Welcome to the June edition of the Cloudera Fast Forward Labs newsletter. This month, we have some new research, livestream recordings, and our recommended reading.
New research! Deep Metric Learning: Applications in Automatic Offline Signature Verification
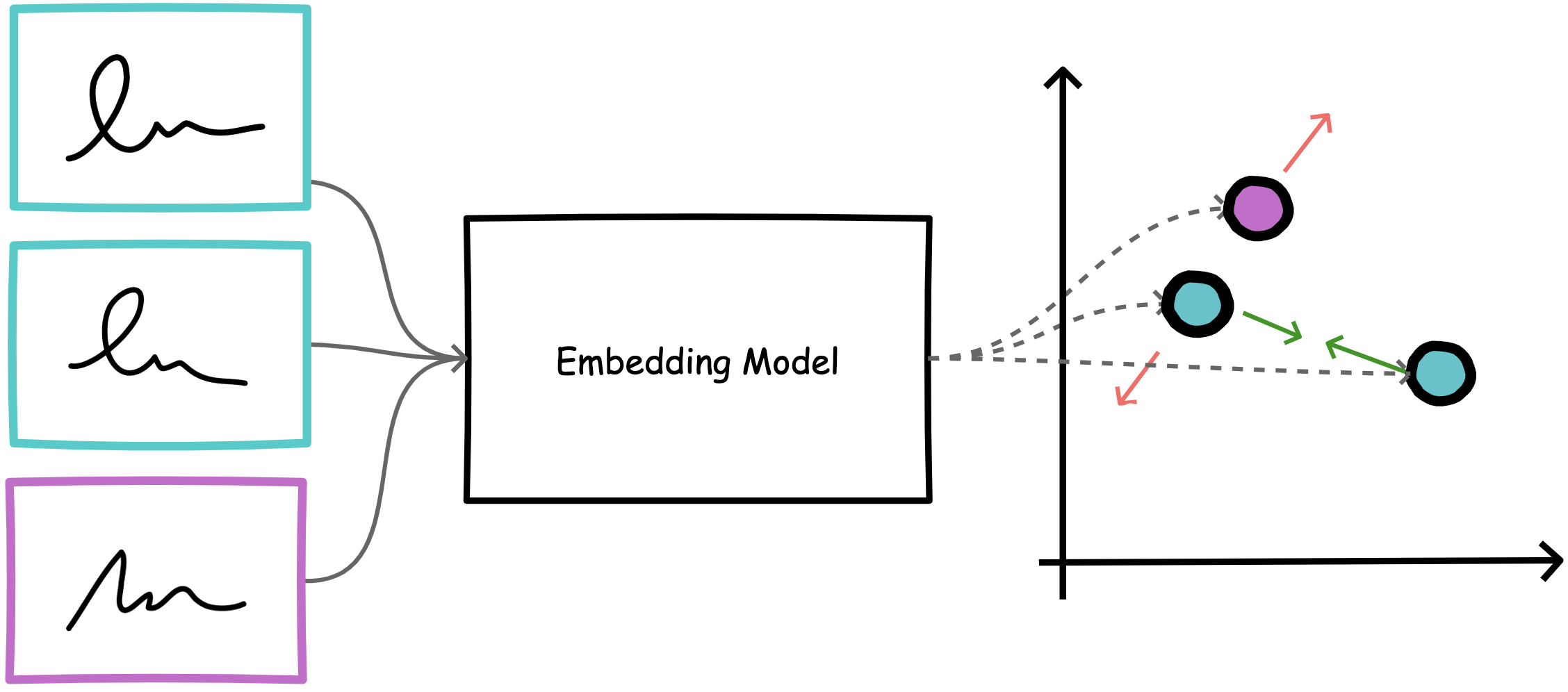
The past couple of months, we’ve been tackling the forensic task of offline signature verification using modern deep learning techniques. Handwritten signature verification aims to automatically discriminate between genuine and forged signatures, and is a particularly important challenge due to the ubiquity of handwritten signatures as a form of identification in legal, financial, and administrative domains. This research cycle explored the use of deep metric learning approaches - specifically siamese networks - combined with novel feature extraction methods to improve upon traditional techniques. We wrote about our experience in three blog posts:
Deep Learning for Automatic Offline Signature Verification
Pre-trained Models as a Strong Baseline for Automatic Signature Verification
Deep Metric Learning for Signature Verification
And wrapped up an experimental library to help with the task. Check it out at fastforwardlabs/signver.
Fast Forward Live!
In our latest livestream Deep Learning for Automatic Offline Signature Verification, Victor and Andrew gave a half hour walk through of our signature verification research, and answered some audience questions.
You can also still catch a replay of our previous livestreams:
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended reading
Our research engineers share their favourite reads of the month:
-
How to generate text: using different decoding methods for language generation with Transformers
Ever wonder how transformer-based language models are able to generate such authentic sounding text snippets? I did. Aside from improvements in architecture design and massive training corpora, it turns out that thoughtful decoding methods play a crucial role in sounding more “human”. This informative post by HuggingFace demonstrates the impact of various decoding methods on a generative model’s ability to produce unique, interesting, and non-repetitive language. - Andrew
-
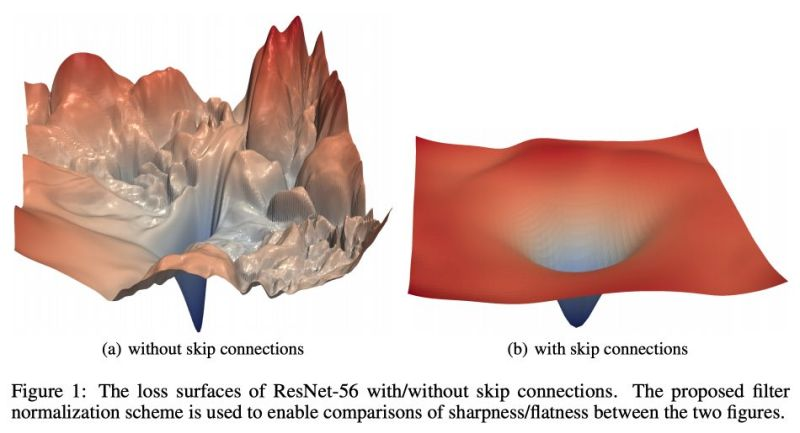
Visualizing the Loss Landscape of Neural Nets
Deep models with skip connections (e.g. ResNet-like architectures) work well in practice i.e. converge faster, and generalize better. Why? This paper (https://arxiv.org/abs/1712.09913) visualizes the loss landscape and provides some insights. Hint: Skip connections result in more “convex” loss landscapes. According to the authors, “chaotic landscapes (deep networks without skip connections) result in worse training and test error, while more convex landscapes have lower error values”.
We recently ran a few experiments (fine tuning pretrained model features with a metric learning objective, for the task of signature verification) and found that skip connection models (ResNet family) provided better results. This paper was useful in understanding how and why. - Victor
-
Rethinking Attention with Performers
Move over, Transformers! There’s a new language model in town and it is lean. While we don’t actually recommend trying to slog through this unarguably dense paper, we highlight it this month because of it’s promise for the direction of language models going forward. In it, the authors demonstrate a new way of computing the attention mechanism, the backbone of Transformer models that allows them to learn complex dependencies between input tokens. Standard attention scales quadratically in both space (memory) and time (computation) with the number of input tokens, making them expensive to train and manage. The authors demonstrate their attention mechanism scales linearly, paving the way for large language models that are more efficient (and cheaper) to train, while maintaining the same levels of accuracy as traditional Transformers. This technique is sure to become increasingly popular, making language models ever more attainable. - Melanie
-
Designing AI systems for deep learning recommendation and beyond
At a recent MLSys seminar, the speaker, Carole-Jean Wu shared her work at Facebook that focusses at the intersection of systems and machine learning, in particular recommendation systems. In her talk she covers why recommendation systems are important, how they are an under-invested area of research, some of the unique system challenges they present, ideas on building systems for deep learning recommendations and new benchmarks and models that Facebook has made available in this space.
One of the key points of the presentation being deep learning for recommendations is an under-invested area when it comes to research from a systems perspective. Less than 2% of research publications are devoted to optimizing systems for recommendation engines compared to other areas like computer vision that account for 82% and neural speech translation for 16%. One of the primary reasons for this disconnect is the availability of a representative workload benchmark to evaluate the latest research ideas. She further covers an overview of the underlying approaches for recommendation models at Facebook that mainly employ Dense DNN and embeddings to learn representations and ranking. And shares how different portions of a recommendation model have different system requirements. For instance, the Dense DNN stack that is implemented as a multilayer perceptron (MLP ) is compute intensive whereas the operations on the embeddings are memory capacity/storage and bandwidth intensive. The system requirements also differ when it comes to training versus inference. All this along with the need to maximize a system’s throughput while minimizing latency poses a unique set of system challenges. For instance, large embedding tables require orders of magnitude larger storage capacity as compared to CNNs and RNNs. Overall a great talk that shares Facebook’s take on designing and optimizing systems for deep learning-based recommendations. - Nisha
-
Elements of Clojure, Chapter 1: Names
Nominally, Elements of Clojure is a book about the Clojure programming language. Even for those who are not familiar with the language, the first chapter of this book (which is the free preview) is an excellent discussion of naming in software. Thoughtful names have a whole host of benefits, making software more understandable, reducing cognitive overhead, and result in a more easily maintained code base. Whether you read this particular piece or not, I highly recommend dedicating time to reading and thinking about what we call things in our code. - Chris