Sep 8, 2022 · post
Thought experiment: Human-centric machine learning for comic book creation
I want to make a comic book. Actually, I want to make tools for making comic books. See, the problem is, I can’t draw too good. I mean, I’m working on it. Check out these self portraits drawn 6 months apart:

Left: “Sad Face”. February 2022. Right: “Eyyyy”. August 2022.
But I have a long way to go until my illustrations would be considered professional quality, notwithstanding the time it would take me to develop the many other skills needed for making comic books.
So that’s why I want to make tools for making comic books. What kind of tools, you ask? Well, I have an admittedly naive understanding of how to make comic books, but here are some ideas. They aren’t perfect, but I believe something contemplated is closer to reality than the uncontemplated.
Concept artificer
What if you could do something like this?
![]()
Or, more generally:
![]()
It’s not far-fetched. Here’s a picture from a 2022 paper called “CLIPstyler: Image Style Transfer With a Single Text Condition,”1:

This immediately suggests the following method for making my comic book:

I started this drawing at 4:12 pm and finished it at 4:46 pm, taking 34 minutes.
The framework is simple: I draw my entire comic book with whatever art I can muster, then I can use a style transfer model to make it look “good”. If I can crank out 2 pages per hour, then a 30-page comic book would take a mere 15 hours of my labor.2
But it’s easy to pick this simplistic framework apart. For example, one would like stylistic consistency of the same subjects from page to page, a desirable property that is analogous to temporal consistency in video processing. A style transfer model is unlikely to deliver such consistency for a comic book out of the box.
What exactly is temporal consistency?
Consider if you wanted to colorize a black-and-white video. Videos can be thought of as an ordered sequence of images or frames, so one way to do it would be to colorize each frame independently using your favorite single-image technique. The problem with that approach is that a single-image technique might assign different colors to the same subject in two successive frames, resulting in flickering as the colors quickly change.
Temporal consistency refers to the absence of such artifacts. Now take a moment to watch the cool video at “Learning Blind Video Temporal Consistency”3, come back, squint your eyes, and imagine how you could apply this to comic book page consistency. Comic books, like videos, are also an ordered sequence of images - although of course there are key differences, primarily that successive video frames typically depict the same scene fractions of a second apart, whereas the scenes depicted in successive comic book panels are likely more sparse in time.
Exploiting prior beliefs to promote consistency
Comic books are information rich, and the prior beliefs we have about them can be exploited in the context of optimization. Let’s frame the problem using an example 3-panel comic:

What are the repeated elements where stylistic consistency would be desired? Let’s list some out:
| Elements where stylistic consistency is desired | |
|---|---|
| Characters | Settings |
| The Hero | The Hero's home |
| The Princess | The Princess' castle |
| The Dragon | |
The character of the Hero appears in every panel, and if we want to visually communicate that it is the same character in each panel, we should ensure they look the same. Similarly the setting of the Hero’s home appears both in the first and last panel. The other listed elements appear only once, but it’s easy to imagine a more detailed story where these elements appear more than once, and then stylistic consistency becomes a concern for them as well.
There is not one single or obviously most effective way to encode prior belief, but one very basic way is to ask whether a desired element simply appears in a panel. We can express our prior belief in terms of conditional probabilities about images:
$$
\hat{p}(E_i|X_j) := \hat{p}_{ij} := \begin{cases}
1 \text{ if } E_i \text{ appears in } X_j, \
0 \text{ otherwise }
\end{cases}
$$
Where Ei represents an element such as the Hero or the Hero’s home, and Xj the jth panel.
Detecting the appearance of an element in a panel is not a trivial computer vision problem - for example a character’s location in the panel, pose, and all manner of details are not fixed. But image classification is a well-studied problem to which deep learning has been applied with great success. If we presuppose a good style transfer network and a family of binary classifiers that can estimate the conditional probability that an element Ei appears in an image Xj (pij for brevity) then we immediately have a comic book making framework that incorporates this notion of stylistic consistency:
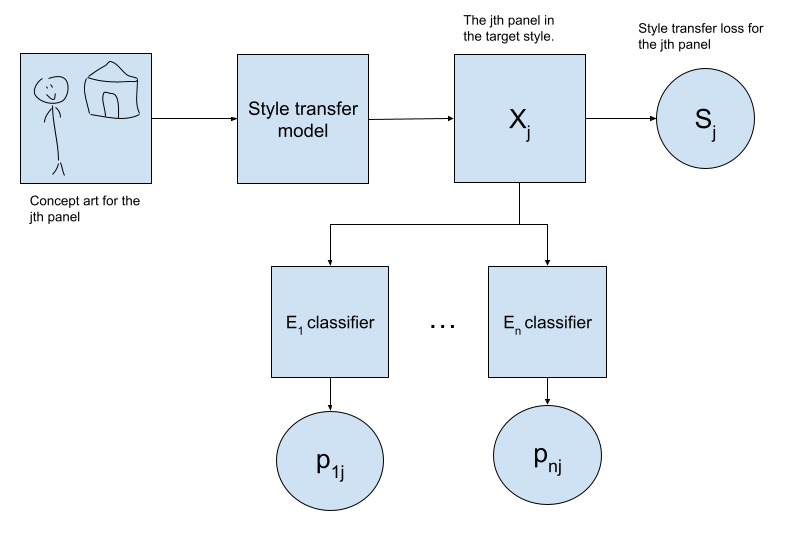
And we can make our comic book by optimizing the Comic Book Loss over all panels with respect to the style transfer model parameters using the usual methods:
$$
\begin{array} \
C_{ij} := H(\hat{p_{ij}}, p_{ij}) = -\hat{p_{ij}}\log{p_{ij}} - (1 - \hat{p_{ij}})\log{(1 - p_{ij})} \
\
\text{Comic Book Loss} := \sum\limits_{j} S_j + \sum\limits_{i,j} C_{ij}
\end{array}
$$
Where the terms Cij are defined as the binary cross-entropy between the distribution encoding our prior belief about the panels, and the estimated distribution from our classifiers. These terms are minimized when our stylistic classifiers are very confident that their respective subject appears or doesn’t appear in the desired panels, according to our prior beliefs. The terms Sj are simply whatever losses our style transfer network typically uses.
In summary, here’s how I’m going to make my comic book:
- Draw concept art for all my pages.
- Identify elements where I want stylistic consistency.
- Train binary classifiers for each such element.
- Fine-tune a good style transfer model to minimize the Comic Book Loss over my concept art.
- Voila!
Ok, but why?
Honestly, I really do want to make comic books!
…
Alright, I have some additional motivations.
For one, I’m obsessed with fiction. Fiction is the funhouse mirror reflection of real life, and it has often been my welcome guide through a confusing world by helping me more clearly imagine what is possible. I know I’m not alone in feeling that way. My hope is that developing systems like the one outlined above will make a storyteller out of someone who wouldn’t have otherwise been one, for lack of artistic skill, or time, or whatever. For me personally, making a high quality comic book I could be proud of could take years if I do it the traditional way4, but perhaps I can leverage my already-accumulated years of experience with machine learning to do it more quickly.
For another, as a machine learning practitioner, I think a lot about the implications of the technology I develop on society, because I want to create systems that I can be proud of. It’s easy to find many credible opinions that technological development is not an unqualified good thing. One criticism levied at AI algorithms in particular is that the automation they’ll enable will destroy jobs for humans. I want to put forth my idea above as a partial answer to that - here’s a new application5, with the potential to become a new kind of job. Moreover it’s one with human involvement baked into the very core of the process - superficially in order to produce concept art, but more fundamentally because AI and machine learning can’t tell us what stories we want to make!
Conclusion
There’s still a lot we could improve about the above framework, notwithstanding the challenge of training image classifiers for important story elements. For example, we could make our notion of consistency more precise by asking not only if an element simply appears in a panel at all, but asking how closely it matches the location and content of the corresponding element in the concept art. And if we have some thoughts or directions about a panel expressed as text, it would be great if the final output could be conditioned on that as well. I’d love to hear your thoughts, so drop me a line!
-
Kwon, Gihyun, and Jong Chul Ye. “CLIPstyler: Image Style Transfer With a Single Text Condition,” 18062–71, 2022. ↩︎
-
Equivalent to 2 uncomfortable working days, or 5 great working days. And please take this estimate with a grain of salt. ↩︎
-
Lai, Wei-Sheng, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. “Learning Blind Video Temporal Consistency,” 170–85, 2018. ↩︎
-
Not least because I’d have to learn a hell of a lot of new skills. ↩︎
-
I am not the first to think of using AI for comic books, although I believe my formulation of the task is novel. See Yang, Xin, Zongliang Ma, Letian Yu, Ying Cao, Baocai Yin, Xiaopeng Wei, Qiang Zhang, and Rynson W. H. Lau. “Automatic Comic Generation with Stylistic Multi-Page Layouts and Emotion-Driven Text Balloon Generation.” arXiv, January 26, 2021. https://doi.org/10.48550/arXiv.2101.11111.
See also https://bleedingcool.com/comics/lungflower-graphic-novel-drawn-by-a-i-algorithm-is-first-to-publish/. ↩︎








