May 2, 2018 · newsletter
Progress in text summarization
We published our report on text summarization in 2016. Since then, we’ve enjoyed helping our clients make use of techniques such as topic modeling, document embedding, and recurrent neural networks to deal with text that ranges in scope from product reviews to insurance documents to call transcripts to news.
Our goal when we do research is to address capabilities and technologies that we expect to become production-ready in one to two years. That focus on fast-moving areas means that new algorithmic ideas sometimes come along that allow our clients to extend or improve upon the work in our reports. Prompted in part by Yue Dong’s March 2018 Survey on Neural Network-Based Summarization Methods, we thought we’d take some time to describe the developments in text summarization since our report was published.
Put simply: there’s bad news and there’s good news.
The bad news is that we still don’t think abstractive summarization is ready for production prime time. Extractive summarization involves selecting a few passages from a document or corpus and stitching them together to form a summary. As we discuss in our report, this is a tough problem. But abstractive summarization is harder still. Not only must you identify the salient ideas, but you must also generate new text that expresses those ideas concisely.
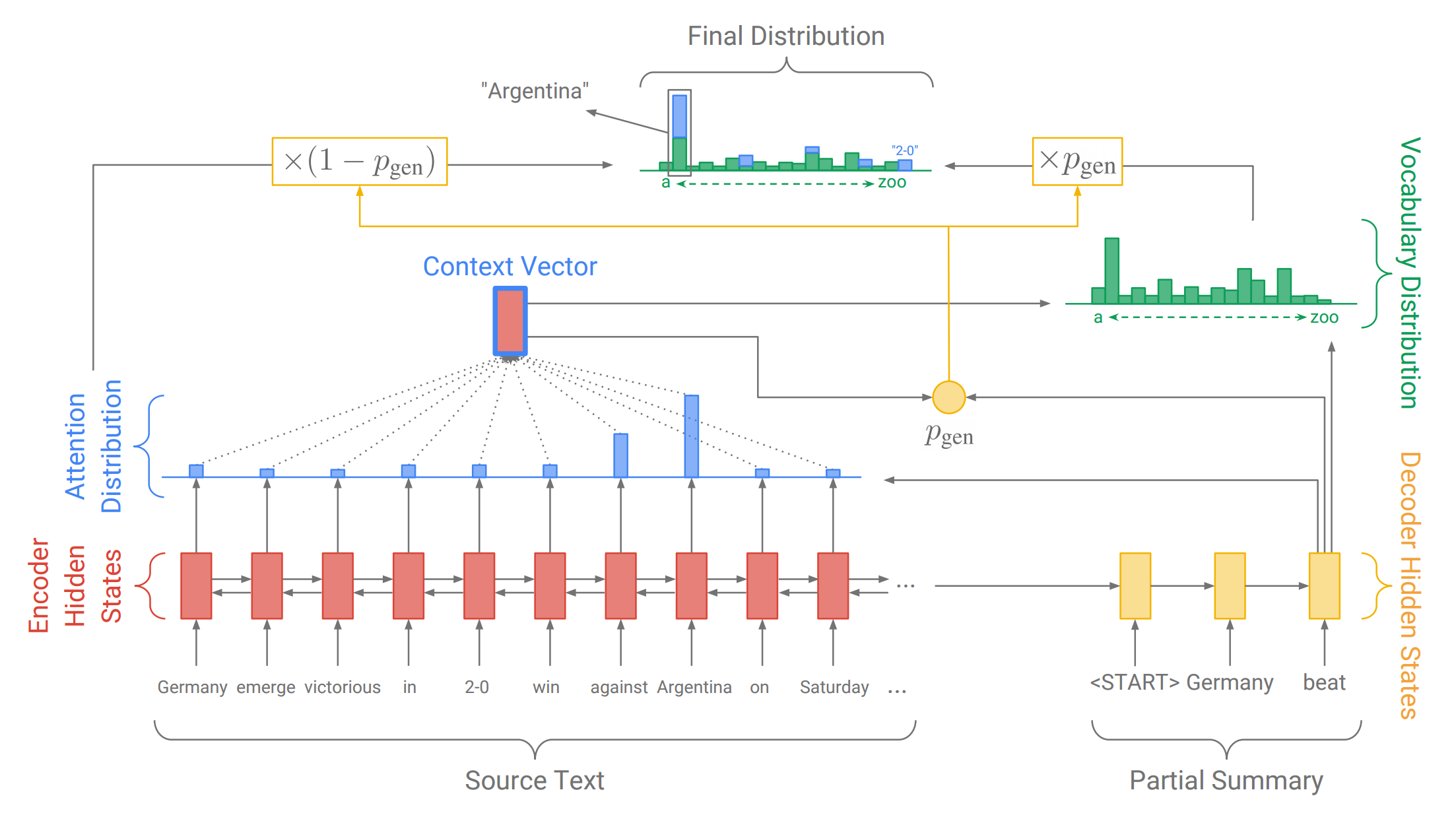
Pointer network for summarization. Credit: Abigail See and collaborators
There has been considerable progress along these lines. The current state of the art is 2017’s attention-based pointer networks, e.g. work from Abigail See and collaborators at Stanford and Google Brain and Salesforce Research’s work lead by Romain Paulus.
However, those authors would concede what Noah Weber and collaborators showed last month: in practice, these abstractive networks work by “mostly, if not entirely, copying over phrases, sentences, and sometimes multiple consecutive sentences from an input paragraph, effectively performing extractive summarization.” So, for now at least, you get the training data requirements and engineering complexity of cutting-edge deep learning without the practical performance increase. Which is not to say academic work on abstractive summarization is at a dead end; we look forward to reporting on the inevitable breakthroughs in a year or two.
In the meantime, we promised good news!
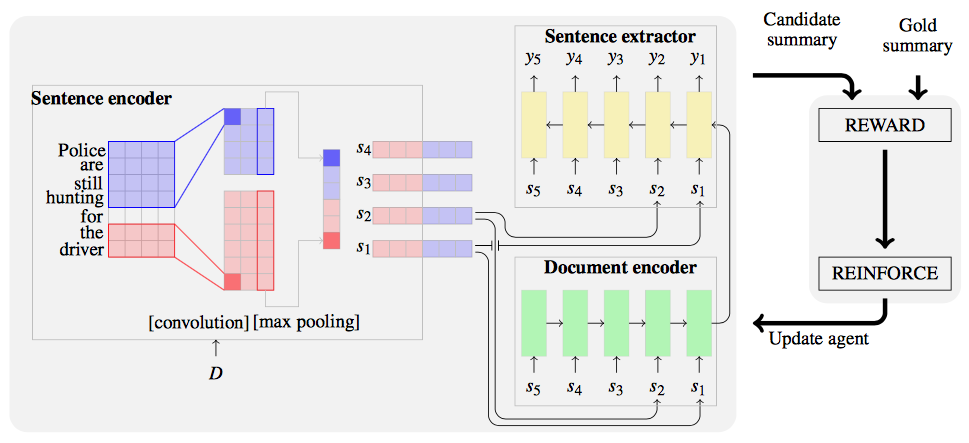
Extractive summarization with reinforcement learning. Credit: Shashi Narayan and collaborators
The good news is a couple of really nice papers that make concrete improvements to extractive summarization. Both are from the same Edinburgh group. Neural Extractive Summarization with Side Information (2017) takes advantage of a very natural heuristic that was used in classical summarization algorithms: titles and image captions are particularly strong signals of the important ideas in a document. This heuristic is incorporated into an attention-based encoder-decoder network, and they get really nice extractive results. If your source documents have that kind of structure, this approach is worth investigating. More ambitiously, in Ranking Sentences for Extractive Summarization with Reinforcement Learning (2018) the same group recasts extractive summarization as a reinforcement learning task. Unusually, they learn to rank sentences in the source document rather than score them in isolation, which they argue results in more coherent (and less verbose) overall summaries.
So, two years after our report, text summarization remains not only a useful business capability, but a very vibrant area of research.









