Jun 10, 2016 · interview
Machine Listening: Interview with Juan Pablo Bello
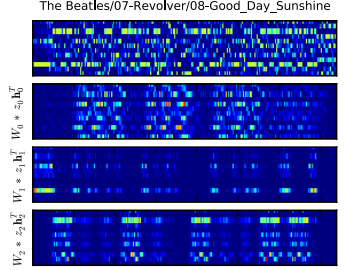
A probabilistic latent component analysis of a pitch class sequence for The Beatles’ Good Day Sunshine. The top layer shows the original representation (time vs pitch class). Subsequent layers show latent components.
What is music? Or rather, what differentiates music from noise?
If you ask John Cage, “everything we do is music.” Forced to sit silently for 4’33”, we masters of apophenia end up hearing music in noise (or just squirm in discomfort…), perceiving order and meaning in sounds that normally escape notice. For Cage, music is in the ears of the listener. To study it is to study how we perceive.
But Cage wrote 4’33” at time when many artists were challenging inherited notions of art. Others, dating back to Pythagoras (who defined harmony in terms of ratios and proportions), have defined music through the structural properties that make music music, and separate different musical styles.
The latest efforts to understand music lie in the field of machine listening, where researchers use computers to analyze audio data to identify meaning and structure in it like humans do. Some machine listening researchers analyze urban and environmental sounds, as at SONYC.
This August in NYC, researchers in machine listening and related fields will convene at the International Society for Music Information Retrieval (ISMIR) conference. The conference is of interest to anyone working in data or digital media, offering practical workshops and hackathons for the NYC data community.
We interviewed NYU Steinhardt Professor Juan Pablo Bello, an organizer of ISMIR 2016 working in machine listening, to learn more about the conference and the latest developments in the field. Keep reading for highlights!
What is machine listening and why is music challenging to work with?
Machine listening is a field of engineering, computer science, and data science focused on identifying structures in audio data that have meaning. These may be sounds in speech, music, urban or natural environments. Music is difficult because there is no universal model that could be reasonably applied to everything people label as music. Natural language is also fluid, but most of the time, models are constrained by the fact that people use natural language with the goal of conveying meaning unambiguously (literature, poetry, and humor aside). We can therefore get somewhere with embeddings like word2vec or Skip-Thought Vectors. With music, ambiguity and context are part of the game. Many composers challenge existing preconceptions of what music is or should be, seeking continuously to manipulate listeners’ sense of surprise and expectation. For example, Debussy, the French impressionist composer, quoted leitmotifs from Wagner, but doing so, transformed something ultra serious into something ironic. Fifty years was enough to change what those same sounds meant to people. I work primarily in popular contemporary music, where musicians cover songs and steal riffs all the time. It even poses algorithmic challenges to recognize the same song in a live performance and recording, or as interpreted by different musicians. One of the primary goals is to create algorithms that can embrace ambiguity, variation, and interpretation.
What’s the history of the field and how has it evolved over the years?
The field started in earnest in the late 90s in digital music libraries. At the time, the focus was on symbolic data, and researchers built expert systems using music theory concepts to analyze scores. In the early 2000s, the field shifted drastically in the wake of advances in speech processing. We threw aside symbolic information and rules based on music theory, and adopted a data-driven, statistical approach. That approach largely dominates to this day, with advances from feature learning and deep learning (both convolutional and recurrent nets) over the past few years. While deep nets excel at telling us what is in the data, however, we’re seeing limits where models overfit existing biases in our data sets. So, we’re trying to expand our approaches to embrace the possibility of multiple interpretations of the same information. There’s also a growing realization that data-driven techniques alone can only get us so far, that we’re shooting ourselves in the foot if we ignore the knowledge in music theory and theories of cognition. Some researchers, in turn, are trying to develop models with more emphasis on how we process information ourselves, how we interpret the structures that we understand as music.
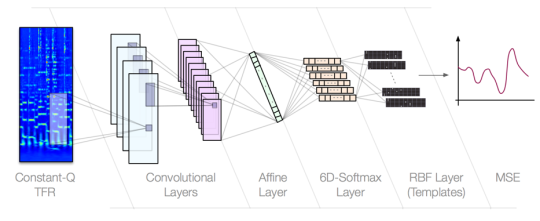
A CNN for automatic chord estimation. The second to last layer is designed to recreate a guitar neck such that only one fret per string can be activated at any given time. The network is not only able to estimate chords, but also automatically generate a human-readable guitar tab from an audio recording.
How much data do you use to train your models?
There are two data challenges in music machine listening. First, access to data is often restricted by copyright laws. Second, data is often more complicated to label than, say, labeling images to train a neural net for image analysis (as Fast Forward Labs explored in Pictograph). There are only so many trained musicians motivated to listen to pieces of music and label structures, who can identify higher-order features like the intro, chorus, verse, verse with variations, and bridge that make up many pop songs. What counts as meaning and structure in music often extends along a relatively long time series. We do have some tricks we can use to gather more data useful for training. For example, with multi-track recordings, we can separate out melodic tracks before they’re mixed and then run pitch estimators on individual sources to characterize frequency values in a sequence. We’ve found the results have decent accuracy, and we can add a human in the loop to correct if needed. So, basically, the data can be small - it’s nothing compared to what you see in speech recognition.
Are research groups at companies like Pandora or Spotify adopting different techniques given their access to large proprietary datasets?
These companies are doing some unique work. Take Pandora: they have 50-60 trained musicians on staff who categorize music according to a rich questionnaire. They’ve created a set of hand-labeled music data no one else has, with very precise information on 1.5-2 million tracks. They can now use approaches from music information retrieval (MIR) to propagate this knowledge across much larger collections to support personalization and recommendation efforts. Spotify, by contrast, has been powered from the start by data science approaches like collaborative filtering applied to tens of millions of tracks. Since acquiring The Echo Nest, they’ve added cutting-edge content- and context-based analysis, including recent explorations with deep nets.
What probabilistic techniques have researchers used to get a better handle on ambiguity?
There’s interesting work I could mention using, for example, Conditional Random Fields (classification and prediction models that take the context of neighborhood data into account in their output) and Markov Logic Networks (first-order knowledge bases with a weight attached to each formula). In music, we can use the Markov networks to encode knowledge about music theory, but also use the probabilities and weights to reconcile the gap between the theory and data. As mentioned, it’s normally quite hard to get a generalizable model. Some years ago, there was also interesting work using Dynamic Bayesian Networks, a type of graphical model that performs well on sequential data (like music, speech recognition, financial forecasting, etc.). There were interesting advances applying music theory to drive network design here, but the models were both slow and hard to train. Deep nets are an easier to scale alternative, but there is work to be done in leveraging higher-level music knowledge for model design.
I also think there is interesting work to be done leveraging long-term structure in music to inform probabilistic techniques. The accuracy of automatically extracting melody, for example, varies across the length of a recording as a function of changes in harmony, instrumentation, or rhythm. We can, however, use long-term structures - particularly repetitive structures - to increase the confidence of our estimations in more challenging musical contexts. (The Fast Forward Labs team thought along similar lines to manage low confidence in image recognition tasks.)
What is one important challenge algorithms have yet to solve?
Music has multiple layers: there is some level of structure at its surface, but there is a lot of meaning that is derived not from content, but context. This could be references to past music (Weezer covering Toni Braxton) or current cultural events (Bob Dylan on Muhammad Ali). Basically, you have to be in the joke to understand it, which is something useful for recommender systems. But we’re really far away from being able to model context with computational approaches.
You mentioned that the big revolution in the field in the early 2000s resulted from advances in speech processing. What other developments have been inspired by adopting techniques from other disciplines?
The influx of probabilistic methods is partly inspired by advances in bioinformatics and financial time series analysis. From physics, we’ve played with recurrence analysis for nonlinear, complex systems. Given all the rage with image processing, we have been applying convolutional neural nets (CNNs) with little to no adaptation to the specificities of audio. Images have relatively high covariance for pixels in the same neighborhood, as color gradients change gradually and objects are localized in space. The same doesn’t necessarily hold for sound “objects” in a spectrogram, where energy at various non-contiguous frequencies combine to produce pitch, timbre and rhythm. Moreover, CNNs do a good job encoding shorter temporal patterns, but lack the LSTM features of recurrent nets that do better with longer data sequences. Recent work using recurrent nets for music has shown tremendous promise, but it is still early days. As such, there are adjustments you can make to render nets more amenable to analyze music and sound.
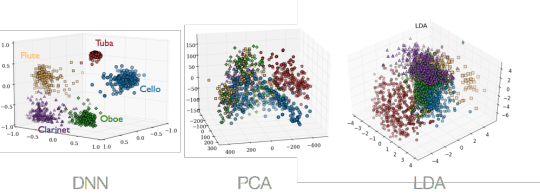
A non-linear embedding of instrumental sounds in 3D. The embedding is generated using CNNs trained to minimize the pairwise distance between samples of the same instrument class. The embedding is compared to alternative projections from standard audio features using PCA and LDA.
What is ISMIR and what’s special about this year’s conference?
ISMIR is an annual conference devoted to the MIR field. This is the 17th year! It’s a very heterogenous gathering that brings together researchers across disciplines to explore ideas, present the latest and greatest developments in the field, and stay informed.
This year we made strong efforts on two fronts. First, we worked hard to connect with other academic communities such as music cognition and musicology, as well as the data science community at large: we have a hackathon as part of the conference proceedings, tutorials to introduce music information retrieval to people outside the community, and a demo session where people can see cutting-edge work that may not be published yet. These events are open to the public. Next, we have strengthened our outreach to industry, developing a strong partnership program, and implementing a workshop that exposes graduate students to the skills needed to succeed in industrial settings. We hope to provide them with a better picture of what their research would look like at scale at any of the many companies actively involved in the field.
What future developments are you most excited about?
We’ve made progress of late expanding our corpus beyond the Western classical canon and pop music into a wider diversity of styles from across the world. I recently published an article about rhythm in Latin American music (dear to my heart, as a Venezuelan native). Others are exploring similarities in music across cultures, from Andalusia to Turkey to Chinese opera in Beijing. It’s exciting to apply algorithmic techniques to world music because, for many of these traditions, we often don’t have significant corpora of written scores as with Western classical music. There are whole troves of knowledge ripe for exploration.
I haven’t done much with music generation, but am very interested in it, as it is the natural complement to the analysis I focus on. Developing machines that are able to produce realistic musical outputs is the ultimate test of the validity and generalizability of our analytical models of music. Music is unique amongst sound classes in its careful design, in how intricate and deliberate its patterns are, both at short and long temporal scales. Existing music-making machines do a good job modeling short-term structures, but often lack the sense of strategy or purpose that is only realized at longer time scales (and is crucial to keeping listeners engaged and invested). This is a very hard problem to solve. Previous generative work, even the groundbreaking work of David Cope or Tristan Jehan, can get boring and repetitive, and is often bounded within strong stylistic constraints. But there are exciting new developments in this area, such as Google’s Magenta project and Kyle McDonald’s work, and I’m curious to see where all of this will go in the not-so-distant future!









