Oct 30, 2019 · newsletter
Exciting Applications of Graph Neural Networks
Graph Neural Networks (GNNs) are neural networks that take graphs as inputs. These models operate on the relational information in data to produce insights not possible in other neural network architectures and algorithms.
While there is much excitement in the deep learning community around GNNs, in industry circles, this is sometimes less so. So, I’ll review a few exciting applications empowered by GNNs.
Overview of Graphs and GNNs
A graph (sometimes called a network) is a data structure that highlights the relationships between components in the data. It consists of nodes (or vertices) and edges (or links) that act as connections between the nodes. Such a data structure has an advantage when dealing with entities that have multiple relationships.
Graph data structures have been around for centuries and their modern use cases are wide. Well-known industry applications of graphs include the social networks of Facebook and LinkedIn, and street and road networks used in navigation apps such as Google Maps and Waze.
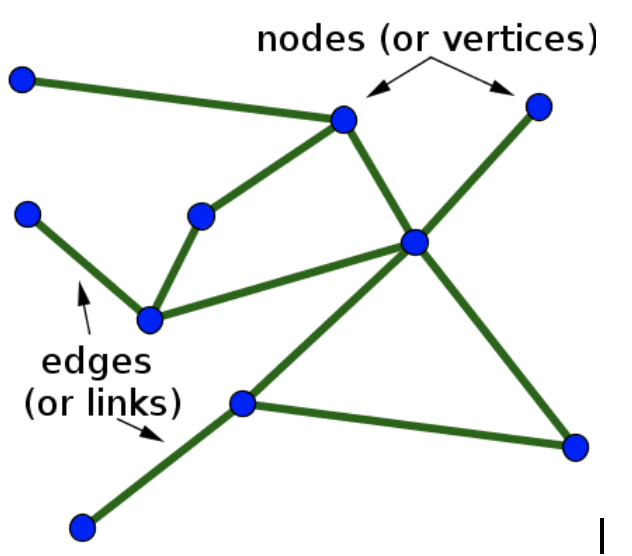
A graph data structure (image credit)
Graph Neural Networks are inspired by deep learning architectures, and strive to apply these to graph structures. Many of these architectures are direct analogues of familiar deep neural net counterparts. These include Graph Convolutional Networks, Graph Encoders and Decoders, Graph Attention Networks, and Graph LSTMs.
GNNs have been around for about 20 years, and interest in them has dramatically increased in the last 5 years. In this time, we’ve seen new architectures emerge, novel applications realized, and new platforms and libraries enter the scene.
Below, I highlight three novel uses of GNNs.
Application 1 - Predict Side-Effects due to Drug Interactions
Every year in the United States, hundreds of thousands of seniors are hospitalized due to the negative side effects of one or more prescribed drugs. Meanwhile, the number of older people prescribed multiple drugs at a time is expanding. Given the proliferation of pharmaceuticals, it is not possible to experimentally test each combination of drugs for interaction effects. In practice, doctors rely on training, understanding a patient’s medical history, and studying literature about the drugs in use to gauge the risk of harmful side effects.
Classification and similarity algorithms have been applied to this problem before, producing interaction scores. These results have been limited for a few reasons. The scores they produce are scalar values that highlight the risk of interaction without characterizing the nature of the interaction. These algorithms are limited to pairs of drugs.
By applying a type of GNN called a Graph Convolutional Network (GCN), a team at Stanford has been able to produce a model that can predict specific drug-drug interaction effects due to the interaction of more than 2 drugs. This model, which outperforms previous methods in identifying such effects, can identify side effects that are not attributed to the individual input drugs.
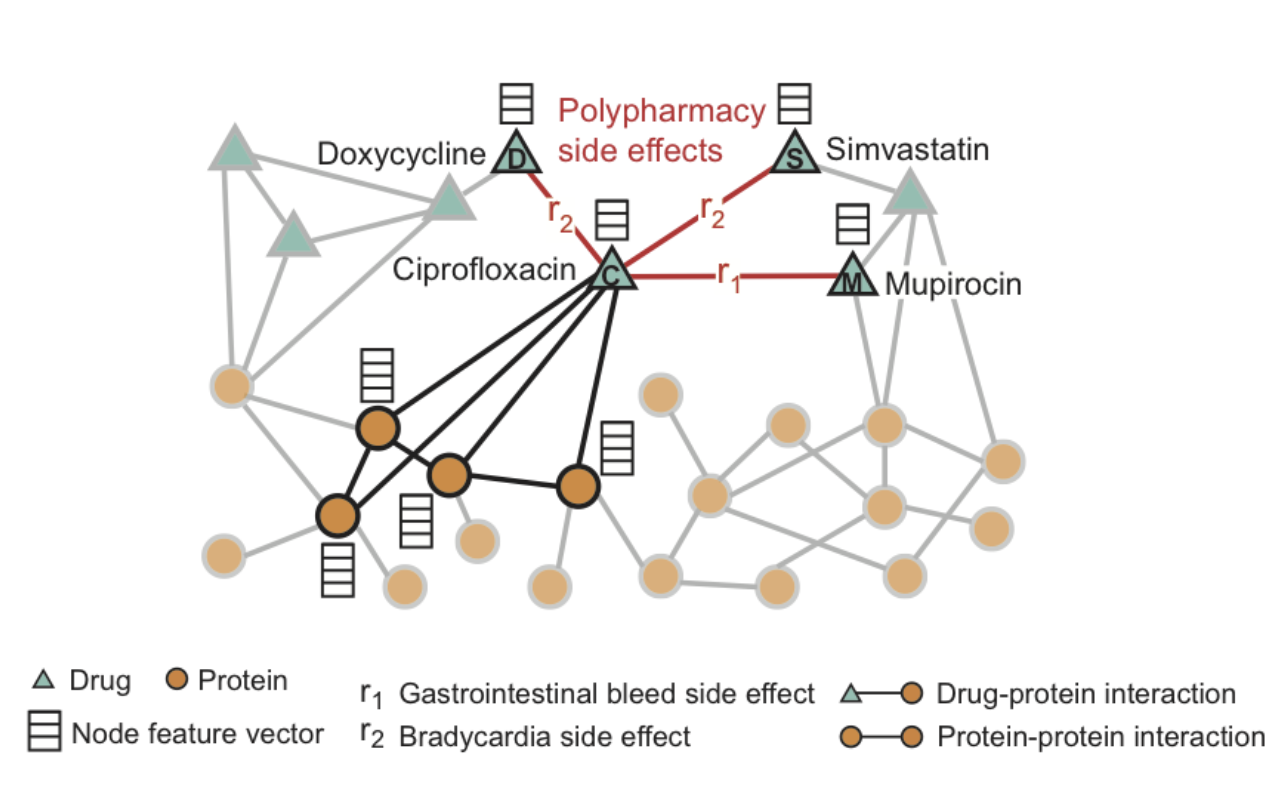
Example of input graph of drug and protein interactions, and side effect edges used to train the Stanford model (image credit)
Application 2 - Node Importance in Knowledge Graphs
The knowledge graphs produced by some enterprise companies are multifaceted, containing context and relationships across several types of entities and objects. Such graphs can contain billions of objects. Amazon is one such company, using knowledge and product graphs to capture the relationships between product data and the critical context that humans have but machines lack. Such graphs enable machines to excel at downstream applications like product recommendations and question answering.
However, at the scale of data that an enterprise uses, sifting through this massive amount of context can time-consuming and will impede graph-enabled applications.
To ameliorate this, Amazon has developed a GNN, called GENI (GNN for Estimating Node Importance), to distinguish the trivial facts and data from critical information contained in a knowledge graph. This algorithm was tested on knowledge graphs of movies, music, and general facts - but has wide ranging implications when applied to large scale graphs.
Application 3 - Enhancing Computer Vision with Physical Intuition
Computer Vision has advanced rapidly with the help of deep learning - in areas of image classification, object detection, and pixel segmentation (among others). Machines can distinguish and identify objects in images and video. There is still much development needed for machines to have the visual intuition of a human.
One type of human intuition is related to physics. If we see a ball bounce, we can reason about its trajectory. Even for more dynamic interactions among several objects, we can make reasonable predictions about what will happen without having a deep knowledge about the laws of motion or Newton’s three laws.
Interactive Networks are now giving machines this same physical intuition. This results in models that can predict what will happen over an extended time, given a few frames of a video scene. An example from DeepMind combines a CNN that distinguishes objects in a scene with an Interactive Network, which reasons about the relationships between these objects. The results of these models have been posted in videos, which are overlaid on CIFAR images. These videos compare the projected trajectories of objects against those predicted by a physics simulator.

Examples of trajectories done by a physics simulator (middle), compared with predicted trajectories over 40-60 video frames (right) (image credit)
Closing Thoughts
The applications discussed above highlight the functional variety of GNNs. In the first application, the GNN solution is used to predict graph edges. In the second, GNNs are used to score the importance of graph nodes. The third application uses GNNs predict the future states of a network.
These 3 applications only scratch the surface of the work being done around GNNs. The growth in this area is accelerating as people try to expand the usage of their existing graph-data. Researchers are also taking data that is in relational or document form, and reframing it in graph structures to take advantage of GNNs and other graph-analytical tools and methods. Though the above examples use GNN architectures for specific purposes, the potential to apply their solutions to similar problems in different domains is exciting.









