February 2022
Welcome to the February edition of the Cloudera Fast Forward Labs newsletter. This month we dive deeper into the world of video convolutions, share some applied machine learning prototypes we’ve built, and discuss our top reads.
New Research!
We have another entry in the world of a newly-emerging capability: Video Understanding! While working with video data has considerable overlap with image understanding, information extraction from video presents a new level of complexity and a new world of possibilities. This month we look at the connection between image and video through convolutions.
Why and How Convolutions Work for Video Classification
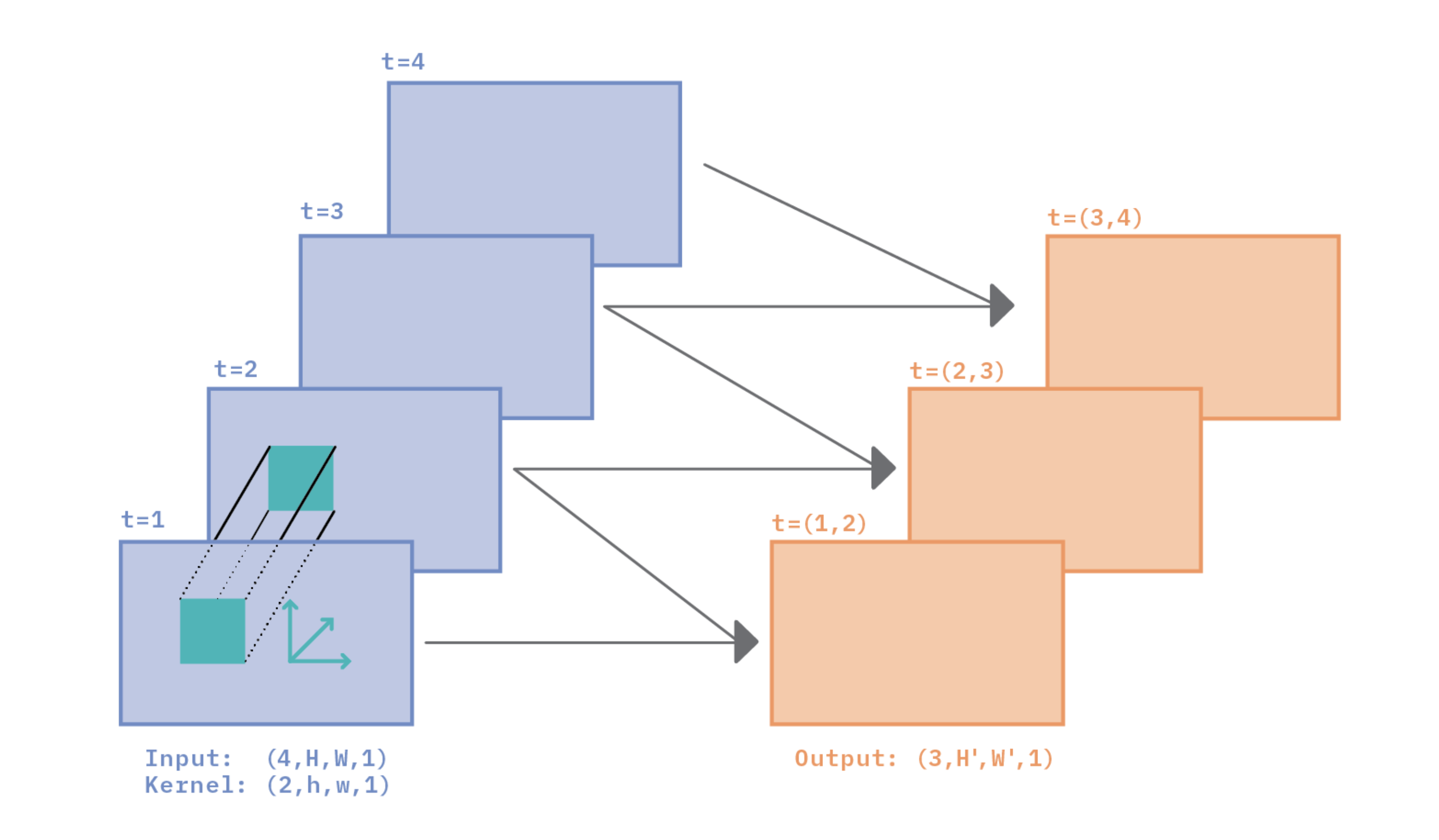
Video classification is perhaps the simplest and most fundamental of the tasks in the field of video understanding. In this blog post, we’ll take a deep dive into why and how convolutions work for video classification. Our goal is to help the reader develop an intuition about the relationship between space (the image part of video) and time (the sequence part of video), and pave the way to a deep understanding of video classification algorithms.
New Applied ML Prototypes (AMPs)!
Those familiar with our work know that here at CFFL, we don’t just write about the latest ML, we also love to build things with it! Our applied machine learning prototypes (AMPs) provide reference example machine learning projects in Cloudera’s data science products, but the content in these repos can often be explored in any environment. They range from in-depth Jupyter Notebook examples to full-scale web or Streamlit applications, and everything in between.
To combat concept drift in production systems, it’s important to have robust monitoring capabilities that alert stakeholders when relationships in the incoming data or model have changed. In this Applied Machine Learning Prototype (AMP), we demonstrate how this can be achieved on CML. Specifically, we leverage CML’s Model Metrics feature in combination with Evidently.ai’s Data Drift, Numerical Target Drift, and Regression Performance reports to monitor a simulated production model that predicts housing prices over time.
Video footage constitutes a significant portion of all data in the world. The 30 thousand hours of video uploaded to Youtube every hour is a part of that data; another portion is produced by 770 million surveillance cameras globally. The vastness of video, along with its tremendous capacity to store information, makes video understanding a key technology. This Applied ML Prototype (AMP) introduces Video Classification through an exploration of a key dataset and a pretrained model. The AMP demonstrates how to download, organize, explore, pre-process, and visualize the Kinetics Human Action Video Dataset, and how to test a pretrained model on both small and large data samples.
Fast Forward Live!
Check out replays of livestreams covering some of our research from last year.
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended reading
Our research engineers share their favorite reads of the month.
After powering through the NLP community, the modern Transformer architecture has marched its way onto the computer vision main stage. Hierarchical vision transformers (namely the Swin Transformer) have recently demonstrated the potential for transformer-based models to serve as generic vision backbones by achieving state-of-the-art (SOTA) performance across a variety of computer vision tasks.
This excellent paper investigates architectural distinctions between traditional ConvNets and Transformers, and attempts to “modernize” a standard ResNet towards the design of a vision Transformer. For example, the authors find that a significant portion of the performance discrepancy between the two may be attributed simply to the enhanced training procedure of Transformers alone. In the end, the paper proposes ConvNeXt, a pure ConvNet model that can compete favorably with SOTA vision Transformers. — Andrew
The Illustrated Retrieval Transformer
Last month I recommended a blog post about WebGPT, a new NLP model that answers open-ended questions by essentially performing a Google search. This month’s offering is in a similar vein: a blog post by Jay Alammar (of The Illustrated Transformer fame) that illustrates DeepMind’s recent RETRO model. Both RETRO and WebGPT are examples of a new breed of Transformer language models that are augmented with the ability to look up the information they need to perform the task required. WebGPT looked up information by literally searching the internet. RETRO, on the other hand, is augmented with a database. Because these models can look up the information they need, they no longer need to memorize the entire internet. This allows them to achieve results on par with some of the mega-models (like GPT3) but at a fraction of the parameters! Turns out bigger isn’t always better. - Melanie
Emerging Properties in Self-Supervised Vision Transformers
Image object segmentation has up to recently relied heavily both on convolutions and labeled data. This paper presents a method which can perform segmentation without either of those mechanisms. It shows that self-supervised Vision Transformers (ViT) provide object segmentation information, which is accessible in the self-attention modules of the last block of the architecture. Both self-supervision (rather than supervision) and Transformers (rather than convolutions) are key to producing clearly defined segmentation. Another aspect of the self-supervised ViT features is that they are strong k-NN image classifiers. And a third interesting point is training efficiency: among self-supervised approaches, training ViT is argued to require less computational resources than training convolutional architectures for a given performance. -Daniel.