November 2022
Perhaps November conjures thoughts of holiday feasts and festivities, but for us, it’s the perfect time to chew the fat about machine learning! Make room on your plate for a peek behind the scenes into our current research on harnessing synthetic image generation to improve classification tasks. And, as usual, we reflect on our favorite reads of the month.
New Research!
In the first half of this year, we focused on natural language processing with our Text Style Transfer blog series. But for the past couple of months, we’ve turned our attention back to topics in computer vision. Specifically, we’ve been digging into how synthetic data can be used to augment imbalanced datasets for image classification and segmentation tasks. While we’re still in the midst of experimentation, we thought we’d share a peek behind the scenes at how we built and trained our own CycleGAN model. Enjoy!
Implementing CycleGAN
This post documents the first part of a research effort to quantify what (if any) performance improvement we could expect by incorporating synthetic data when training a deep neural network for detecting manufacturing defects on steel surfaces. In order to generate the synthetic data to answer this question, we implemented CycleGAN “from scratch” using PyTorch. This blog covers our initial journey of iteration and trial-and-error, where we had to answer questions like:
- How do you set up a research problem like this?
- How can you simplify that problem into its most basic components for experimentation?
- How do you know if your “from scratch” model implementation is achieving reasonable results?
- And what do zebras have to do with any of this? 🦓

Fast Forward Live!
Check out replays of livestreams covering some of our research from last year.
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended Reading
CFFLers share their favorite reads of the month.
A Recipe for Training Neural Networks
Who can relate — you approach a new deep learning problem, get excited, and jump off to the races training some fancy model architecture + state-of-the-art loss function combo that you know will perform well because you read a blog where it worked on some “similar” task? The model is training, but the results just aren’t quite what you anticipate… something is off. If you’re lucky, an exception will be thrown. But most likely, the model trains just fine, and silently accepts the degraded performance. You’re left staring at a seemingly infinite number of possible loose ends deciding where to begin debugging…if you even come to realize there’s an issue at all.
As Andrej Karpathy describes, this is the beginning of the long, arduous road to suffering, and I too am guilty of marching down this “fast and furious” path. Luckily, Andrej has compiled some excellent tidbits of knowledge into a recipe that I often reference to help steer clear of this treacherous path. His recipe calls for patience, attention to detail, and a methodical process in an effort to prevent the introduction of “unverified complexity” which is bound to introduce bugs that take an enormous amount of time/suffering to root cause.
I highly recommend giving this quick blog post a read and bookmarking it for any time you approach a new modeling problem. — Andrew
Learning Semantic Segmentation From Synthetic Data: A Geometrically Guided Input-Output Adaptation Approach
Continuing the theme of synthetic data for computer vision problems, I wanted to share this paper. The authors exploit ground-truth semantic and depth information from photo-realistic simulations to train a network that jointly learns semantic segmentation and depth estimation. The method does not require ground-truth segmentation or depth maps for the real data. Instead, the training procedure adapts the network to achieve similar outputs on synthetic and real images, and also demonstrates an improvement from jointly learning the two related tasks. — Mike
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
While the work and results within this paper are fascinating, I’m miffed by the authors’ chosen title, which implies they have succeeded in training a model to “reason.” This is pure sensationalism, especially when considering the paper’s final paragraph in which the authors state quite plainly:
…although chain-of-thought emulates the thought processes of human reasoners, this does not answer whether the neural network is actually “reasoning,” which we leave as an open question.
But I suppose “Chain-of-Thought Prompting Elicits the Emulation of Reasoning in Large Language Models” just doesn’t have the same ring.
Regardless, the results are intriguing! Take a gander at this example, which provides a succinct summary of the whole paper:
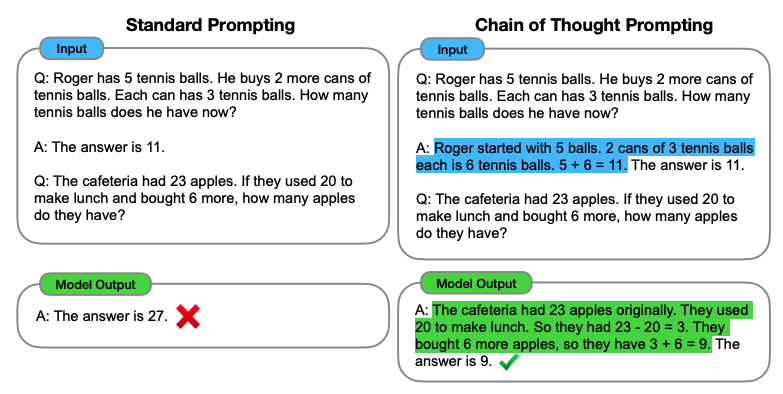
Essentially, providing a rationale as part of the language model’s input prompt encourages the model to provide a rationale of its own when answering reasoning questions, leading to far better results. The authors explore and compare chain-of-thought prompting to other methodologies on a range of arithmetic, commonsense, and symbolic reasoning tasks. This technique also lends itself well to few-shot regimes. For example, the authors find that priming a PaLM 540B model with just 8 chain-of-thought prompts surpasses a fine-tuned GPT-3+verifier on a benchmark dataset. Although the PaLM model has 3x more parameters to learn from, fine-tuning a GPT-3 model and training a verifier can be costly. The scalability of this technique could have far-reaching implications for how future language models are developed. — Melanie