Jul 29, 2022 · post
Ethical Considerations When Designing an NLG System
At last, we’ve made it to the final chapter of this blog series. We started by broadly introducing the NLP task of text style transfer and discussing the often overlooked, but important role that style plays in the successful adoption of NLP technologies. We then explored how conditional language modeling approaches can be applied to the task of automatically neutralizing subjectivity bias. In doing so, we were faced with the nuanced difficulty of evaluating natural language generation (NLG), and implemented automated metrics to quantify style transfer strength and content preservation for our model outputs.
In this final post, we’ll discuss some ethical considerations when working with natural language generation systems and describe the design of our prototype application: Exploring Intelligent Writing Assistance.
Ethics as a criteria for topic selection in research
Standard practices for “responsible research” in the field of machine learning have begun to take hold. We now have datasheets for novel datasets, which are intended to document a dataset’s motivation, composition, collection process, source of bias, and intended use1. Similarly, we have model cards that encourage transparent model reporting by detailing expected usage, performance characteristics, and model lineage2. While adoption of these practices still has room to grow, the seed is planted and has laid the foundation for increased transparency and accountability within the machine learning community.
However, both of these artifacts are backward looking – describing considerations of work products that have already been created. It is equally as important to consider ethical implications at the genesis of a project, before any research effort is underway. Similar to datasheets and model cards, ethics sheets have been proposed to encourage researchers to think about ethical considerations not just at the level of individual models and datasets, but also at the level of ML/AI tasks prior to engaging in a research endeavor3. An ethics sheet for an AI task is a semi-standardized article that aggregates and organizes a wide variety of ethical considerations relevant for that task. Creating an ethically focused document before researching or building an AI system opens discussion channels, creates accountability, and may even discourage project pursuance based on the supporting analysis.
For these reasons, our team engaged in brainstorming activity prior to researching the task of “automatically neutralizing subjectivity bias in text” to consider potential benefits and harms of exploring and modeling the style attribute of subjectivity. We review some of our considerations below.
Potential benefits
As discussed in the second post of this series, subjective language is all around us. It makes for a useful style of communication by which we express ourselves and influence others. However, there are certain modes of communication today like textbooks and encyclopedias that strive for neutrality. A neutral tone is what this type of audience expects and demands.
In this context, a tool to automatically detect subjectively-toned language and suggest neutrally-toned counterparts could be helpful for several parties. For authors and editors, a tool of this kind could enable more efficient and comprehensive review of new and existing content – resulting in a higher standard of quality throughout published material. For content consumers, this type of tool could provide reading assistance to help alert readers when subjectivity bias is concealed within content they perceive to be neutrally-toned and factual.
Potential risks
Most modern language models used for generative tasks today build representations based on massive, uncensored datasets, which are subsequently fine-tuned on a smaller, focused corpora for a particular task. Therefore, these fine-tuned models inherit all of the potential risks associated with the large foundation models, plus any application specific concerns.
In this sense, our task adopts the risk of a model unintentionally reflecting unjust, toxic, and oppressive speech present in the training data. The consequences of this are that learning and projecting unknown biases can perpetuate social exclusion, discrimination, and hate speech4. Language models also risk introducing factually false, misleading, or sensitive information into generated outputs.
There is also the potential for malicious actors to intentionally cause harm with such a tool. While our efforts focus only on modeling the subjective-to-neutral style attribute direction, successful methods for generating neutral-toned text could be reverse engineered to model the opposite. Generating subjectively biased text, automatically and at scale, could be used to undermine public discourse.
Similarly, adapting a successful modeling approach to a tangentially related style transfer task (e.g. political slant) could be used to exploit the [political] views of the masses if used for a malevolent social agenda. And finally, what is a world without opinion? A model that can silence the expressiveness of individual language could numb our ability to convey thoughts and feelings in online channels.
Should these risks discourage research
An upfront discussion of ethics is intended to capture various considerations that should be taken into account when deciding whether to develop a certain system, how it should be built, and how to assess its societal impact3. Ultimately, the concerns we’ve raised above do not simply “go away” by not exploring them. Instead, given the existing maturity of this field of NLP, we view this as an opportunity to increase transparency by surfacing the risks, along with our findings, best practices, and mitigating strategies.
Designing an intelligent writing assistant
To highlight the potential of this NLP task, we’ve bundled together our research artifacts into an intelligent writing assistance application that demonstrates how text style transfer can be used to enhance the human writing experience.
We emphasize the imperative for a human-in-the-loop user experience as a risk-mitigation strategy when designing natural language generation systems. We believe text style transfer has the potential to empower writers to better express themselves, but not by blindly generating text. Rather, generative models, in conjunction with interpretability methods, should be combined to help writers understand the nuances of linguistic style and suggest stylistic edits that may improve their writing.
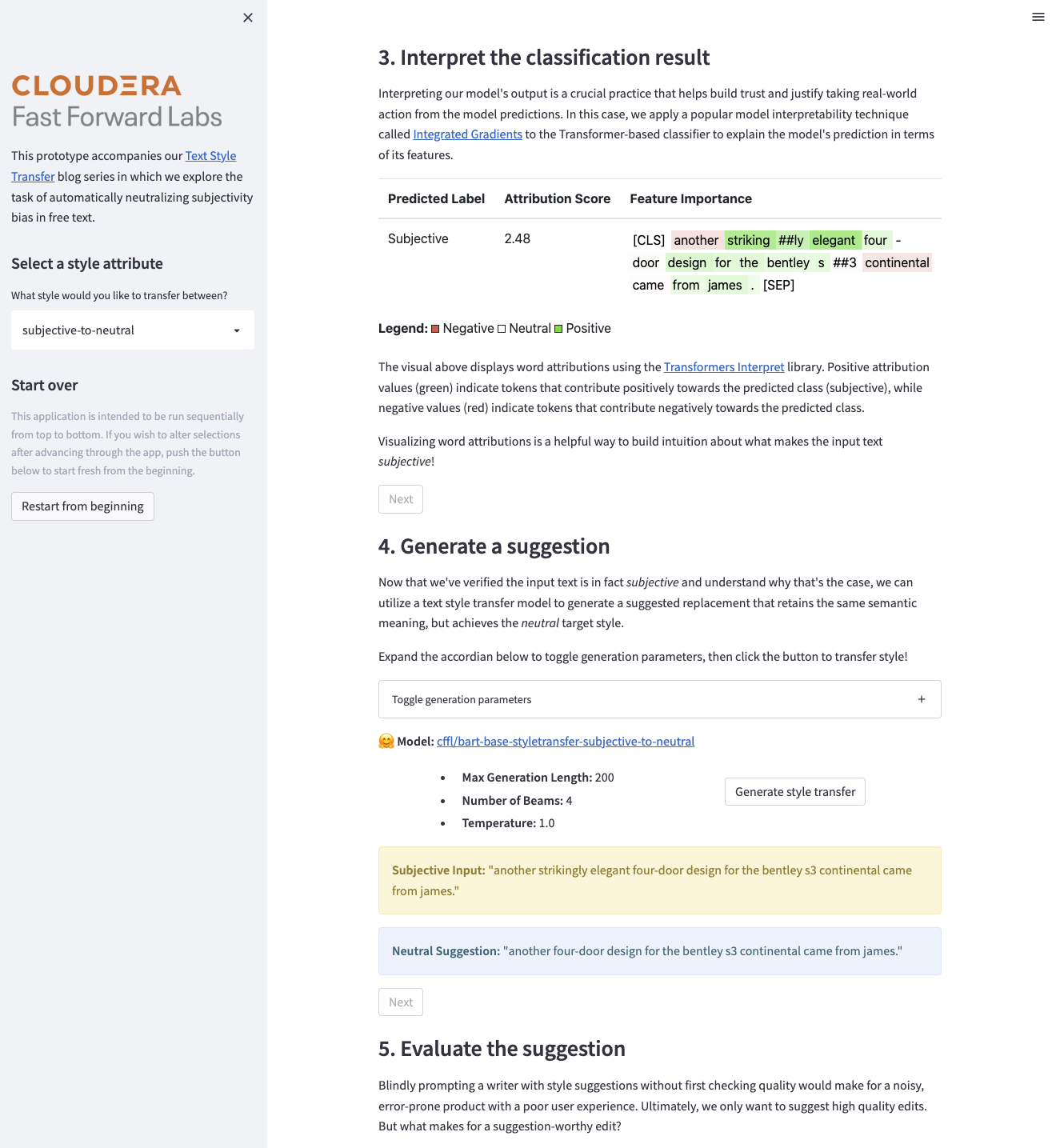 Figure 1: Screenshot of our prototype application: Exploring Intelligent Writing Assistance.
Figure 1: Screenshot of our prototype application: Exploring Intelligent Writing Assistance.
The goal of this application is to peel back the curtains on how an intelligent writing assistant might function — walking through the logical steps needed to automatically re-style a piece of text while building up confidence in the model output.
The user can choose to transfer style between two style attributes: subjective-to-neutral or informal-to-formal. After entering some text (or selecting a preset option), the input is classified to detect if a style transfer is actually needed. Then, an interpretability technique called Integrated Gradients is used to explain the classifier’s predictions in terms of its features, giving the user a look at what lexical components constitute a particular style. Next, the user can generate a style transfer while toggling the sequence-to-sequence model’s decoding parameters. Finally, the generated suggestion is evaluated to provide the user with a measure of quality via two automated metrics: Style Transfer Intensity (STI) and Content Preservation Score (CPS).
Wrapping up
Thanks for tagging along on this NLP journey - we hope you’ve enjoyed following along just as much as we’ve enjoyed researching and writing about this exciting topic. We’ll close out this series with a listing of all project outputs for quick reference.
✍️ Blog Series:
- Part 1: An Introduction to Text Style Transfer
- Part 2: Neutralizing Subjectivity Bias with HuggingFace Transformers
- Part 3: Automated Metrics for Evaluating Text Style Transfer
- Part 4: Ethical Considerations When Designing NLG Systems
🧑💻 Code:
- Research Code - Text Style Transfer: Neutralizing Subjectivity Bias with Huggingface Transformers
- Applied ML Prototype (AMP) - Exploring Intelligent Writing Assistance
🤗 HuggingFace Artifacts:
- Model: Subjective-neutral Style Classification
- Model: Subjective-to-neutral Style Transfer
- Space: Exploring Intelligent Writing Assistance









