Aug 26, 2016 · guest post
Exploring Deep Learning on Satellite Data
This is a guest post featuring a project Patrick Doupe, now a Senior Data Analyst at Icahn School of Medicine at Mount Sinai, completed as a fellow in the Insight Data Science program. In our partnership with Insight, we occassionally advise fellows on month-long projects and how to build a career in data science.
Machines are getting better at identifying objects in images. These technologies are used to do more than organise your photos or chat your family and friends with snappy augmented pictures and movies. Some companies are using them to better understand how the world works. Be it by improving forecasts on Chinese economic growth from satellite images of construction sites or estimating deforestation, algorithms and data can help provide useful information about the current and future states of society.
In early 2016, I developed a prototype of a model to predict population from satellite images. This extends existing classification tasks, which ask whether something exists in an image. In my prototype, I ask how much of something not directly visible is in an image? The regression task is difficult; current advice is to turn any regression problem into a classification task. But I wanted to aim higher. After all, satellite image appear different across populated and non populated areas.

The prototype was developed in conjuction with Fast Forward Labs, as my project in the Insight Data Science program. I trained convolutional neural networks on LANDSAT satellite imagery to predict Census population estimates. I also learned all of this, from understanding what a convolutional neural network is, to dealing with satellite images to building a website within four weeks at Insight. If I can do this in a few weeks, your data scientists too can take your project from idea to prototype in a short amount of time.
LANDSAT-landstats
Counting people is an important task. We need to know where people are to provide government services like health care and to develop infrastructure like school buildings. There are also constitutional reasons for a Census, which I’ll leave to Sam Seaborn.
We typically get this information from a Census or other government surveys like the American Community Survey. These are not perfect measures. For example, the inaccuracies are biased against those who are likely to use government services.
If we could develop a model that could estimate the population well at the community level, we could help government services better target those in need. The model could also help governments that facing resources constraints that prevent the running of a census. Also, if it works for counting humans, then maybe it could work for estimating other socio-economic statistics. Maybe even help provide universal internet access. So much promise!
So much reality
Satellite images are huge. To keep the project manageable I chose two US States that are similar in their environmental and human landscape; one State for model training and another for model testing. Oregon and Washington seemed to fit the bill. Since these states were chosen based on their similarity, I thought I would stretch the model by choosing a very different state as a tougher test. I’m from Victoria, Australia, so I chose this glorious region.
Satellite images are also messy and full of interference. To minimise this issue and focus on the model, I chose the LANDSAT Top Of Atmosphere (TOA) annual composite satellite image for 2010. This image is already stitched together from satellite images with minimal interference. I obtained the satellite images from the Google Earth Engine. I began with low resolution images (1km) and lowered my resolution in each iteration of the model.
For the Census estimates, I wanted the highest spatial resolution, which is the Census block. A typical Census block contains between 600 and 3000 people, or about a city block. To combine these datasets I assigned each pixel its geographic coordinates and merged each pixel to its census population estimates using various Python geospatial tools. This took enough time that I dropped the bigger plans. Best get something complete than a half baked idea.
A very high level overview of training Convolutional Neural Networks
The problem I faced is a classic supervised learning problem: train a model on satellite images to predict census data. Then I could use standard methods, like linear regression or neural networks. For every pixel there is number corresponding to the intensity of various light bandwidths. We then have the number of features equal to the number of bandwidths by the number of pixels. Sure, we could do some more complicated feature engineering but the basic idea could work, right?
Not really. You see, a satellite image is not a collection of independent pixels. Each pixel is connected to other pixels and this connection has meaning. A mountain range is connected across pixels and human built infrastructure is connected across pixels. We want to retain this information. Instead of modelling pixels independently, we need to model pixels in connection with their neighbours.
Convolutional neural networks (hereafter, “convnets”) do exactly this. These networks are super powerful at image classification, with many models reporting better accuracy than humans. What we can do is swap the loss function and run a regression.
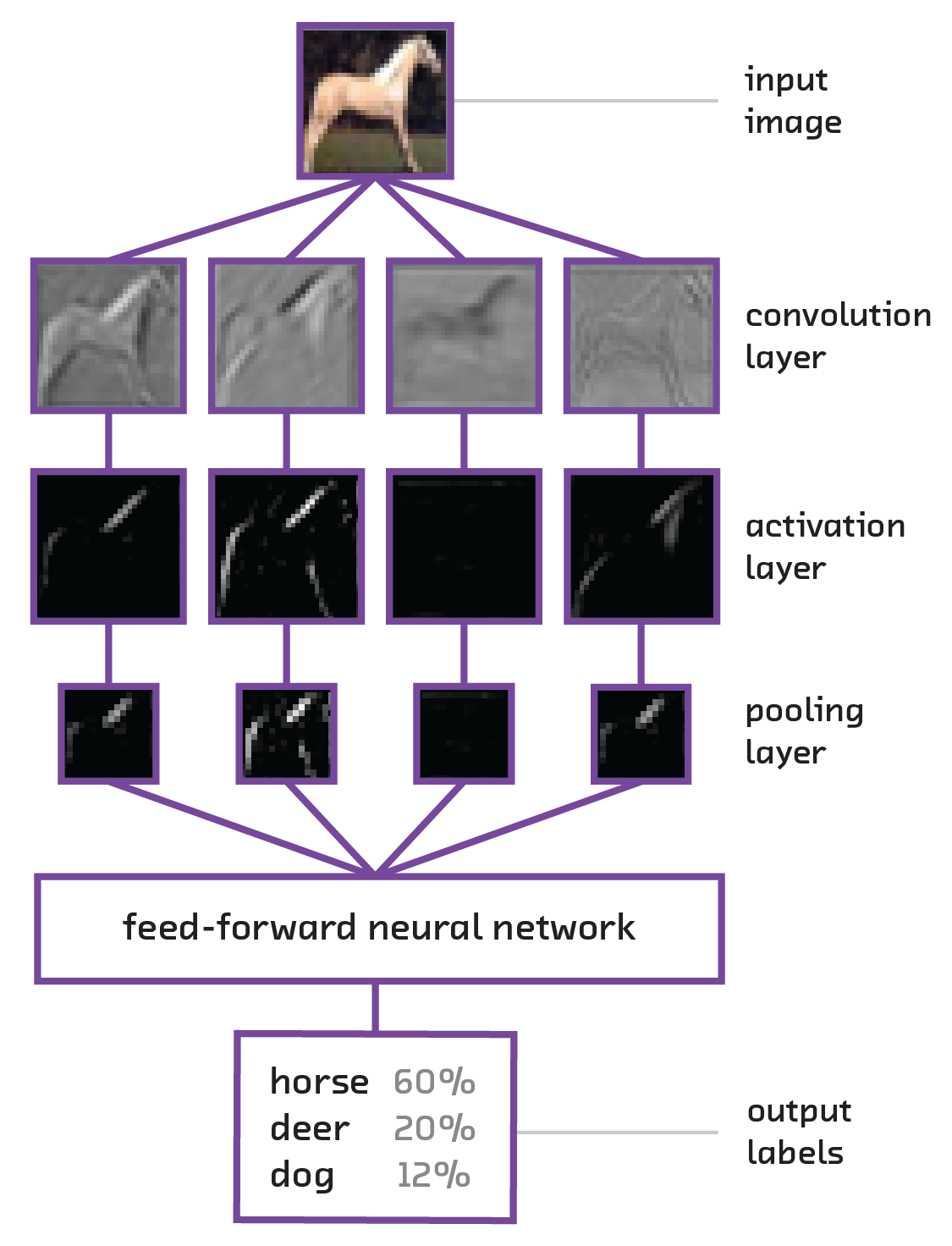 ##### Diagram of a simple convolutional neural network processing an input image. From Fast Forward Labs report on Deep Learning: Image Analysis
##### Diagram of a simple convolutional neural network processing an input image. From Fast Forward Labs report on Deep Learning: Image Analysis
Training the model
Unfortunately convnets can be hard to train. First, there are a lot of parameters to set in a convnet: how many convolutional layers? Max-pooling or average-pooling? How do I initialise my weights? Which activations? It’s super easy to get overwhelmed. Micha suggested I use the well known VGGNet as a starting base for a model. For other parameters, I based the network on what seemed to be the current best practices. I learned these by following this winter’s convolutional neural network course at Stanford.
Second, they take a lot of time and data to train. This results in training periods of hours to weeks, while we want fast results for a prototype. One option is to use pre-trained models, like those available at the Caffe model zoo. I was writing my model using the Keras python library, which at present doesn’t have as large a zoo of models. Instead, I chose to use a smaller model and see if the results pointed in a promising direction.
Results
To validate the model, I used data from on Washington and Victoria, Australia. I show the model’s accuracy on the following scatter plot of the model’s predictions against reality. The unit of observation is the small image-observation used by the network and I estimate the population density in an image. Since each image size is the same, this is the same as estimating population. Last, the data is quasi log-normalised[6]. Let’s start with Washington
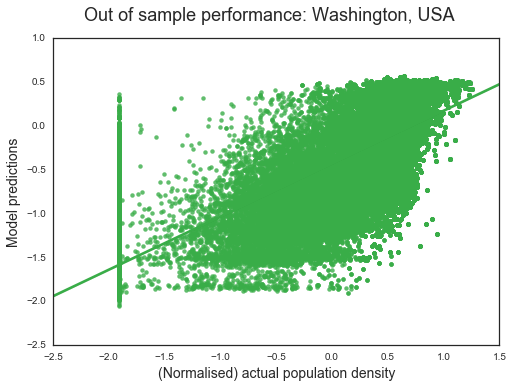 ##### Washington State
##### Washington State
We see that the model is picking up the signal. Higher actual population densities are associated with higher model predictions. Also noticeable is that the model struggles to estimate regions of zero population density. The R2 of the model is 0.74. That is, the model explains about 74 percent of the spatial variation in population. This is up from 26 percent in the four weeks achieved in Insight.
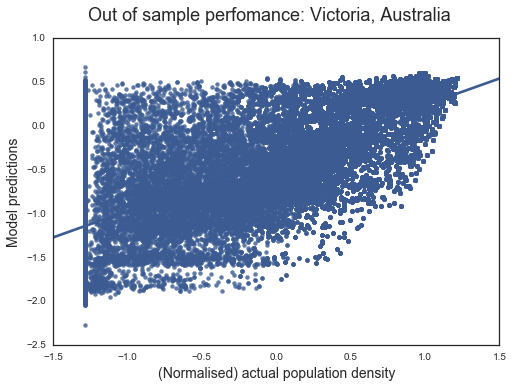 ##### Victoria
##### Victoria
A harder test is a region like Victora with a different natural and built environment. The scatter plot of model performance shows the reduced performance. The model’s inability to pick regions of low population is more apparent here. Not only does the model struggle with areas of zero population, it predicts higher population for low population areas. Nevertheless, with an R2 of 0.63, the overall fit is good for a harder test.
An interesting outcome is that the regression estimates are quite similar for both Washington and Victoria: the model consistently underestimates reality. In sample, we still have a model that underestimates population. Given that the images are unlikely to have enough information to identify human settlements at current resolution, it’s understandable that the model struggles to estimate population in these regions.
| Variable | A perfect model | Washington | Victoria | Oregon (in sample) |
|---|---|---|---|---|
| Intercept | 0 | -0.43 | -0.37 | -0.04 |
| Slope | 1 | 0.6 | 0.6 | 0.86 |
| R2 | 1 | 0.74 | 0.63 | 0.96 |
Conclusion
LANDSAT-landstats was an experiment to see if convnets could estimate objects they couldn’t ‘see.’ Given project complexity, the timeframe, and my limited understanding of the algorithms at the outset, the results are promising. We’re not at a stage to provide precise estimates of a region’s population, but with improved image resolution and advances in our understanding of convnets, we may not be far away.
-Patrick Doupe









