Apr 21, 2016 · post
Summarization as a Gateway to Computable Language
Analyzing unstructured text data such as news, emails, chats, narrative prose, legal documents, or transcribed speech is an extremely tough problem. Thanks to massive leaps in data engineering, we can just about store and retrieve this torrent of information. But we can’t yet conduct the kind of rich and fast analyses that we take for granted with structured, quantitative data.
Our newly released summarization report is a response to this problem in two senses.
Summaries make documents more manageable
The first is the more obvious: by definition, summarization makes documents shorter and more manageable while retaining meaning. If you want to learn how to build automatically generated extractive summaries in your product, then the specific algorithms and prototypes we describe will definitely be interesting.
Summarization algorithms therefore have embedded within them a key component of one of the most fundamental problems in machine intelligence: how to extract and process the meaning of human language.
But the second way summarization is relevant to the problem of analyzing unstructured text is more general and, we think, more significant.
To automatically summarize text, a necessary first step is to vectorize it. That is, to rewrite it as a sequence of numbers that a computer can operate on. There are lots of ways to do this. The best (such as topic models or neural-network-based language embeddings such as skip-thoughts) are more than just counts of words. They do a good job of retaining the semantic meaning of the document in a way that is accessible to computers. We talk about them more in the report.
Done well, vectorization allows the subsequent steps of a summarization algorithm to find the key ideas in a document, which it can use to generate a summary. But vectorization is also the first step for the countless other tasks that, like summarization, implicitly involve the computer working with the meaning of a document.
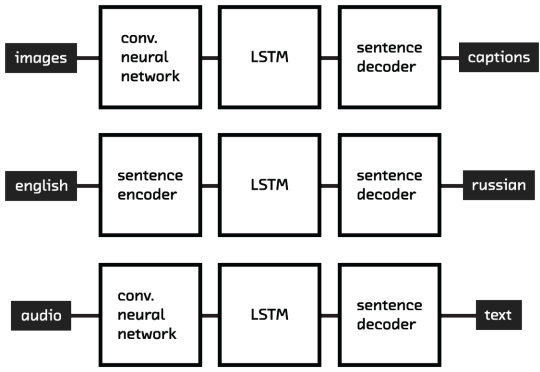
The technologies we use to summarize documents have many other potential uses
We’re really excited about the summarization algorithms and prototypes we describe in the report, which are great solutions to a valuable specific task. But we’re perhaps even more excited about the way in which they point to better approaches to simplification, translation, semantic search, document clustering, image caption generation, and even speech recognition. In that sense, they open a gateway to a future in which machine intelligence can truly understand human language.









