Apr 25, 2016 · post
Active Learning in the Law

The NIST Text Retrieval Conference (TREC) Logo
We recently released research on neural network methods to summarize text. Systems like Brief, our summarization prototype, are poised to modify how we consume text. Content systems were historically designed to help humans find, read, and research documents. But as electronically stored information continues to proliferate, systems will inevitably evolve to support research conducted by a man-machine partnership: machines will take the first pass to synthesize vast amounts of information, and humans will step in to derive more nuanced conclusions.
One field where this man-machine partnership is increasingly important is electronic discovery (eDiscovery), the processes lawyers use to discover information relevant for litigation. The traditional model, where armies of associates and paralegals read documents to find relevant information, does not scale to contemporary information volumes. To promote efficiency and curb the exorbitant costs of review, judges have issued opinions permitting the use of software that automatically finds evidence (Da Silva Moore v. Publicis Groupe) and sometimes even requiring it (EORHB Inc. v. HOA Holdings LLC).
This shift in practice has created a large market for “technology-assisted review” (TAR) or “predictive coding” software. The industry is quite large, and vendors use TAR to refer to products that use rules-based Boolean logic as well as more advanced machine learning techniques.
But two voices in the space remain clear and constant. Since they met at the 2009 Text Retrieval Conference (TREC), Gordon Cormack and Maura Grossman have published multiple papers demonstrating that continuous active learning (CAL) is the most accurate and effective technique to find “substantially all” relevant information in a document collection. As they write in their recent Practical Law article on the topic:
CAL is a method for finding substantially all relevant information on a particular subject within a vast sea of electronically stored information (ESI). At the outset, CAL resembles a web search engine, presenting first the documents that are most likely to be of interest, followed by those that are somewhat less likely to be of interest. Unlike a typical search engine, however, CAL repeatedly refines its understanding about which of the remaining documents are most likely to be of interest, based on the user’s feedback regarding the documents already presented. CAL continues to present documents, learning from user feedback, until none of the documents presented are of interest.
We met with Cormack and Grossman to learn more about why they believe CAL is the best approach for eDiscovery and how the landscape is evolving. Keep reading for highlights.
Let’s start with your background, Maura. How did you end up using TAR?
MG: The law firm where I practice has a different partner-to-associate ratio than many others that work on large-scale litigation. Most firms have multiple associates per partner. We have close to one associate per partner, which makes it challenging to handle document-intensive litigation, especially when you prefer using your own resources rather than outside contract attorneys. When I was promoted to counsel in about 2006-07, I turned to technology for help. I got involved in the TREC Legal Track in 2008, and quickly became convinced that TAR was a better, faster, and cheaper approach to document review. The big challenge was to convince lawyers, clients, and judges to adopt these methods. Today, many – but not all – lawyers and clients are comfortable relying on technology to sift through electronic evidence. So, to answer your question, my engagement with TAR resulted from an effort to solve a real problem I faced in my practice.
Gordon, how about you?
GC: I’ve spent most of my life as an academic, often working to optimize models on toy data sets with artificial constraints. But I’ve always been keen to test models on real-world problems. My first foray into the information retrieval space was in 1980, when I built a full-text library search system. In the 2000s, I worked on spam filtering and ran the Spam Track at TREC. In 2009, I tried my spam classification algorithms in the Legal Track and met Maura, who was a Topic Authority in the mock litigation, advising teams producing documents and resolving disagreements about whether particular documents were relevant or not. Encouraged by the promising results the University of Waterloo team achieved on the TREC 2009 task, Maura and I decided to see how the system would perform on a real legal matter. But before that, we collaborated on an experiment following TREC 2009, using the TREC 2009 data, comparing the performance of human reviewers with a review using two different TAR systems. The TAR systems were as, if not more, effective than the manual reviews, and were much more efficient.
We also focus on applied (v. theoretical) machine learning research at Fast Forward Labs. How would you characterize the difference between the two research styles?
GC: Natural scientists have long followed Occam’s razor, choosing the simpler over the more complex model when evaluating competing hypotheses. In theoretical computer science research, we often aim for complexity just because we can, egged on by constant increases in computational power and speed that support more complex models. But we have to sit back and ask ourselves what the complexity really buys us. In the 1980s, I invented a method for data compression called Dynamic Markov Compression. It’s relatively simple: with 200 lines of code, you can compress an average data set down to 2.1 bits per character. Sure, you could build a system that was 1000 times more complex and get the results down to 2.0 bits per character… but is it really the best use of your time? I’ve participated in the KDD Cup a few times, and always find that in one evening, people can come up with a tool that’s relatively close to a solution that may require thousands of hours more work to achieve some performance threshold. The interesting thing about applied research is that it forces you to make pragmatic decisions to judge the relative value of returns for complexity, and to focus efforts on problems that may have broader returns.
Why are spam identification and legal eDiscovery comparable problems?
GC: They’re both incremental classification problems, involving binary categories (spam v. ham; relevant v. non-relevant), and a finite number of objects to classify. In a standard supervised learning problem, you have a set of well-defined training examples and then go classify the universe. With spam, you have a finite data set that comes in as a stream. With TAR, you are presented with a large but finite document set within which you have to find the information you care about. In both instances, however, the classifiers are means to an end and not an end in itself; they’re moving targets that are disposable as you learn more about your document set. Let’s say, in a legal document collection, you start by training your classifier on 10 documents (which are 10 you don’t later have to classify). You’ll then use these results to identify the next batch of documents, refining your classifier and the target you are looking to classify. You can iterate this process until you’ve seen all (or at least substantially all) the documents relevant to your case.
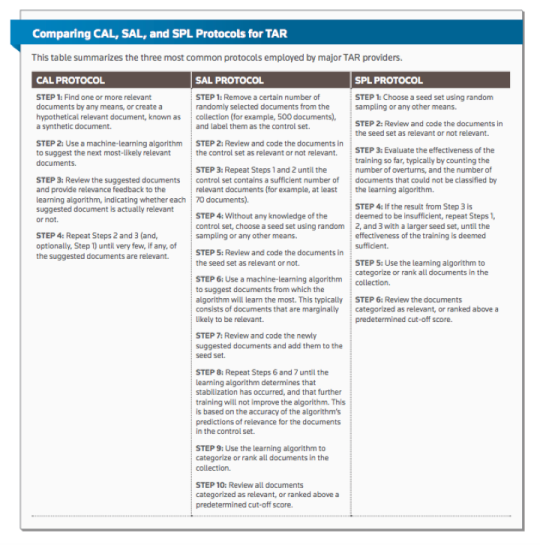
Excerpt from “Continuous Active Learning for TAR,” Practical Law Journal – Litigation, April/May 2016
Machine learning algorithms classify edge cases poorly (e.g., Google’s neural net classifying a black man as a gorilla). What are the risks in CAL?
MG: Although some lawyers are skeptical about using TAR for discovery because they fear they’ll miss the smoking-gun evidence that could make or break their case, edge cases don’t often contain the most important or dispositive information. You can think about searching for evidence like drinking a milkshake. You start off at the top with the good stuff. As you keep drinking, it begins to thin out. Maybe you tilt the cup a little to get some more, but eventually you end up sucking air through the straw and you finally stop. It’s similar with CAL, at first your batches will contain lots of relevant documents. Eventually, the relevant documents are further and further apart. You try a few things to find some more, but at some point, you decide that there’s no longer a return on your investment for combing through the remainder of the document set to find a few more.
Are there any standards to evaluate what it means to find “substantially all” documents? How can lawyers judge whether their search is complete?
MG: This is one of the biggest challenges right now: how do you know when you’re done? Many of the sampling methods in use today don’t work well in collections with low prevalence of relevant information (e.g., where only one in 1000 documents is relevant). In that case, sampling isn’t reliable, because finding no relevant documents in your sample doesn’t mean you’ve done a perfect job, and the size of the sample you would need to reliably demonstrate that you’ve found “substantially all” would be too large to be practical.
GC: We actually have paper about this coming out in the 2016 SIGIR (the Special Interest Group for Information Retrieval) conference. The question is basically: can you give a statistical guarantee of reliability that you’ve found the documents you need, or should you do this empirically? Consider the metaphor of designing an airplane: You cannot undeniably prove there is no storm that can bring down the plane, but you can do tests to establish sufficient reliability. We’re planning to test this out during the TREC Total Recall Track this year. This track explores recall performance across multiple domains, not just eDiscovery. Law is one of highest stakes applications for high-recall retrieval, but we’re also working with two state archivists on classifying governors’ emails into public v. non-public records, and exploring other consumer applications (e.g., identifying all social media information about a company, individual, or presidential candidate) – the kind of stuff that’s relevant for mining the Panama Papers.
What’s the current consensus in the courts regarding the use of algorithms for discovery? Given the size of data sets, will lawyers soon have a legal or ethical requirement to use this technology?
MG: There is still some disagreement over the degree of transparency required when a party decides to use TAR, and the extent to which counsel for one side in a lawsuit gets to participate in and drive the process for identifying relevant evidence on the other side. Tensions can arise when one party asserts that the others side’s production of relevant evidence is inadequate. It helps to move away from reliance solely on metrics based on strict percentages (i.e., we will only accept +/- 2% error rates), and to look for practical methods to resolve the problem. For example, parties can start by saying they want to be given the results of an audit of 200 random documents that the human reviewers marked non-relevant but the algorithm ranked as likely relevant; or 200 random documents that the algorithm ranked as likely non-relevant. If the results of the audit suggest a problem, this approach can provide a concrete basis to determine what was missed and serve as the starting point for a solution to refine the search going forward.
GC: The issue here is that many practitioners don’t understand how hard it is to measure recall to gauge performance. Technically, a sample may be inadequate; on top of that, different people judge relevance differently. It’s not an absolute standard. So, parties may demand 90% recall, when 70% is really a good number.
MG: The man-machine partnership can achieve recall percentages in the mid-80s or low-90s, which is great, but lawyers are still surprised that they’re missing 10 or 15% of the relevant documents. They don’t believe that humans, alone, do worse, and they are concerned they will miss the one “hot” document that will make or break their case.
Screenshot from the Computational Legal Studies homepage
Data science is slowly but surely making its way into law firms. A few firms now have Chief Data Scientists and professors are teaching computational legal studies. Where can data science have impact in law firms?
MG: The venture capital community has started to pour money into startups like Lex Machina (now part of LexisNexis), which are trying to use data to predict case outcomes and inform strategy. It’s interesting to look at some of the new applications that are emerging to predict litigation outcomes. I saw a demo of a tool where the provider had collected everything they could find that certain judges had ever written or said, and they were using those prior opinions, articles, and speeches to predict how the same judge would decide a future case. Some software could even have interesting effects on the dynamics of the marketplace: one tool claimed to look at win-loss rates for different firms, on different kinds of motions, in different jurisdictions. They told me that when you look at the data, it may not show that the big Wall Street law firm wins the most motions in a particular court; a small firm in the local mall may have the best record. For now, my mission is to continue working to provide parties, their lawyers, and the courts the empirical support they need to increase the adoption of TAR. But clients pushing back on eDiscovery costs may win that battle for me.









