July 2022
Welcome to the July edition of the Cloudera Fast Forward Labs newsletter. This month we share the latest installment in our Text Style Transfer series and chat about the good reads we’ve recently come across.
New Research!
We’re nearing the end of our journey into the burgeoning world of Text Style Transfer. But no foray would be complete without a thorough discussion on model evaluation — an absolute must for any practical application.
Automated Metrics for Evaluating Text Style Transfer
In our previous blog post in the series, we took an in-depth look at how to neutralize subjectivity bias in text using HuggingFace transformers by fine-tuning a BART model on a subset of the Wiki Neutrality Corpus (WNC). In our latest post, we expand our modeling efforts to the full WNC dataset and discuss the challenges of evaluating the text style transfer task.
Additionally, we explore a set of custom automated evaluation metrics designed to quantify the quality of text style transfer better than the oft-cited BLEU score, which provides only a one-dimensional measure of quality. Text Style Transfer is a complex task that requires more nuanced assessment. Specifically, we design and experiment with two metrics: Style Transfer Intensity (STI) and Content Preservation Score (CPS).
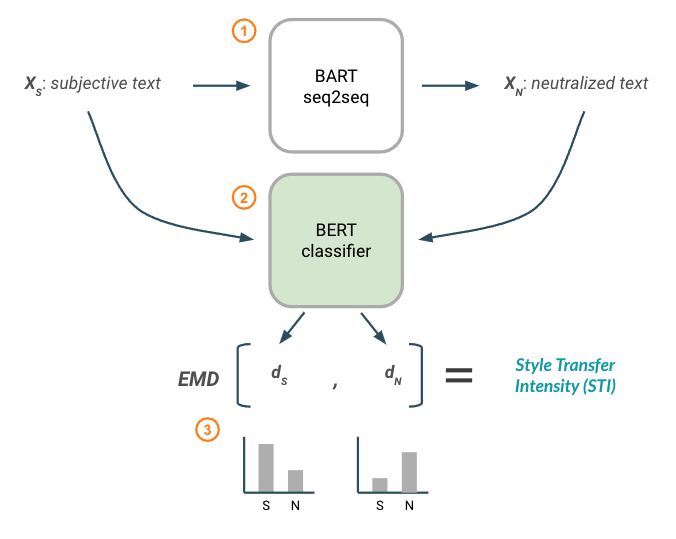 Style Transfer Intensity metric using a BERT classification model.
Style Transfer Intensity metric using a BERT classification model.
The goal of the STI metric is to assess the degree of the style transfer performed by the BART model, essentially, how strongly did we transfer style? To measure this, both the subjective input text and the neutralized output text are passed through a BERT model that has been trained to classify subjective versus neutral text. The BERT classifier outputs a “style distribution,” or how likely it is that a piece of text is neutral or subjective. Finally, the Earth Mover’s Distance is calculated between the two distributions, which tells us how much work it would take to turn one distribution into the other. This STI score can be interpreted as the intensity or magnitude of the style transfer.
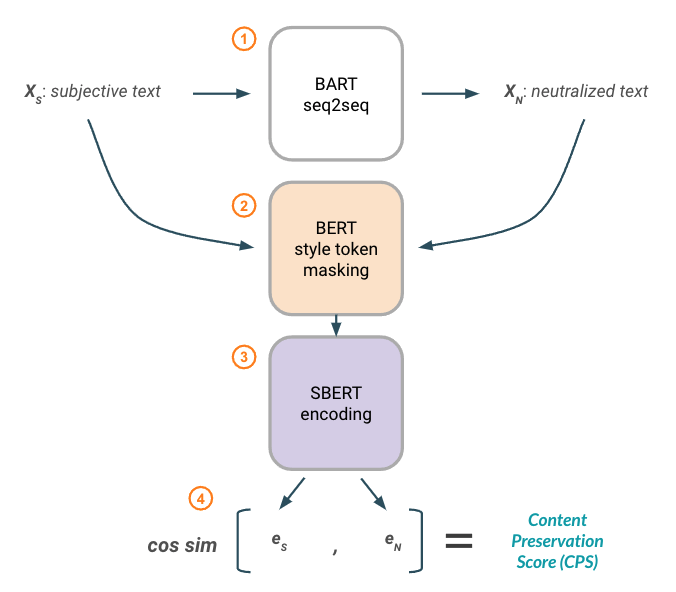 Content Preservation Score metric using BERT-based word attributions for style masking and SentenceBERT embeddings for similarity.
Content Preservation Score metric using BERT-based word attributions for style masking and SentenceBERT embeddings for similarity.
The of CPS metric is designed to assess how well the style-transferred text retains the semantic meaning of the original text. This is important because transferring style would not be useful if, during the process, we completely changed the semantic meaning of the original sentence! To measure this, we compare the original subjective input text to the neutralized output text by masking the “style” words from each of them to produce versions that contain only “content-related” words. These masked texts are then passed through a SentenceBERT model to generate a sentence embedding for each. Finally, we calculate the cosine similarity between them.
The blog delves into how we developed these metrics, their pros and cons, and the experiments we performed to assess their usability. Check it out!
Fast Forward Live!
Check out replays of livestreams covering some of our research from last year.
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended Reading
CFFLers share their favorite reads of the month.
How to set up a Python project for automation and collaboration
Last month, I shared a detailed handbook for writing “good” research code - including how to set up and organize project files, modularize code components, and test that things are working as expected. This month, I’m sharing a complementary blog post by Eugene Yan that overlaps with and extends these concepts. In particular, this post offers a quick run through of common software engineering tools/practices that facilitate project collaboration — reducing the management burden of onboarding new contributors and maintaining good code hygiene.
I find myself referencing both of these resources for each new project I begin. Hopefully you find them just as helpful! — Andrew
New method identifies the root causes of statistical outliers
The field of statistics has investigated the problem of outliers for more than a century, developing dozens of methods for detecting them. However, formally defining the root cause of outliers has been a major gap in the field until recently. While formal definitions may seem like so much stuffy math, they are crucial for developing methods of attribution.
This article by researchers at Amazon discusses their recent paper at ICML that fills this gap using causal models. They further provide a framework for integrating causality into outlier detection and root cause analysis - a critical component of many complex real-world use cases, such as understanding manufacturing equipment issues, or latency problems in web applications. If some of the concepts in this article are new to you, FFL has written about causality in machine learning before, in which we provide a great foundation for flexing your inference and counterfactual muscles! — Melanie