Jan 25, 2017 · interview
Privacy and Encryption Above the Data: Interview with Dave Archer
Our mission at Fast Forward Labs is to commercialize artificial intelligence research, to clearly explain how new technologies work and help enterprises apply them in practical products. As our business model is rare, we’re always keen to connect with and learn from organizations that straddle this same line between research and application. That’s why we’re delighted to feature Galois, a Portland, Oregon-based R&D firm that specializes in security and trustworthiness, in this blog post.
Machine learning is changing security and trustworthiness in a few ways. First, companies like Cylance are applying deep learning to detect malware before it infects a system, which was a key limitation of former signature-based tools. Next, the appetite to use machine learning to build data products is forcing a paradigm shift in privacy and encryption: former concepts of anonymization and use limitation don’t suffice in the data-driven world, inspiring research into techniques that permit analysis while hiding the individual data that informs insights. Finally, the black box nature of many machine learning algorithms is forcing researchers to revisit definitions of trust, especially as regulators require that automated decisions impacting consumers be transparent and explainable.
We interviewed Dave Archer, a member of Galois’ research team, to learn more about what’s new in cryptography and trustworthiness. Keep reading for highlights!
You research cryptography and secure multi-party computation, but always say that Galois’ core mission is to ensure trustworthiness in critical systems. What does that mean?
Cryptography systems are tools people use to protect their data, and much of our research at Galois focuses on formally verifying that crypto tools are trustworthy: that they are correct and do exactly what they claim to do. For crypto, that means looking at crypto algorithms and mathematically proving key properties that ensure the security of those algorithms. It also means looking at crypto implementations and mathematically proving their “correctness” – their equivalence to the algorithms they implement. This is a growing issue because people increasingly design and implement their own crypto, and even a tiny error can destroy the security they’re looking for. In practice, we formally verify crypto tools in two ways. First we use automatic theorem proving to model crypto algorithms such as ciphers (encryption-decryption algorithms) and then formally prove their properties, or prove that an implementation matches an algorithm, as shown below. If proofs fail, the prover system provides a counter-example that a user can use to understand why.
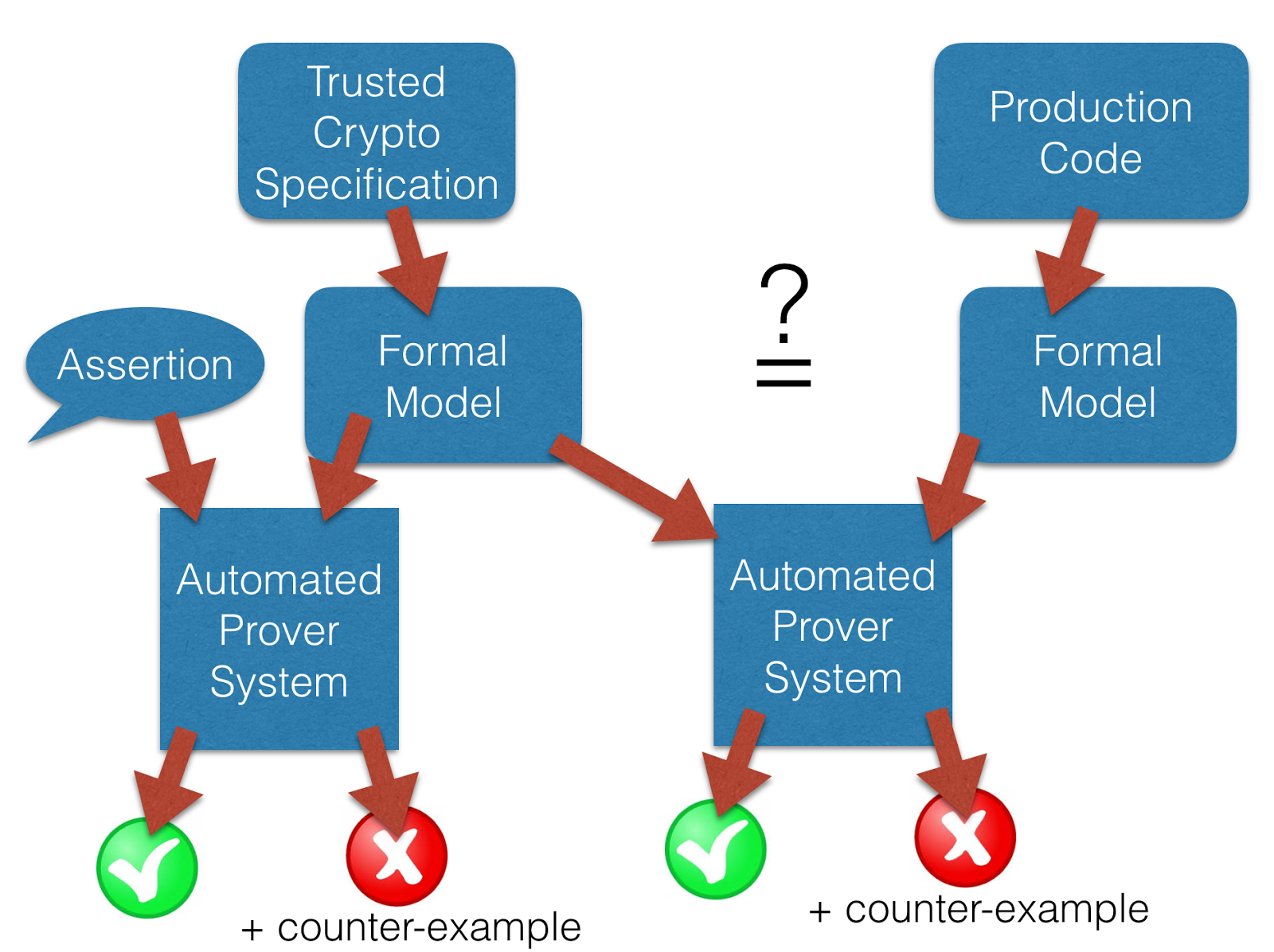
For example, one property we commonly prove is that a decryption algorithm in a cipher is the inverse of the encryption algorithm. Automatic theorem proving is an exciting area of deep learning research these days, with work featured at NIPS. Second, we formally verify crypto protocols, focusing for example on assurance that private data is transferred correctly between participants while preventing adversaries from learning those secrets or impersonating participants.
What’s one of the hardest challenges you face in your research?
Proving cryptographic properties, as well as proving equivalence between algorithms and implementations, rapidly gets more difficult as the complexity and size of code to be analyzed grows. For example, secure multi-party computation (MPC) code - code that allows computation while data remains encrypted - is complex, so proving equivalence between the MPC implementation of a cipher and the algorithm it implements is an extremely hard problem at the moment.
Trustworthiness, here, relates to ensuring the security tools you create will perform as expected. Does that definition also hold for artificial intelligence (AI) systems?
Yes. When we say a system is trustworthy, we mean that it will do exactly what we expect of it and nothing else. In the cryptography examples above, we talked mostly about proving the “exactly what we expect” part. With AI, a key part is “and nothing else.” If we delegate certain decisions to AI systems, we need to trust that they’ll make those decisions correctly, but we also need to trust that they don’t act in other ways we don’t intend. With simple machine learning techniques like linear regression, we can backtrack to understand what input feature leads to a given output. But this explanatory process is harder to tackle with more complex algorithms like those used in deep learning or AI, which is driving the exciting advancements today in computer vision and autonomous systems like self-driving cars. This is a big obstacle for wide AI adoption, so much so that DARPA has created an explainable AI program. The trust questions here are how we articulate what we want from our AI systems, and explain the reasoning behind answers in a way humans can understand. It’s a big deal, as the causal, short horizon logic and narratives humans use often differ from the long-term statistics and probability underlying machine learning tools.
What are the key opportunities to use machine learning in security?
One key area is to detect adversaries. Stealthy adversaries are very hard to detect: they try not to leave traces in simple patterns humans can comprehend, but yet they still leave traces. Machine learning such as statistical anomaly detection may well detect something like a slow advanced persistent threat in progress in a system, if detectors are trained on the right features. Traditional intrusion detectors miss those signs, and human network defenders are often so overwhelmed by the number of possible attack points that adversaries find it easy to hide. The role machine learning plays in this example is to amplify human attention by drawing attention to things that look different than the rest, enabling human decisions on defense, rather than aiming to replace security analysts outright. Another key area for ML in security is in detecting malicious software before it is activated. Modern malware is slippery: you’ll hear terms like polymorphism used to describe malware that evolves at each infection so it doesn’t conform to traditional signature detection. Machine learning techniques can detect patterns deeper than simple signatures to identify modern malware before it acts.
What about opportunities for industrial control systems rather than IT networks?
One example of security threats in industrial control systems is in US power grids. Recent events in Ukraine point out how real this issue is. However, I believe there are ways to detect such threats. For example, there are several thousand points across the grid, called Phasor Measurement Units, that monitor power. When something goes wrong, it’s critical to decide immediately if the anomaly is the beginning of a cyber attack or just a lightning storm. Machine learning across PMU measurements should be able to make those decisions and alert human operators. In 2015, DARPA started a research program to look at this kind of rapid detection and classification of power grid anomalies. This is a big deal, as we don’t historically have any visibility into the industrial control units that run the grid.
One area we’re excited about at Fast Forward Labs is differential privacy, which Cynthia Dwork has championed for some time (including at a recent symposium at Princeton). Has Galois looked into this?
Yes, we think of differential privacy as a key part of privacy-preserving computation. One interesting thing about differential privacy is that although its application seems straightforward, the math gets interesting when you apply the techniques to multiple queries over time, especially when the queried data changes significantly. The community has figured out the math to provide a basic privacy guarantee, where noise can disguise the existence of a single new record added to a data set. A more difficult question is how to manage a privacy budget, for example, how many queries the differential privacy algorithms can tolerate before an adversary could identify that single record. We don’t yet have practical tools to assign and manage a privacy budget, especially if the data keeps changing. So there are practical questions to resolve, like how often we have to recompute privacy budgets to know how much noise to add, and how these procedures will impact users.
What research are you most excited about?
Privacy of data at rest, in transit, and during computation is a huge issue, both for corporations and individuals.
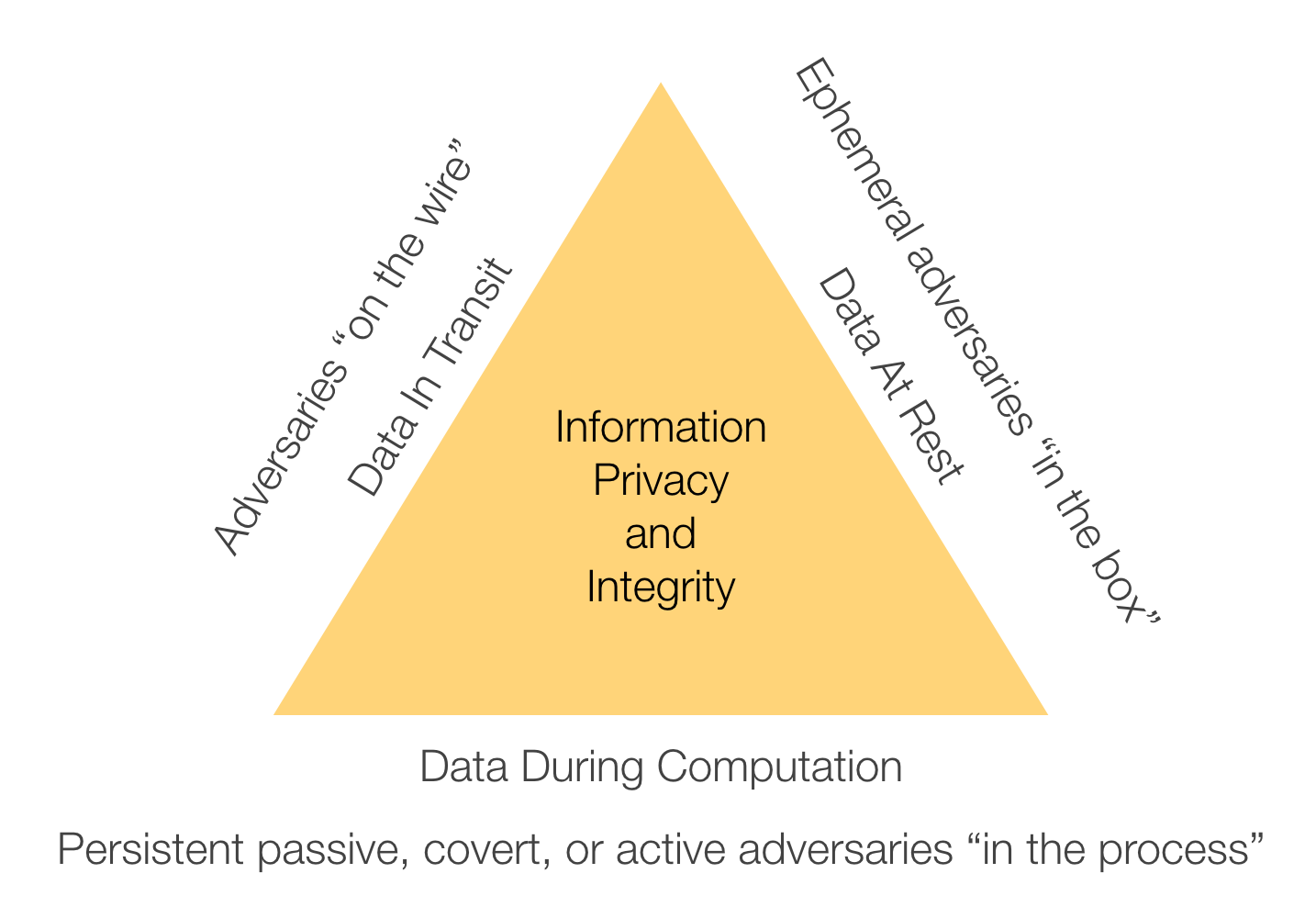
I’d claim that we largely understand how to secure data at rest and in transit (though we still need to do it, and prove it’s done correctly), but the last mile - securing data during computation - needs work. I’m really excited about the promise of functional encryption, an encryption technique where a key holder can learn only a specific function of encrypted data, but learn nothing else about the data. This is a hard problem: the research shows it’s theoretically possible, but I’d like to explore making it more practical than we’ve managed to date. Imagine if we could distribute keys that only allow users to ask the questions they care about. Then instead of users coming to the data with arbitration at some central policy enforcement point, (encrypted) data can be sent to users, with the certainty that all they can learn is a specific kind of result. This is a conceptual complement to differential privacy: functional encryption controls what can be learned, and differential privacy controls with how much precision it can be learned. I’m also excited about other ways of computing on encrypted data. There are some tools out there, but they tend to only be practical on small data or simple computations. However, progress is being made. Imagine a future where a business could apply for a loan without revealing its financial situation to the bank, yet the bank can still have assurance that the loan is a good investment. Or, imagine a future where a patient can find out whether they’re a good candidate for an advanced therapy without revealing their medical history or genome to the company offering the therapy, or to the insurance company paying for it - while still satisfying the need for those companies to know that the patient is a good candidate. It’s incredibly powerful to be able to have the results we want without being able to see the underlying data that informs those results.









