November 2021
Welcome to the November Cloudera Fast Forward Labs newsletter. Today we talk about old research blending into new, the rise of unstructured data, and what we’ve been reading this month.
New research!
We have two great original pieces for you this month — one from the vault and another fresh off the presses.
Old research meets new
Much of our earlier research endeavors are still ensconced behind a paywall but we’ve been working hard to re-release these gems, making them publicly available to anyone. This month we’ve re-released our report on Summarization! Originally written in 2016, this report pre-dates some of the more recent advances in NLP while providing an in-depth look at extractive summarization that is still highly relevant today, including a discussion of how to perform this task using recurrent neural networks.
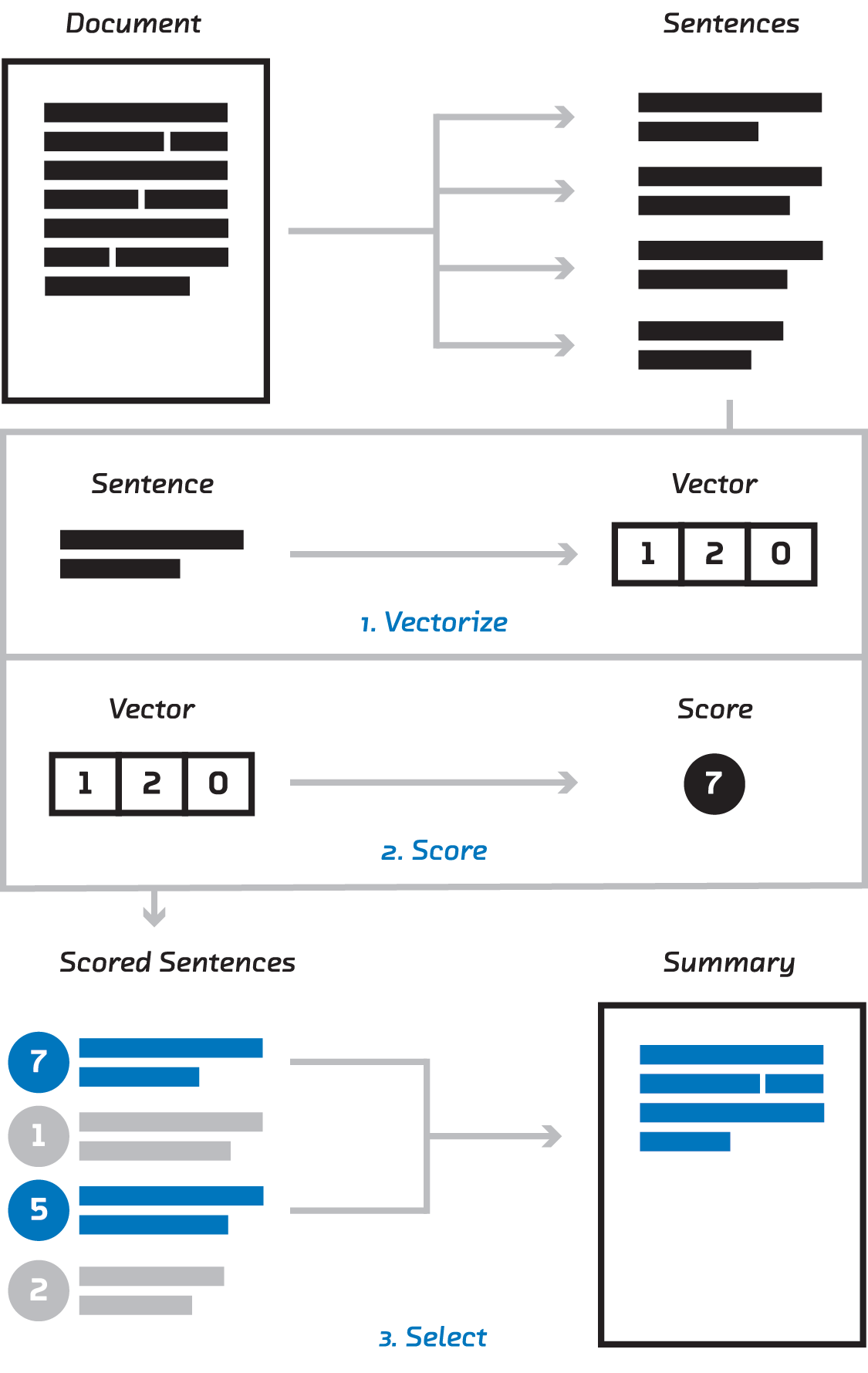
The extractive summarization pipeline: vectorize, score, and select
This report also dives deep into the development of one of our earlier prototypes: Brief. Using the methods in the report, this application provides features for quickly assessing the most important content in long news articles (check out the “skim” feature!).
It was important to us to open-source this content since we recently revisited this capability with our blog post Automatic Summarization: from Textrank to Transformers, where we begin to touch on abstractive (rather than extractive) summarization. While that post just scratches the surface of what abstractive summarization can do, there’s so much more to dig into so stay tuned!
Fresh off the presses: The Rise of Unstructured Data
In addition to the content on our FFL blog, we also contributed to the Cloudera blog this month with a look at the massive growth and taxonomy of data in the world. This well-sourced post by the newest member of the FFL team stresses the importance of recognizing the challenges and opportunities that unstructured data poses for machine learning and artificial intelligence.
Fast Forward Live!
Check out replays of livestreams covering some of our research from this year.
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended reading
Our research engineers share their favorite reads of the month:
Explaining Machine Learning Models: A Non-Technical Guide to Interpreting SHAP Analyses
Interpretability is becoming a table-stakes requirement for any machine learning project with production intent. As such, there is a strong need to bridge the data literacy gap between technical doers and non-technical stakeholders. This means communicating complex insights from model interpretation techniques in a digestible manner, but without sacrificing validity or understating algorithmic limitations. This excellent blog post by Aidan Cooper breaks down how to interpret the outputs of SHAP - one of the most popular methods for explaining ML predictions. -Andrew
MoViNets: Mobile Video Networks for Efficient Video Recognition
As the capabilities of machine learning models reach a certain level of performance, efforts to increase their efficiency start to develop. MoViNets are an example of efforts to create efficient models for video understanding. Three main techniques are used in MoViNets: Neural Architecture Search (NAS), Streaming Buffers, and Ensembling. NAS is used to find the optimal balance between spatial and temporal feature representations. This balance is needed because, in video, there is a trade-off between being able to capture what objects are present in a scene (spatial component), and what activity is being performed (both spatial and temporal components). NAS helps attain the optimal balance between those two requirements that compete for compute and memory resources. Streaming Buffers is used to limit the memory requirements. It allows processing of potentially long videos with a fixed amount of memory by splitting the full video into smaller clips, each of which is processed sequentially. Temporal dependencies are passed from one sub-clip to the next in order to capture long-term dependencies. Ensembling is used by independently training two networks and combining their logits. This is found to give higher accuracy than a single larger network with the same number of FLOPS as the combined FLOPS of the two smaller networks. Together, NAS, Streaming Buffer, and Ensembling allow MoViNets to produce state-of-the-art performance in various video understanding tasks, including video classification and activity detection, while requiring less memory and compute than competing approaches. - Daniel.
New method improves knowledge-graph-based question answering
This post by Amazon’s research team provides an overview of two papers accepted at the recent EMNLP conference (Empirical Methods in Natural Language Processing). These research efforts focus on question answering using knowledge graphs. While knowledge graphs can be a powerful data structure for many tasks, their utility for question answering has been limited because interfacing with knowledge graphs has typically required a pipeline of multiple models in order to work. Not only is it difficult to train and maintain multiple models in a pipeline, these models have also traditionally relied on intensive hand annotations for optimal performance. This blog post introduces new methods for synthesizing this pipeline of models into a single model, thus streamlining the task and removing the need for labor-intensive hand annotations. While not all of their models perform above baselines, their methods show a lot of promise for another way to train and maintain question answering models. - Melanie