Nov 30, 2017 · newsletter
The promise of Automated Machine Learning (AutoML)
Earlier this month The New York Times published an article on Building A.I. That Can Build A.I.. There is a lot of excitement about AutoML due to the scarcity of machine learning (ML) talent:
By some estimates, only 10,000 people worldwide have the education, experience and talent needed to build the complex and sometimes mysterious mathematical algorithms that will drive this new breed of artificial intelligence.
Furthermore, ML/AI experts are expensive: Tech Giants Are Paying Huge Salaries for Scarce A.I. Talent. AutoML promises more ML at lower cost; it is an enticing offering.
The multiple meanings of AutoML
That said, the realistic promise of new capabilities is hard to grasp. There are at least three different notions of AutoML:
- Citizen Data Science / ML: AutoML will allow everyone to do data science and ML. It requires no special training or skills.
- Efficient Data Science / ML: AutoML will supercharge your data scientists and ML engineers by making them more efficient.
- Learning to Learn: AutoML will automate architecture and optimization algorithm design (much like neural networks automated feature engineering).
We could add a fourth:
- Transfer Learning: AutoML will allow algorithms to learn new tasks faster by utilizing what they have learned from mastering other tasks in the past.
Google Brain’s AutoML project is about Learning to Learn:
Typically, our machine learning models are painstakingly designed by a team of engineers and scientists. This process of manually designing machine learning models is difficult because the search space of all possible models can be combinatorially large — a typical 10-layer network can have ~1010 candidate networks! For this reason, the process of designing networks often takes a significant amount of time and experimentation by those with significant machine learning expertise.
Learning to learn is very exciting! But it requires extensive computational resources for model training, the kind Google has access to, but not many others. By providing access to (cloud) compute power, of course, AutoML as Learning to Learn is an excellent strategy to monetize Google’s cloud compute offering; Google has an excellent business case for investing time and resources into the AutoML project (of course). But experts suugest it will take a while before the promise of AutoML as Learning to Learn will materialize:
Renato Negrinho, a researcher at Carnegie Mellon University who is exploring technology similar to AutoML, said this was not a reality today but should be in the years to come. “It is just a matter of when,” he said.
We agree. So how about the promise of the other notions of AutoML?
There are data science and ML platform vendors that promise to automate data science and ML to the extent that Citizen Data Science / ML may soon became real (e..g, DataRobot). Data science and ML practitioners, however, are skeptical about the promise of Citizen Data Science (and, frankly, worried about some of its outputs and consequences).
We believe AutoML as Efficient Data Science / ML shows real promise for the largest number of companies within the near to midterm future. There is ample opportunity to improve the data science and ML work flow, and to automate parts of it, to make your data professionals more effective.
The promise of AutoML as Efficient Data Science
The typical ML system can be broken down into a number of different components, or modules, each with a different aim and focus.
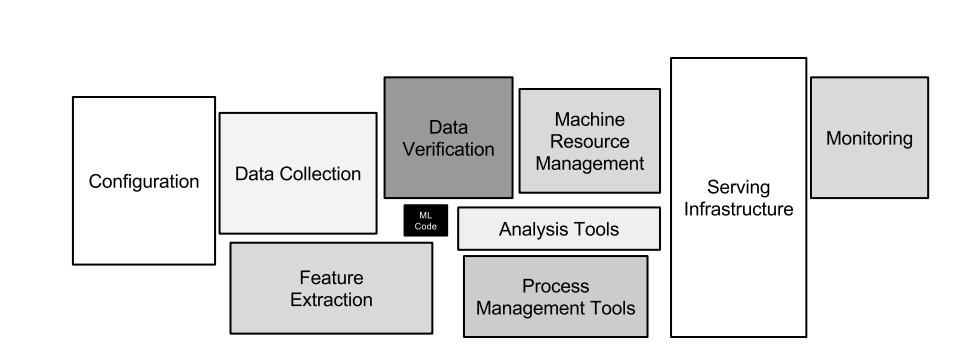
The different components of ML systems. Only a small fraction of real-world ML systems are composed of the ML code. To put ML to work requires complex surrounding infrastructure (taken from the paper Hidden Technical Debt in Machine Learning Systems).
ML code, while important, is only a small fraction of the code base authored by data teams (and their colleagues) to put algorithms to work. And, even the best, highest accuracy models are useful only in production. In production, they need monitoring, and (eventually) retraining. Building and maintaining these often fragile ML pipelines is expensive, both in time and effort. In the process, teams often build up significant technical debt.
Uber and Google recently published papers describing their ML platforms. Their platforms inform us about the challenges they faced putting ML to work.
Google’s platform is built with an emphasis on systems capable of detecting failure and bugs so they do not propagate into the production environment. Uber’s emphasis is on making good use for institutional knowledge. Uber’s platform features a feature store, where Uber’s data scientists store and share (engineered) features (and, presumably, trained models) alongside the appropriate meta-data to help with discoverability (preparing the ground for Transfer Learning). Both provide a framework for reliably producing and deploying machine learning models at scale and promise AutoML as Efficient Data Science / ML (and, eventually, Transfer Learning).
At Cloudera (please excuse the plug), the Cloudera Data Science Workbench provides a solution available to all, not just Google’s or Uber’s data scientists.









