Nov 14, 2018 · post
Federated learning: distributed machine learning with data locality and privacy
We’re excited to release Federated Learning, the latest report and prototype from Cloudera Fast Forward Labs.
Federated learning makes it possible to build machine learning systems without direct access to training data. The data remains in its original location, which helps to ensure privacy and reduces communication costs.
This article is about the technical side of federated learning.
If you’d like to learn more:
- Read about the business and product side of federated learning on the Cloudera VISION blog
- Explore our interactive federated learning prototype, Turbofan Tycoon
- Register for our webinar (Thursday, November 15, 2018)
- Get access to the full 85 page report and advising time with the Fast Forward Labs team by becoming a Cloudera Fast Forward Labs client
The federated learning setting
Two things define the federated learning setting.
First, the training data cannot be moved away from its source. The reasons for this constraint can include privacy concerns (I don’t want share my baby photos), regulatory impediments (HIPAA, GDPR, etc.), and practical engineering blockers (the network connection is expensive, slow or unreliable, or the data is too large).
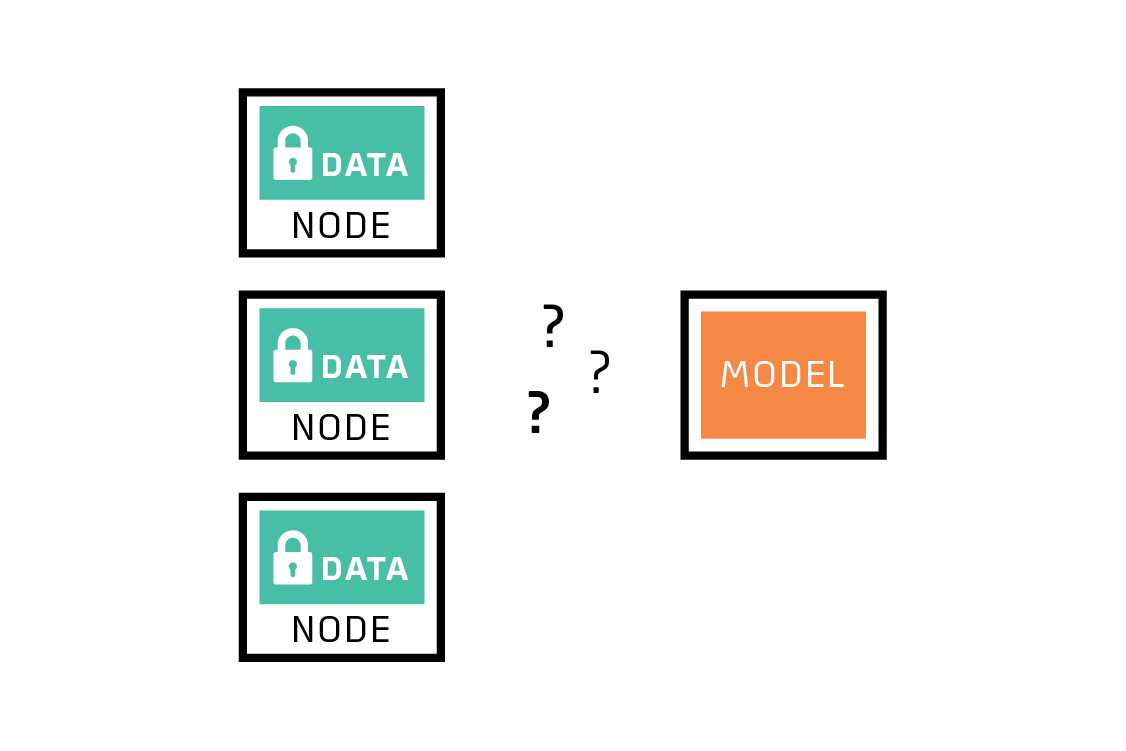
Federated learning helps when the data cannot be moved.
Sometimes we can work around this data locality constraint with proxy data that approximates the behavior of the real data. But almost by definition, proxy data is not as good as the real thing. For example, if you want to train a language model for smartphones, it’s better to train on language typed on smartphones than, for example, the Wikipedia corpus.
Second, in the federated learning setting, each source of potential training data can in principle be different from every other. In other words, the distributions of data on each source are non-IID, and the amount of data at each source can be very different.
In our article on the Cloudera blog, we describe concrete use cases that often have these characteristics: smartphones, healthcare, and predictive maintenance. In this post, we focus on the technical solution.
Federated averaging
“Federated learning” refers to a family of algorithms that attempt to solve machine learning problems in the setting described above. They differ in important details, but share the basic idea: a server coordinates a network of nodes, each of which has training data. The nodes each train a local model, and it is that model which they share with the server.
Let’s be more specific by describing federated averaging, perhaps the simplest form of federated learning. This algorithm was published by a Google team in 2016.
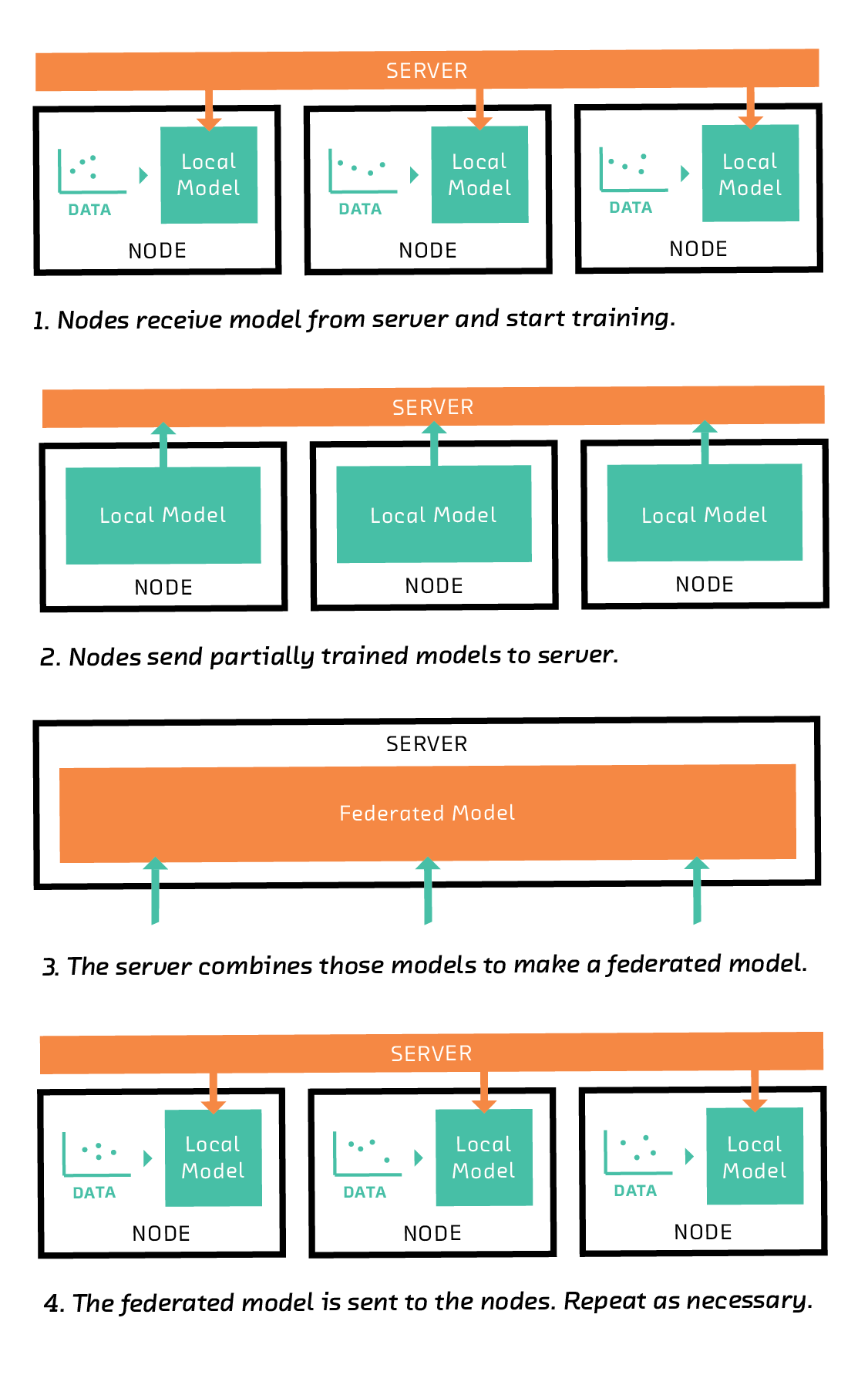
The server first sends each node an instruction to train a model of a particular type, such as a linear model, a support vector machine, or, in the case of deep learning, a particular network architecture.
On receiving this instruction, each node trains the model on its subset of the training data. In general, training a model requires many iterations of an algorithm (such as gradient descent), but in federated learning, the nodes train their models for only a few iterations. In that sense, each node’s model is partially trained after following the server’s instruction. The nodes then send their partially trained models (but not the training data) back to the server.
The server combines the partially trained models to form a federated model. One way to combine the models is to take the average of each coefficient, weighting by the amount of training data available on the corresponding node.
The combined federated model is then transmitted back to the nodes, where it replaces their local models and is used as the starting point for another round of training. After several rounds, the federated model converges to a good global model. From round to round, the nodes can acquire new training data. Some nodes may even drop out, and others may join.
And crucially, the server never has direct access to the training data. By moving models rather than training data, federated learning helps to ensure privacy and minimizes communication costs.
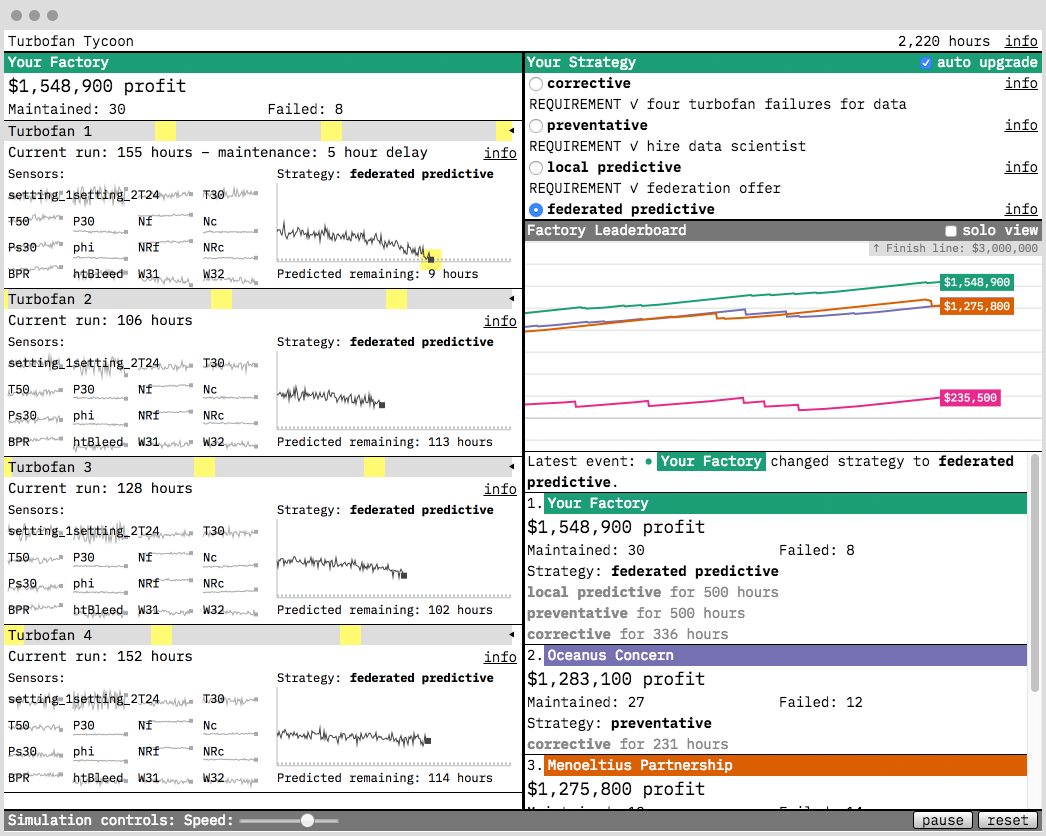
Turbofan Tycoon
Every Cloudera Fast Forward Labs report comes with a prototype. This interactive prototype provides an immediate, intuitive way to understand what the technology can (and cannot!) do. And, in building it, we learn the technical details which we include in the report, and figure out best practices that help us to more effectively advise our clients.
The prototype for our report on Federated Learning is Turbofan Tycoon. In it, you play the owner of a factory that wants to do a better job of maintaining its turbofan engines. Your options are:
- A corrective maintenance strategy (i.e., waiting for the engines to fail)
- A preventative maintenance strategy (i.e., maintaining each engine at a fixed time, hopefully some time before it fails)
- A local predictive maintenance machine learning model, trained only on your failed engines
- A federated predictive maintenance machine learning model, trained on the collective data of 80 factories (including yours), using federated learning
Spoiler alert: the optimal strategy is federated learning, and the ROI relative to the alternatives huge! We hope you enjoy exploring it.
To train the federated model, we wrote an implementation of federated averaging in about 100 lines of PyTorch. This implementation is a simulation of federated learning in the sense that no real network communication takes place. The server and the nodes all exist on one machine. However, it is an algorithmically faithful implementation: the server and nodes communicate only by sending copies of their models to each other.
This approach made it possible for us to experiment rapidly with very large numbers of nodes, without getting bogged down in network issues. And despite the simplification, we can reproduce many of the practical challenges that a real network would face (stragglers, dropped connections, etc.). The models trained on each node (and the federated model that is their average) are simple feed-forward neural networks with one hidden layer. We give more details in the report.
Privacy
By leaving the training data at its source, federated learning plugs the most obvious and gaping security hole in distributed machine learning. But it is important to be clear that it is not a silver bullet.
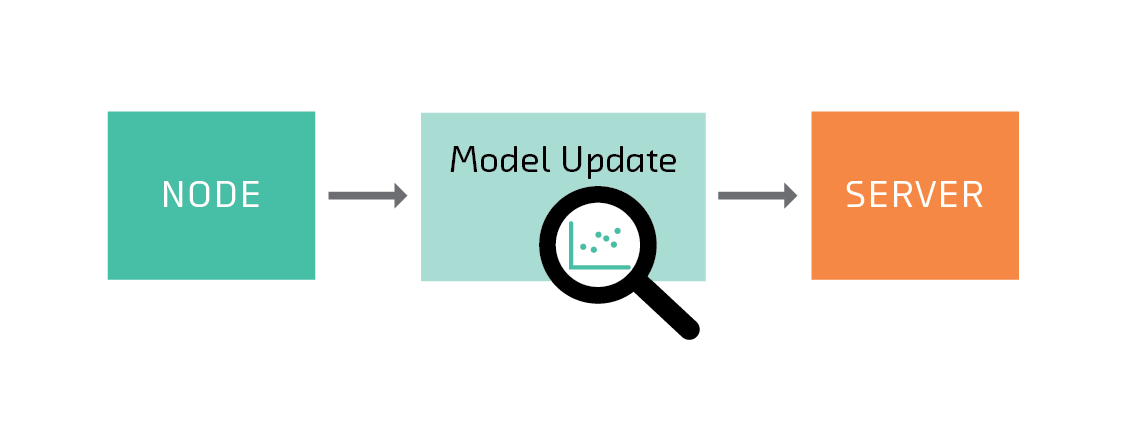
It can be possible to infer information about the data on a node from the models it sends to the server
That’s because it is sometimes possible to infer things about the training data from a model. This problem is not unique to federated learning—any time you share the predictions of a trained model ,you open up this possibility. However, it is worth considering in detail in the context of federated learning for two reasons: first, preserving privacy is one of federated learning’s main goals; second, by distributing training among (potentially untrustworthy) participants, federated learning opens up new attack vectors.
The most indirect way to infer information about the training data requires only the ability to query the model several times. Anyone with indirect access to the model via an API can attempt to attack it in this way. This attack vector is not unique (or any more dangerous) in federated learning. (See, for example, Membership Inference Attacks Against Machine Learning Models and Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures).
The usual protection against this attack is differential privacy. Differential privacy is a large and mathematically formal field with applications far beyond machine learning. But in a production machine learning context, the application of differential privacy generally means that the server adds noise to the model before allowing users to query it. For a modern, accessible, ML-oriented introduction to differential privacy, check out Privacy and Machine Learning: Two Unexpected Allies.
In a federated learning setting where the server and nodes are justified in trusting each other, this type of attack is the only concern. But if the server or nodes are not trustworthy, other kinds of attacks are possible.

Training data (left) can be reconstructed (right) by a malicious node (images taken from “Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning” by Briland Hitaj, Giuseppe Ateniese, and Fernando Perez-Cruz).
For example, the server must be able to directly inspect the node’s model in order to average it. But for certain classes of model, the mere fact that a weight has changed tells you a particular feature was present in the training data. For example, suppose a model takes a bag of words as features, and the tenth word in the vocabulary is “dumplings.” If a node returns a model where the tenth coefficient of the model has changed, the server or an intermediary may be able to infer that the word “dumplings” was present in the training data on that node.
This attack is more difficult to carry out against modern (and more complex) models in practice. The risk can be mitigated by differential privacy (again) or secure aggregation. The differential privacy approach has each node add noise to its model before sharing it with the server (see, e.g., Communication-Efficient and Differentially-Private Distributed SGD) Secure aggregation protocols make it possible for the server to compute the average of the node models using encrypted copies which it does not have the ability to decrypt. Both these approaches add communication and computation overhead, but that may be a trade-off worth making in highly sensitive contexts.
In our webinar, we’ll be learning more about these issues from Andrew Trask of OpenMined and Eric Tramel of Owkin.
Personalization
In “regular” federated learning, the server’s goal is to use the data on every node to train a single global model, but in situations where a node plans to apply the model (not just contribute to its creation), it will usually care much more that the model captures the patterns in its data than any other node’s data. For example, if I’m a node in a network that is training a model that will help write emails that are more likely to receive replies, I care more that the model works for me than if it works for anyone else.
If the global model has an appropriately flexible architecture and was trained on lots of good training data, then it may be better than any local model trained on a single node because of its ability to capture many idiosyncrasies and generalize to new patterns. But it is true that, in principle and sometimes in practice, the user’s goal (local performance) can be in tension with the server’s (global performance).
Resolving this tension is the goal of research into personalization. In Federated Multi-Task Learning, Virginia Smith and collaborators frame personalization as a multi-task problem where each user’s model is a task, but there exists a structure that relates the tasks. Virginia will also be joining us for our webinar.
Conclusion
Federated learning makes it easier, safer, and cheaper to apply machine learning in the world’s most regulated, competitive, and profitable industries. It’s also an area of very active current research, with open problems in privacy, security, personalization, and other areas.
In this article, we’ve only scratched the surface. Our report goes into much more detail, and covers issues not mentioned here (including systems and networking issues, libraries and frameworks, and practical recommendations based on our experience building Turbofan Tycoon). We hope you join the webinar, explore the prototype, and get in touch if you’re interested in working together.
Update: You can watch the recorded webinar here.









