Welcome to the July Cloudera Fast Forward Labs newsletter! This month, we have some new research, livestream recordings, and some recommended reading.
New research! Multi-objective Hyperparameter Optimization
The machine learning life cycle is more than data + model = API. We know there is a wealth of subtlety and finesse involved in data cleaning and feature engineering. Similarly, there is more to model-building than feeding data in and reading off a prediction. ML model building requires thoughtfulness both in terms of which metric to optimize for a given problem, and how best to optimize your model for that metric!
While we are all familiar with the “usual suspect” metrics of predictive accuracy, recall, or precision, production models must sometimes also satisfy physical requirements such as latency or memory footprint. Hyperparameter optimization becomes even more challenging when we have multiple metrics to optimize. Our latest post examines this “multi-objective” hyperparameter optimization scenario in detail. Check it out at Exploring Multi-Objective Hyperparameter Optimization.
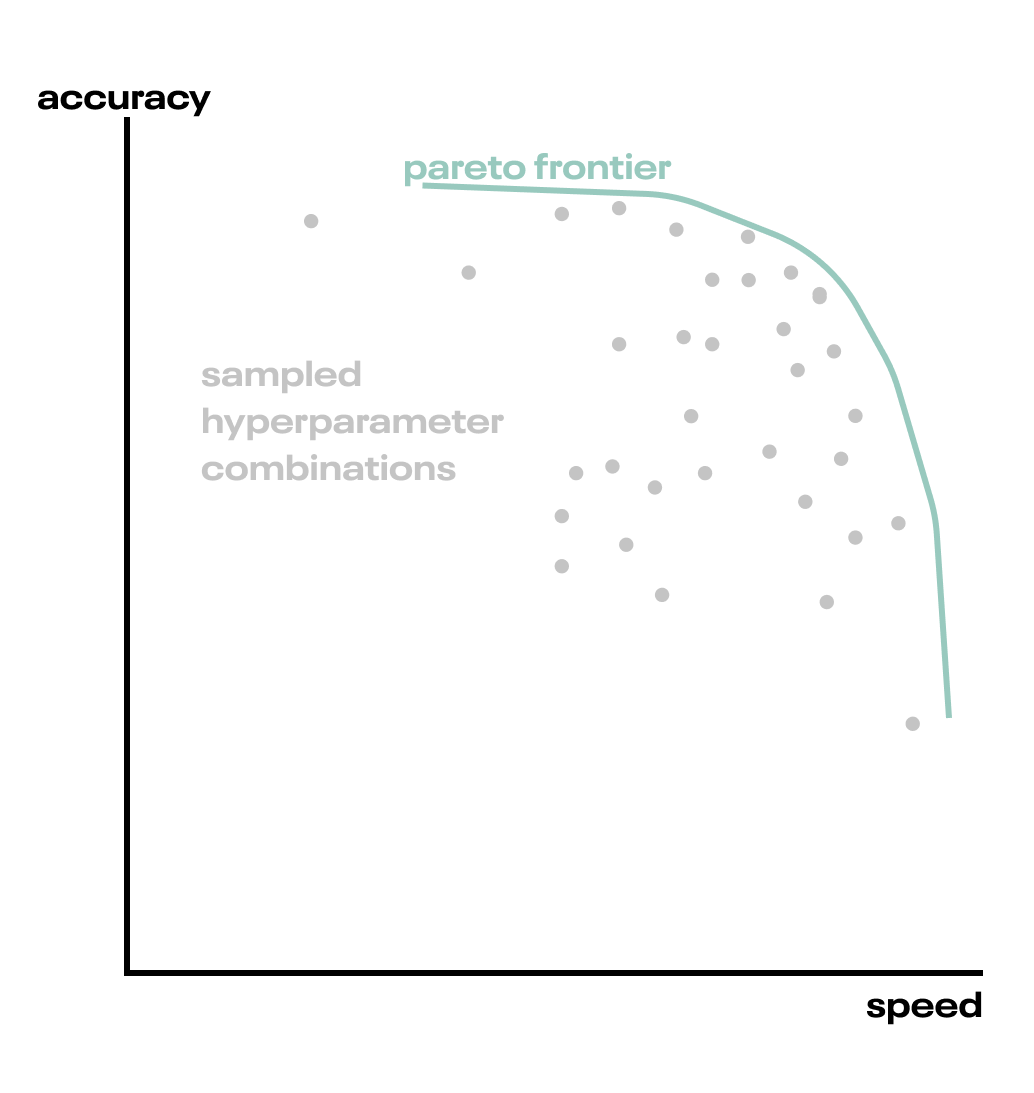 While it’s standard practice to evaluate a machine-learning model on a predictive metric (such as accuracy), ML models must often satisfy physical requirements such as inference speed.
While it’s standard practice to evaluate a machine-learning model on a predictive metric (such as accuracy), ML models must often satisfy physical requirements such as inference speed.
Fast Forward Live!
No new livestream for you this past month, but check out the back catalogue below.
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended reading
Our research engineers share their favourite reads of the month:
-
Monitoring and Explainability of Models in Production
This short, but insightful talk (and corresponding paper) by the Seldon.io team from an ICML 2020 workshop clarifies how the machine learning lifecycle extends well beyond model deployment. The team identifies several areas that are critical to the success of ML applications including monitoring performance and data metrics, detecting outliers and drift, and explaining model predictions. Each of these post-deployment tasks demand careful algorithmic and infrastructure level consideration to ensure proper operation of production systems. - Andrew
-
The winners of the 2018 Turing Award and so-called “Grandfathers of AI”, Yoshua Bengio, Yan Lecun, and Geoffrey Hinton, published a joint paper offering their perspective on the most impactful recent advancements in deep learning, as well as the most promising future research directions. On their MVP list are ReLU activation functions and the Attention Mechanism. Model generalization and massive data requirements were two areas graded Needs Improvement if deep learning models are to ever come close to mimicking the human ability to learn and perform complex, intelligent tasks. While the paper is a bit of a slog, the link also includes a five-minute TLDR video by the AI research giants, if that’s more your speed. - Melanie
-
Evaluating Large Language Models Trained on Code
This paper from OpenAI is exciting for a many reasons. First, it showcases the capabilities of Codex, a GPT-type language model trained explicitly on code. While the authors evaluate models developed for research, a production-ready descendent is deployed as GitHub’s Copilot (I’m still on the wait list for access), dubbed “Your AI pair programmer.” Cute. In addition to Codex, they also introduce a new dataset and an evaluation metric more appropriate for code assessment. But I’m also excited about the depth to which the authors explored the limitations and societal implications of Codex. They devote about 28% of the paper to these discussions in order “to encourage a norm of performing detailed impact analysis as part of major machine learning research.” Hell yeah. These impact analyses include discussions on over-reliance, bias, economic, environmental, legal, and security implications. Whew! I always have to point out a paper that takes seriously the ethical use of machine learning models. Enjoy! - Melanie
-
Reflections on ‘The Bitter Lesson’
Rich Sutton’s The Bitter Lesson can be a, well, bitter read. It contends that most machine learning problems will eventually be better solved by enormous compute and search than baking in domain knowledge or heuristics. This quick take from Michael Nielsen (who is modest to call himself a non-expert) digests and somewhat muddies the argument. While I acknowledge that new capabilities are being found with large compute and search, I’d caution against interpreting the lesson as argument for abandoning knowledge-based models altogether. Knowledge-free approaches provide little hope of being interpretable, or enhancing our understanding. The goal is not always the most accurate classifier. - Chris
-
Machine learning is data hungry and practitioners are increasingly employing data of all kinds, in terms of structure and across multiple modalities to train and evaluate the models. The Meerkat project from Stanford University, although, in its infancy, is an exciting step in this direction. It’s DataPanel abstraction draws inspiration from Pandas DataFrame to facilitate interactive dataset manipulation, housing diverse dataset modalities and works seemlessly across multiple development contexts including Jupiter Notebook, HuggingFace datasets, StreamLit, Python scripts and more. It is designed to make data inspection, evaluation and training of multi-modal and other models more efficient and robust. Just like a DataFrame, DataPanel makes it easy to store predictions or manipulate data with operations like map and filter. Future directions of the project include - making embeddings a first class citizen for ML workflows, giving users more control over all parts of the ML development pipeline and making training and repairing models easier. - Nisha