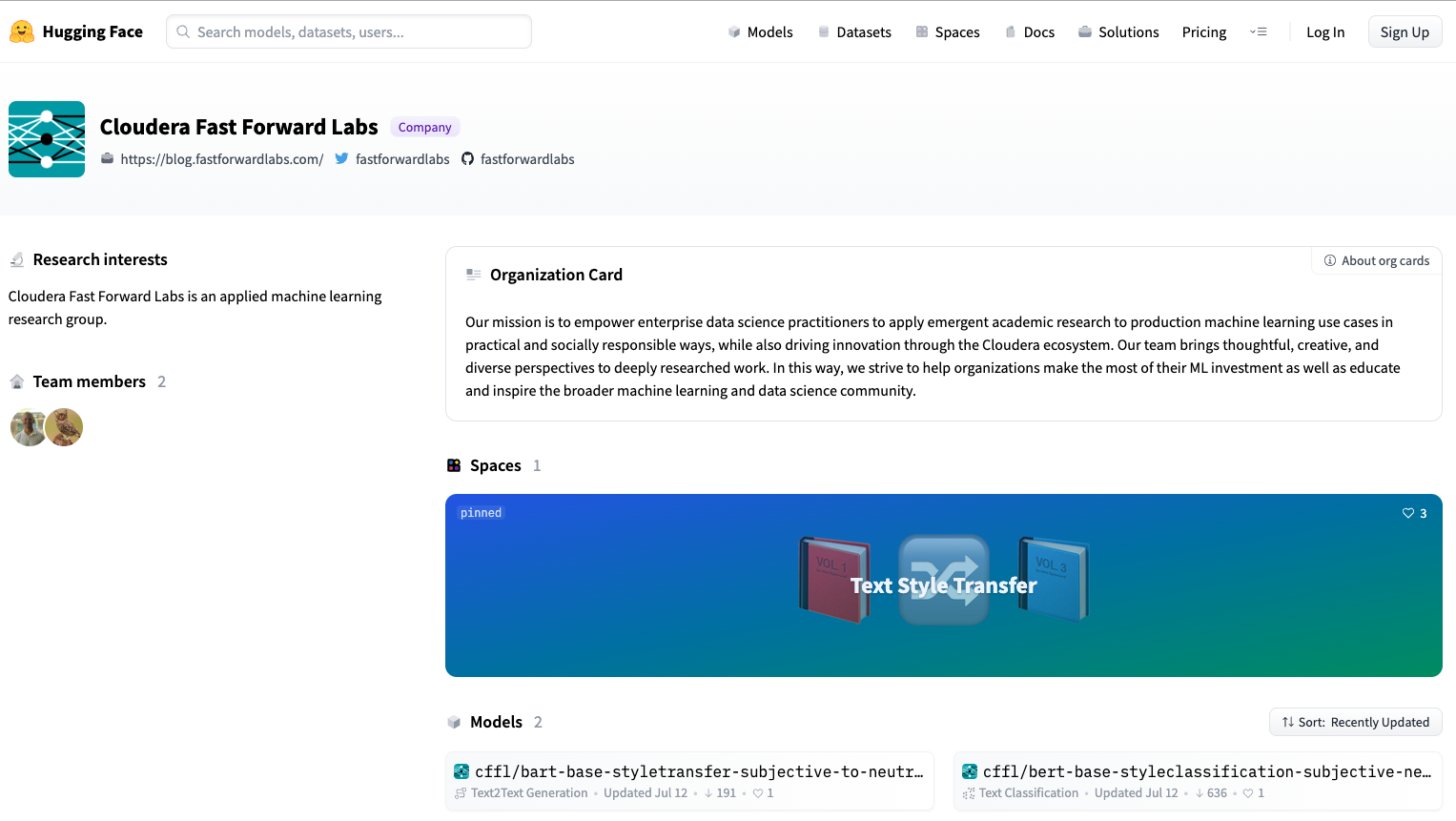
To that end, we added our Exploring Intelligent Writing Assistance application to the new HuggingFace Spaces — a place to build, host, and share ML demos. We also added the models we trained during our research initiative to the HuggingFace Model Repo. And all of these artifacts can be found right here - on our very own Cloudera Fast Forward Labs HuggingFace landing page. We’ll continue to add new Transformer models we train, along with NLP datasets we construct and applications we build so stay tuned!
Fast Forward Live!
Check out replays of livestreams covering some of our research from last year.
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended Reading
CFFLers share their favorite reads of the month.
Picking on the Same Person: Does Algorithmic Monoculture Homogenize Outcomes?
This topic was recently presented at Stanford University’s HAI (Human-centered Artificial Intelligence) Weekly Seminar. The discussion focuses on a potential by-product of the rise of reusable massive datasets and models — an algorithmic monoculture — and the implications this can have for individuals. When an individual encounters the same model again and again (say, when submitting their resume to companies that all use the same resume filtering model), or even different models that have all been trained on the same massive datasets (hello, Common Crawl), that individual could face consistent ill-treatment due to the fact that the similarities in these models cause them all to make the same (potentially unwarranted) decisions. This talk explores and formalizes this idea of “outcome homogenization” and reviews ethical arguments for why and when this is wrong. — *Melanie*
Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes
While writing my first blog post, I came across this remarkable paper. I think it speaks for itself, so I’ve copied the abstract below:
There have been many successful implementations of neural style transfer in recent years. In most of these works, the stylization process is confined to the pixel domain. However, we argue that this representation is unnatural because paintings usually consist of brushstrokes rather than pixels. We propose a method to stylize images by optimizing parameterized brushstrokes instead of pixels and further introduce a simple differentiable rendering mechanism. Our approach significantly improves visual quality and enables additional control over the stylization process such as controlling the flow of brushstrokes through user input. We provide qualitative and quantitative evaluations that show the efficacy of the proposed parameterized representation.
— Mike
Introduction to streaming for data scientists
In this excellent blog post, Chip Huyen makes the case for why and where streaming capability is needed in machine learning, and then lays out some of the core concepts and associated challenges. Namely, when a use case demands online prediction, real-time performance monitoring, or validating models developed via continual learning, there will be a necessary streaming component to the system.
One of the hardest parts of streaming ML is the infrastructure and compute engine needed to account for point-in-time data when comparing two models on historical logs — known as “time travel”. Time travel is difficult because it requires timestamp metadata to keep track of state, which is often not collected in traditional data ingest pipelines.
These issues hint at a need for a larger paradigm shift in organizations that demand realtime ML — the need to adopt “production-first” vs “development-first” workflows (and mindset). As Chip describes:
- Development-first ML workflows: features are written for training and adapted for online prediction.
- Production-first ML workflows: features are written for online prediction and backfilled for training.
There is a long road ahead for the streaming ML ecosystem — I look forward to following along with its development. — Andrew