Mar 22, 2022 · post
An Introduction to Text Style Transfer
Today’s world of natural language processing (NLP) is driven by powerful transformer-based models that can automatically caption images, answer open-ended questions, engage in free dialog, and summarize long-form bodies of text – of course, with varying degrees of success. Success here is typically measured by the accuracy (Did the model produce a correct response?) and fluency (Is the output coherent in the native language?) of the generated text. While these two measures of success are of top priority, they neglect a fundamental aspect of language – style.
Consider the fictitious scenario where you engage an AI-powered chatbot to assist you with a shopping return for a damaged item. After sharing your intent with the bot, it responds with either of the following generated messages:
- “Give me a picture of the damage.”
- “Could you please send me a picture of the damage?”
While the first option may contain the correct next action (requesting proof of damage) with sound grammer, something about it feels brash and slightly off-putting in a customer experience setting where politeness is highly valued for customer retention. That’s because the expressed tone of politeness plays a critical role in smooth human communication. Of course, this is a non-trivial task for a machine learning model to be aware of as the phenomenon of politeness is rich, multifaceted, and depends on the culture, language, and social structure of both the speaker and addressed person1.
This quick example highlights the importance of personalization and user-centered design in the successful implementation of new technology. For artificial intelligence systems to generate text that is seamlessly accepted into society, it is necessary to model language with consideration for style, which goes beyond merely just expressing semantics. In NLP, the task of adjusting the style of a sentence by rewriting it into a new style while retaining the original semantic meaning is referred to as text style transfer (TST).
This blog post is intended to serve as an introduction to the topic of text style transfer, which is the focus of our most recent research efforts. In particular, we will:
- define text style transfer as machine learning task
- discuss the concept of style in language
- present a few real-world applications of TST
- highlight some of the practical challenges and considerations
Let’s dive in!
What is text style transfer?
Text style transfer is a natural language generation (NLG) task which aims to automatically control the style attributes of text while preserving the content2. To more formally define the task, TST seeks to take the sentence xs with source attribute as as input and produce the sentence xt with target attribute at that retains the style-independent content of xs.

Referencing the chatbot example from the introduction where the style attribute is politeness, we can see how the style of the input sentence with a source attribute of impolite is transferred to have the target attribute of polite. Despite the change in tone, the underlying semantic meaning of the two sentences remains largely unchanged.
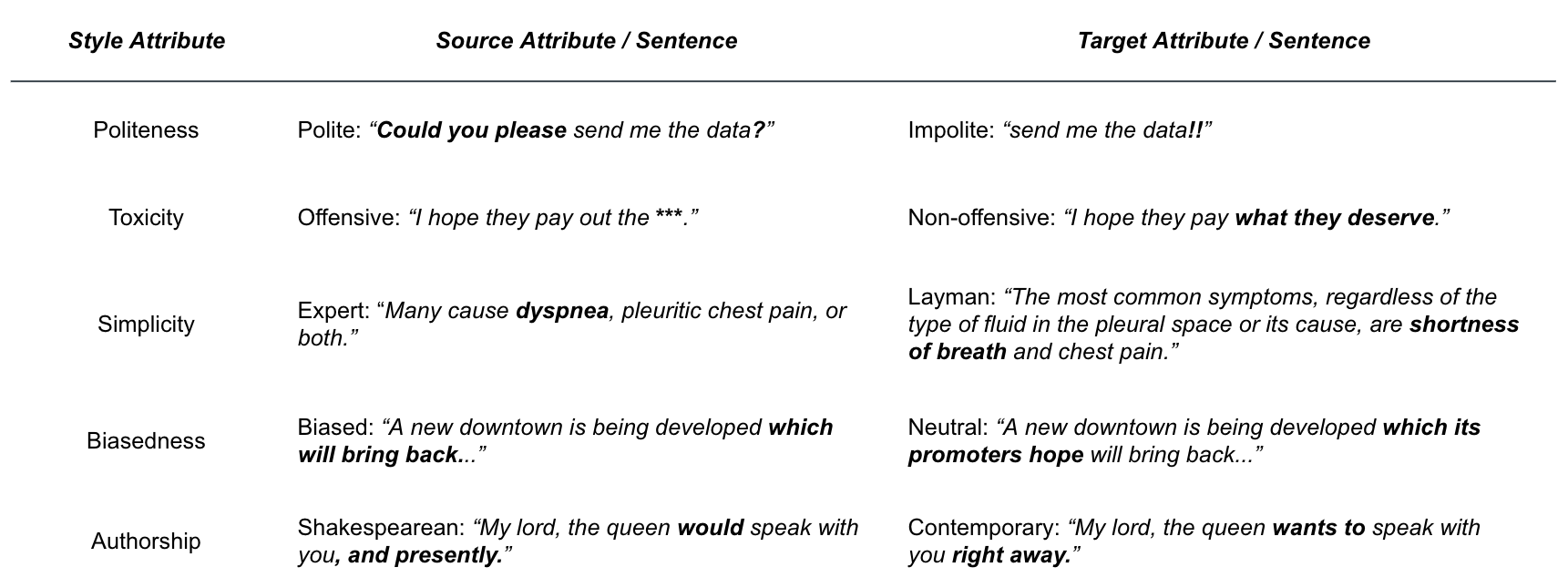
Of course, politeness isn’t the only style attribute which one may seek to control. There is a diverse array of potential style attributes that can be modeled that are largely inspired by pragmatics - a branch of linguistics that studies facets of language that are not directly spoken, but rather implicitly hinted or suggested by a speaker and then interpreted by a reader. Within the domain of TST, there are some commonly explored style attributes such as politeness, formality, humor, emotion, toxicity, simplicity, biasedness, authorship, sentiment, gender, and political slant. The figure below presents illustrative examples for a handful of these common style transfer tasks.
What is style?
In order to frame a discussion around methods for automatically transferring style between two pieces of text, we must first establish some shared understanding of what style actually is and its distinction from content. In general, there are two schools of thought for teasing these apart - a linguistic definition of style and a data-driven definition of style.
The basic idea from a linguistic point-of-view is that a text’s style may be defined as how the author chose to express their content, from among many possible ways of doing so. We can therefore contrast the how of a text (style) from the what (content). Linguists look at hand-selected sets of content-independent features (stylistic devices) such as parts-of-speech, syntactic structures, and clause/sentence complexity measures, that in aggregate, can convey a particular style3. For example, the style attribute of formality is often associated with complex sentence structure, proper punctuation, use of third-person voice, and exclusion of contractions (e.g. you’re, won’t) and abbreviations (e.g TV, photos, SKU). While straightforward to interpret, this “rules-based” definition of style actually constrains what can constitute a style (or not a style) to the known set of stylistic devices that exist.
In contrast, the data-driven definition of style assumes a more generalized approach. In this paradigm, given any two corpora, content is the invariance between them, whereas style is the variance2. If we think of the linguistic definition of style as a handcrafted set of features, then the data-driven definition is a learned set of features. This simple definition of style opens the door to a broader range of indicators that may comprise style outside of just those that linguists have terms for. Of course, this comes with a tradeoff in interpretability as we lose the ability to attribute aspects of style to meaningful, explainable linguistic devices (like use of contractions or abbreviations).
This data-driven definition also encompasses more diverse style attribute types including those where style itself is determined not just by linguistic devices, but also by actual words and topic preferences. For instance, if we analyze our chatbot example from earlier, we could intuit that formulating a sentence as a question rather than a statement lends itself to politeness - something that both the linguistic and data-driven definitions of style could model. However, we could also correctly intuit that the use of the word “please” is indicative of more polite expression – something that the linguistic approach would exclude (because the word “please” isn’t a content-independent feature), but the data-driven approach would capture.
Deep learning architectures commonly used for language modeling today excel at distilling semantic meaning in generalized ways. For that reason, most recent TST work adopts this more encompassing, data-driven definition of style.
Use cases
Text style transfer has many immediate applications in real world use cases today. It also has the potential to support various adjacent NLP tasks like improving data augmentation. Please refer to this survey paper that expands upon the following use cases and more.
Persona-consistent dialog generation
As we’ve already seen, text style transfer can play a critical role in making human-computer interaction more user-centric. People prefer a distinct and consistent persona (e.g. polite, empathetic, etc.) instead of emotionless or inconsistent persona2. Some people appeal more to humor vs. candor vs. drama. TST models could augment NLG pipelines to deliver personalized dialog on an individual user basis.
Intelligent writing assistants
Another industrial application of TST is to enhance the human writing experience. Authors could draft once, but automatically restyle that content to appeal to a variety of audiences - making their ideas more Shakespearean, polite, objective, humorous, or professional.
Text simplification
An inspiring use case for TST is to facilitate better communication between expert and non-expert individuals in certain knowledge domains. For example, automatically simplifying complicated legal, medical, or technical jargon into digestible terminology that a layperson can comprehend, or even lowering language barriers for non-native speakers2.
Neutralizing subjectivity
Subjective messaging in the form of framing, presupposing truth, and casting doubt is ubiquitous in all forms of writing. For certain texts where objectivity is strongly desired - like news, encyclopedias, textbooks - text style transfer could potentially offer a means to neutralize subjective attitudes4.
Challenges and considerations
While the idea of modeling the style of text is not new, it has regained attention in the NLP research community with the advent of Transformer models, and consequently a variety of neural methods for automating the task have been recently proposed. This section will explore some of these approaches, along with the challenges and considerations associated with text style transfer in practice.
Availability of usable data
In general, neural methods for TST can be categorized based on whether the working dataset has parallel text for a given attribute, or non-parallel corpora. Parallel datasets consist of pairs of text (i.e. sentences, paragraphs) where each text in the pair expresses the same meaning, but in a different style. Non-parallel datasets have no paired examples to learn from, but simply exist as mono-style corpora.
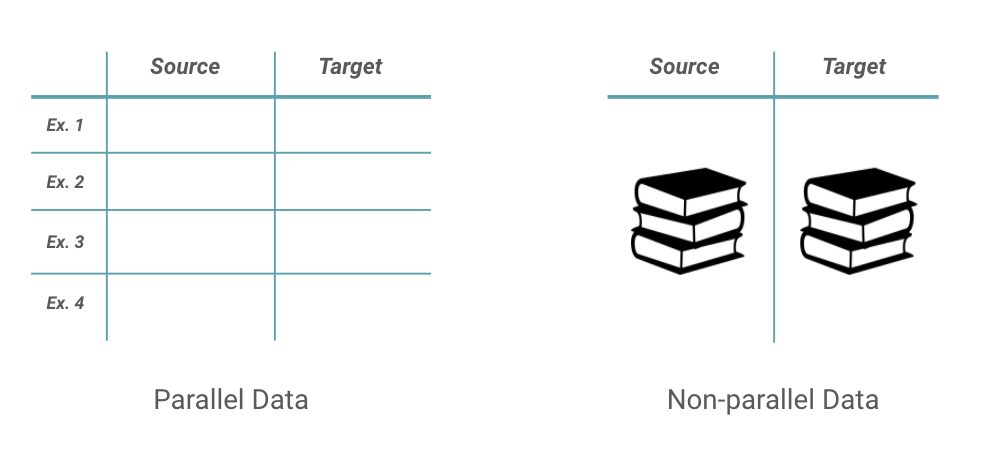
For parallel datasets, TST can be formulated similar to a neural machine translation (NMT) problem where instead of translating between languages, we translate between styles. Most approaches adopt some form of a sequence-to-sequence model using an encoder-decoder architecture. While this approach is rather intuitive, the reality is that parallel datasets are rare to find and very difficult to construct. In combination with data-hungry deep learning models that demand copious training examples, obtaining sufficient parallel data for each desired style attribute presents an (often insurmountable) challenge.
Disentangling style from content
Because of the difficulties with parallel data, much of the ongoing research in TST accepts the requirement of only using non-parallel corpora to model style. Without explicit paired examples, the task becomes increasingly difficult. A variety of approaches exist today that fall into three main buckets:
- Replacement - also referred to as “Prototype Editing”, these methods aim to transfer style explicitly by first identifying components (words, phrases, etc.) of a given sentence that indicate the source style, removing them, and then substituting in new components that represent the target style
- Disentanglement - these methods attempt to implicitly tease apart source attribute style from content in a latent space, and then recombine the content with a new latent representation of style through generative modeling
- Pseudo-parallel corpus construction - tries to reformulate the problem in a supervised manner by creating pseudo-parallel examples from the non-parallel dataset using various tricks such as extracting/matching similar sentences from each corpora as pairs
At the core of all these approaches lies a fundamental question about TST: Is it actually possible to disentangle style from content? Or is content itself a factor that makes up style?
It seems the answer somewhat depends on the style attribute being considered and the definition of style adopted. For example, it has been argued that politeness is an interpersonal style that can be decoupled from content1. In contrast, it feels misguided to say that the style of sentiment can be separated from content when altering a sentence’s polarity from positive to negative directly changes its semantic meaning.
Overall, this idea of disentangling style from content has been widely discussed in the TST community and remains an open research question5.
Evaluation
While the descriptions of parallel and non-parallel methods above may be oversimplifications of the actual approaches, it remains apparent how difficult such a task is. To add to the complexity of the problem, TST adopts all of the evaluation challenges faced in general natural language generation tasks, plus some.
To fundamentally evaluate the effectiveness of a NLG output, we must quantify how semantically accurate the generated text was (i.e Did the model say the right thing?), and also how fluent the output is (i.e. Was the thing comprehensible in native language?). The accuracy metric here needs to determine how well the semantic meaning was preserved in the output. For TST specifically, we also need to ensure the target style was achieved. In the end, comprehensive TST evaluation should consider three criteria - transferred style strength, semantic preservation, and fluency - which often requires human evaluation because automated metrics alone do not adequately characterize these complex properties.
Ethical Concerns
Because text style transfer exists at the crux of generative modeling and personalization, it is imperative that ethical considerations are brought to the forefront of any research agenda. In particular, it’s prudent to scrutinize both the beneficial and harmful ways in which a technology might be adopted as it may have far-reaching negative consequences.
For example, text style transfer has the potential to help reduce toxicity, hate-speech, and cyberbullying from online social platforms by modeling non-offensive text; a task that currently requires laborious effort via manual content moderation. However, should this technology prove successful, malicious users could just as easily repurpose such methods to model the opposite attribute - generating hateful, offensive text - which counteracts any intended social benefit.
Another example is seen in modeling political slant. A successful endeavor here raises obvious concerns as the ability to automatically transfer attitude and messaging between liberal and conservative tones has the potential to exploit political views of the masses if used for a malevolent social engineering agenda.
These types of task-specific ethical concerns exist in addition to those present with any NLG task – like encoded social bias or generated factual inconsistencies.
Wrapping up
Text style transfer is an exciting task that’s gaining attention in the NLP research community due to its challenging nature and numerous real-world applications. We offer this introduction to the topic as Part 1 of a multi-part blog series where we will be experimenting with TST by training and evaluating our own models. Along the way we plan to discuss our approach, implementation details, challenges, and learnings – stay tuned!









