Sep 21, 2021 · post
Extractive Summarization with Sentence-BERT
In extractive summarization, the task is to identify a subset of text (e.g., sentences) from a document that can then be assembled into a summary. Overall, we can treat extractive summarization as a recommendation problem. That is, given a query, recommend a set of sentences that are relevant. The query here is the document, relevance is a measure of whether a given sentence belongs in the document summary.
How we go about obtaining this measure of relevance varies (a common dilemma for any recommendation system). We can select from multiple problem formulations such as:
-
Classification/Regression: Given input(s), output a class or relevance score for each sentence. Here, the input is a document and a sentence from the document. The output is a class (belongs in summary or not) or a likelihood score (likelihood that sentence belongs in the summary. This formulation is pairwise, i.e., at test time we need to compute n passes through the model for n sentences to get n classes/scores, or compute this as a batch.
-
Metric Learning: Learn a shared distance metric embedding space for both documents and sentences such that embeddings for sentences that should belong in the summary for that document are closest to the document’s embedding in distance space. At test time, we get a representation of the document and each sentence, and then get the most similar sentences. This approach has the benefit that we can leverage fast similarity search algorithms.
In this work, we will explore a classification setup as a baseline. While this approach is pairwise, and thus compute intensive with respect to the number of sentences, we can accept this limitation as most documents have a relatively tractable number of sentences.
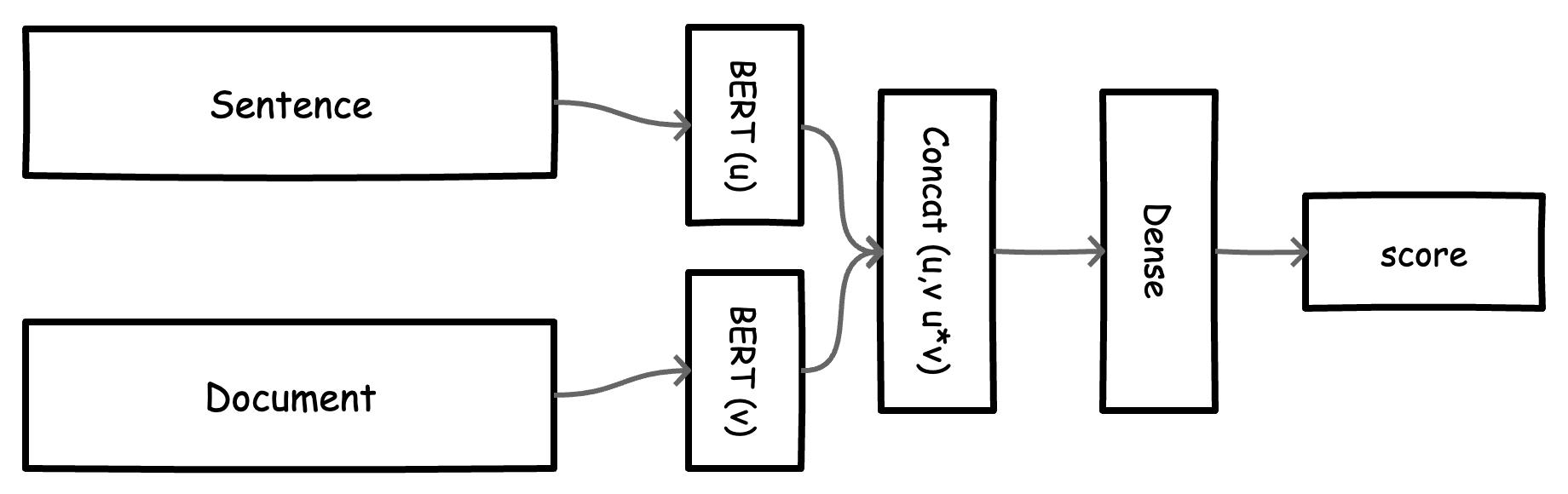 Fig. We structure extractive summarization as a text classification problem.
Fig. We structure extractive summarization as a text classification problem.
Dataset
In this example, we will use the CNN/Dailymail dataset, which contains nearly three hundred thousand news articles, each with a human written “highlights”, that we’ll use as the article summary. These data have been preprocessed in the following way:
- Each article is split into sentences using a large Spacy language model.
- Each sentence is assigned a label (0: not in summary, 1: in summary).
- Since CNN/DailyMail highlights don’t contain exact extracts, the label is generated based on max ROUGE1 score between a given sentence and each sentence in the highlights. See data preprocessing notebook for details.
- Data is undersampled to reduce class imbalance.
Implementation for Extractive Summarization
In our classification setup, we want good representations for our sentences and documents. For this, we explore Sentence-BERT models (Reimers et. al. 2018) that have shown good results on the task of sentence representation learning. The model is fairly simple and can be broken down into the following parts:
- Compute tokens and attention masks for both sentence (u) and document (v) using a tokenizer.
- Get mean pooling embeddings for each input.
- Concatenate both inputs (Concat(u,v, u*v)).
- Add a classification head (Dense and Dropout layers).
The entire model is then fine tuned using the CNN/Dailymail dataset. In the baseline, we achieve accuracy of 86% on the train set and 74% on a held out test set.
Inference with a neural extractive summarization model
We can summarize inference such that, for each new document:
- Construct a list of sentences using Spacy (drop short sentences).
- Construct a batch of sentence + document pairs.
- Get score predictions for each sentence.
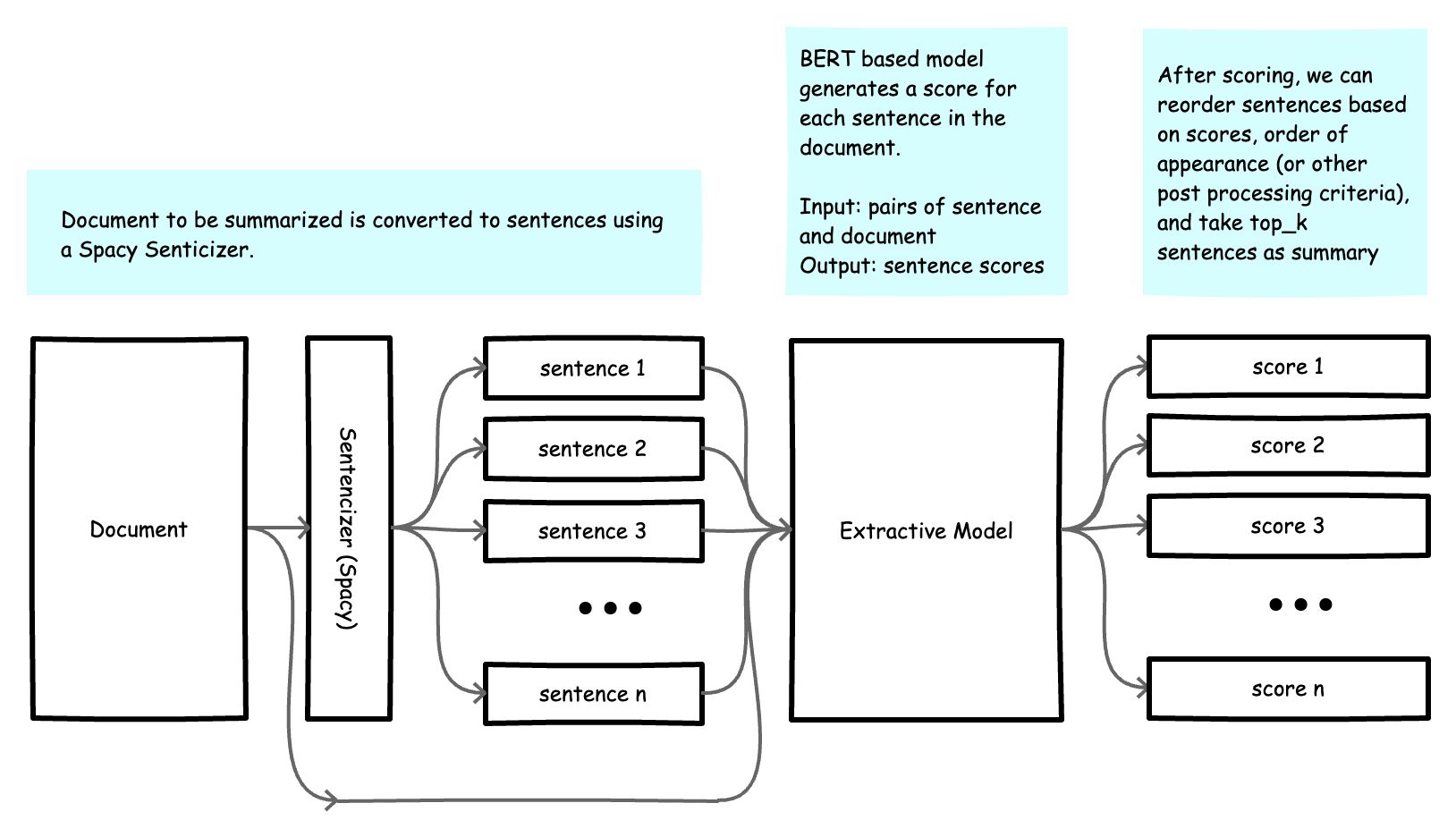 Fig. Inference with a neural extractive summarization model.
Fig. Inference with a neural extractive summarization model.
We can post process this list of relevant sentences and return a subset to the user as the extracted summary:
- Construct a list of sentence dictionaries - {sent, score, index} prediction, where the index references that sentence’s appearance in the original document.
- Sort list by score.
- Take the top_k sentences to be included in summary.
- Sort top_k sentences by order of appearance (and any other metric).
- [Optional] Post-process each sentence for grammatical correctness, e.g., detect incomplete sentences, grammar issues, rephrase sentences, etc.
Example Results
In this section, we present an example article and the summary generated by our baseline model. Evaluating a text summarization model is challenging as this process can be subjective and relies on some context that may be difficult to model. We discuss some of these challenges in our previous post.

Our best bet is to look at things like ROUGE score between sentences selected by the model and sentences in a subjective ground truth dataset. In this example from the CNN/Daily Mail test set, our baseline summary achieves a ROUGE score that is competitive with other models we tried. These models can be explored in our summarization prototype, which the reader is invited to try out.
Improving the Sentence Classification Baseline
The approach described above is a relatively untuned baseline. There are multiple opportunities for improvement. We discuss a few below.
-
Handling Data Imbalance
Given the nature of the task (selecting a small subset of sentences in a lengthy document), for most of the sentences we get from our training dataset, the vast majority will not belong to a summary. Class imbalance! In this work, we used undersampling as a baseline strategy to handle class imbalance. A limitation of this approach is that we use a relatively small part of the total available data. We can explore other approaches that enable us to use most or all of our data. Weighted loss functions are recommended! -
Sentencizer
Constructing our training dataset examples depends on the use of a sentencizer that converts documents to sentences which are used in constructing training examples. Similarly, at test time, a sentencizer is used to convert documents to sentences which are scored and used in the summary. A poor sentencizer (e.g. one that clips sentences midway) will make for summaries that are hard to read/follow. We found that using a large Spacy language model was a good starting point (the small model is not recommended). Bonus points for investing in a custom sentencizer that incorporates domain knowledge for your problem space. -
Sentence and Document Representations \ In this baseline, we use the Sentence-BERT small model in deriving representations for sentences and documents. Other methods (e.g., larger models) may provide improved results. One thing to note is that while BERT-based models yield a representation for an arbitrarily sized document, in practice they only use the first n tokens (the maximum sequence length for the model which is usually 512 tokens). We also found that fine tuning the underlying BERT model on the extractive summarization task yielded significantly better results than using the BERT model as a simple feature extractor.
-
Tuning Hyperparameters \ A project like this has many obvious and non-obvious hyperparameters that could all be tuned. Beyond the choice of BERT model architecture and training parameters, we could also tune things like the label generation strategy, sentencizer, minimum sentence length to use in training/inference, etc.
Conclusion
In this work we have discussed how extractive summarization can be formulated as a sentence classification problem and implemented this approach using modern language models. We have also discussed a set of limitations and opportunities for improving a baseline model. You can interact with this model in our new Summarize. prototype.
-
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization and machine translation software in natural language processing. Rouge score may be based on unigram or bigram overlap or longest common subsequence. ↩︎









