Welcome to the September Cloudera Fast Forward Labs newsletter.
New research!
We like to build things. In the past couple of months we’ve been hard at work on a new prototype, as well as wrapping up a few loose threads from various research directions that we’ve touched on so far this year. Our efforts have culminated in a fun new application and blog posts.
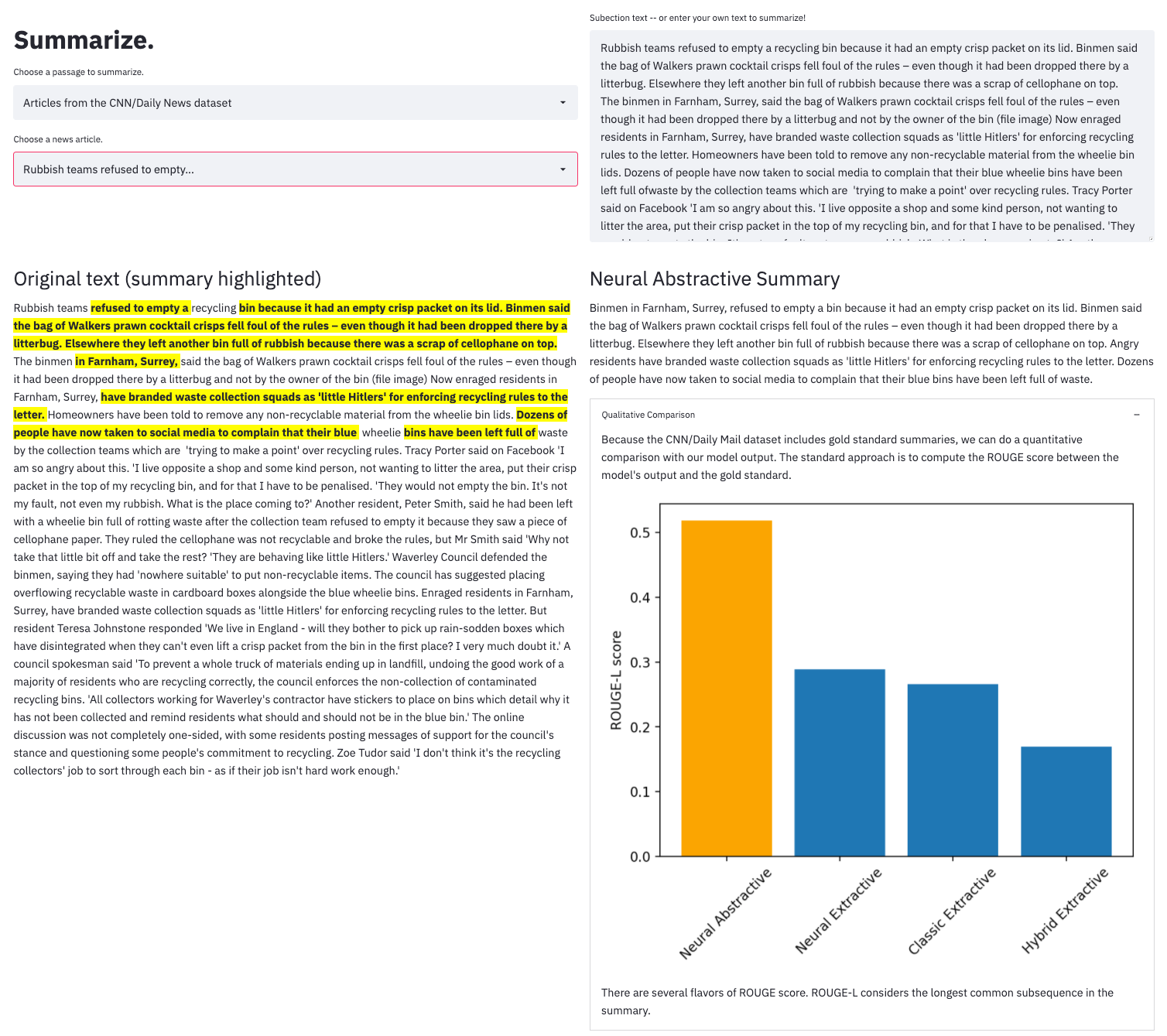
Summarize.
Automatic summarization is a task in which a machine distills a large amount of data into a subset (the summary) that retains the most relevant and important information from the whole. While traditionally applied to text, automatic summarization can include other formats such as images or audio. In this post we cover the main approaches to automatic text summarization, talk about what makes for a good summary, and introduce Summarize. – a summarization prototype we built that showcases both extractive and abstractive automatic summarization models.
Extractive Summarization with SentenceBERT
In this post, we dive deeper into how we trained a SentenceBERT model to perform extractive summarization, from model architecture to considerations for training and inference. You can interact with this model in the Summarize. prototype!
How (and when) to enable early stopping for Gensim’s Word2Vec
The Gensim library is a staple of the NLP stack and supports what is likely the best-known implementation of Word2Vec. In this post, we cover how to train Word2Vec for non-language use cases (like learning item embeddings) and explain when you should and shouldn’t use early stopping.
Fast Forward Live!
Check out replays of livestreams covering some of our research from this year.
Deep Learning for Automatic Offline Signature Verification
Session-based Recommender Systems
Representation Learning for Software Engineers
Recommended reading
Our research engineers share their favourite reads of the month:
-
Why data scientists shouldn’t need to know Kubernetes
In this post, Chip Huyen postulates that the ever-increasing job description of the “full stack” data scientist - from data to modeling to infrastructure - results from discordance between development and production environments that practitioners are expected to operate across. In today’s world, production ML requires knowledge of low-level infrastructure which is a very distinct skillset from traditional data science disciplines. Chip argues that rather than adding hats to the data scientists’ already extensive wardrobe, the solution involves proper infrastructure abstraction; a world where data scientists can own the ML lifecycle end-to-end without having to worry about infrastructure complexity. This post does a great job of summarizing the capability and direction of several tools that are helping to solve this issue. - Andrew
-
Active learning for production
Since our very first research on ML with limited labeled data, active learning (AL) and the like approaches have always been on my radar. After all labeled data is one of the most basic requirements for many ML applications. That said, as widely known many of these approaches, especially the ones based on deep learning are often not scalable for large datasets or are too slow in production environments. At times these could be too slow to train and/or vast amounts of data is needed for them to be performant. A recent paper discusses a Bayesian approach to AL in a production-like setting. While it builds on the technique based on dropout layers being activated during test time to determine uncertainty (similar to what we had researched and experimented with), the researchers provide a nice comprehensive library for practitioners to experiment with and confirm our observations on class imbalance issues. - Nisha
-
Slot Machines: Discovering Winning Combinations of Random Weights in Neural Networks
As a former blackjack dealer (it was a long time ago) and avid gambler, the title of this paper caught my eye and the content didn’t disappoint! This provocative entry to ICML earlier this year rolls the dice on a new way to train neural networks: don’t train them at all! (At least, not in the traditional way.) They present a method wherein the weights of a neural network are randomly instantiated and are never updated during training. Instead, each weight is allowed to pick a value from a fixed set of possible values. Each of these options has a score associated with it that corresponds to how likely that value is to contribute to a better neural network overall. Essentially, it is these scores that are trained — not the model weights! They perform a slew of experiments comparing their method to randomly instantiated models, traditionally trained models, and more. It makes for both an entertaining and enlightening read. - Melanie
-
ViViT: A Video Vision Transformer
My previous work in compute-constrained Computer Vision (CV) restricted me not only to low-energy, low-memory consumption models — but also to convolutions as the main architectural building block. A look at recent literature, however, reveals a trend in CV towards the replacement of convolutions with attention modules. This trend accelerated after the publication, in 2017, of the seminal paper Attention is All You Need, which introduced a pure-attention model for NLP. But it is only in 2021 that pure-attention models are achieving state-of-the-art in CV. An example of this is ViViT, a family of pure-transformer based models for video classification. ViViT uses factorization to increase efficiency, and regularization and pre-training to reduce of the need of large training datasets. Execution times are presented for ViViT variants in the paper, but not compared against competing architectures, e.g., those based on convolutions, which would be particularly interesting to see. - Daniel
-
Building a data team at a mid-stage startup: a short story
This parable of a new head of data transforming a company to be data driven is entirely fictional, but aspects of it will resonate with anyone who has worked in a data role. - Chris
-
Listening: On the Metal with Jonathan Blow
The On the Metal podcast from Oxide computer company is the best kind of technical podcast: nerds being nerds about nerdy things. This nearly 3-hour episode with indie game developer Jonathan Blow is full of technical insights about game dev and programming languages, and also strong opinions on the state of the computing industry at large. - Chris