Jan 18, 2017 · post
New Research on Probabilistic Programming

We’re excited to release the latest research from our machine intelligence R&D team!
This report and prototype explore probabilistic programming, an emerging programming paradigm that makes it easier to construct and fit Bayesian inference models in code. It’s advanced statistics, simplified for data scientists looking to build models fast.
Bayesian inference has been popular in scientific research for a long time. The statistical technique allows us to encode expert knowledge into a model by stating prior beliefs about what we think our data looks like. These prior beliefs are then updated in light of new data, providing not one prediction, but a full distribution of likely answers with baked-in confidence rates. This allows us to asses the risk of our decisions with more nuance.
Bayesian methods lack widespread commercial use because they’re tough to implement. But probabilistic programming reduces what used to take months of thorny statistical sampling into an afternoon of work.
This will further expand the utility of machine learning. Bayesian models aren’t black boxes, a criterion for regulated industries like healthcare. Unlike deep learning networks, they don’t require large, clean data sets or large amounts of GPU processing power to deliver results. And they bridge human knowledge with data, which may lead to breakthroughs in areas as diverse as anomaly detection and music analysis.
Our work on probabilistic programming includes two prototypes and a report that teaches you:
- How Bayesian inference works and where it’s useful
- Why probabilistic programming is becoming possible now
- When to use probabilistic programming and what the code looks like
- What tools and languages exist today and how they compare
- Which vendors offer probabilistic programming products
Finally, as in all our research, we predict where this technology is going, and applications for which it will be useful in the next couple of years.
Probabilistic Real Estate Prototype
One powerful feature of probabilistic programming is the ability to build hierarchical models, which allow us to group observations together and learn from their similarities. This is practical in contexts like user segmentation: individual users often shares tastes with other users of the same sex, age group, or location, and hierarchical models provide more accurate predictions about individuals by leveraging learnings from the group.
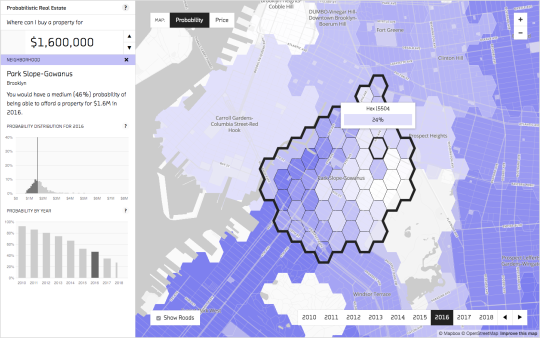
We explored using probabilistic programming for hierarchical models in our Probabilistic Real Estate prototype. This prototype predicts future real estate prices across the New York City boroughs. It enables you to input your budget (say $1.6 million) and shows you the probability of finding properties in that price range across different neighborhoods and future time periods.
Hierarchical models helped make predictions in neighborhoods with sparse pricing data. In our model, we declared that apartments are in neighborhoods and neighborhoods are in boroughs; on average, apartments in one neighborhood are more similar to others in the same location than elsewhere. By modeling this way, we could learn about the West Village not only from the West Village, but also from the East Village and Brooklyn. That means, with little data about the West Village, we could use data from the East Village to fill in the gaps!
Many companies suffer from imperfect, incomplete data. These types of inferences can be invaluable to improve predictions based on real-world dependencies.
Play around with the prototype! You’ll see how the color gradients give you an intuitive sense for what probability distributions look like in practice.









