Aug 29, 2018 · newsletter
Understanding a generative space
Kate Compton, maker of many interesting things, recently tweeted a diagram from her work-in-progress dissertation zine. The illustration breaks down how we interact with a procedural generator, which can be anything from a photo filter to a character creation tool.
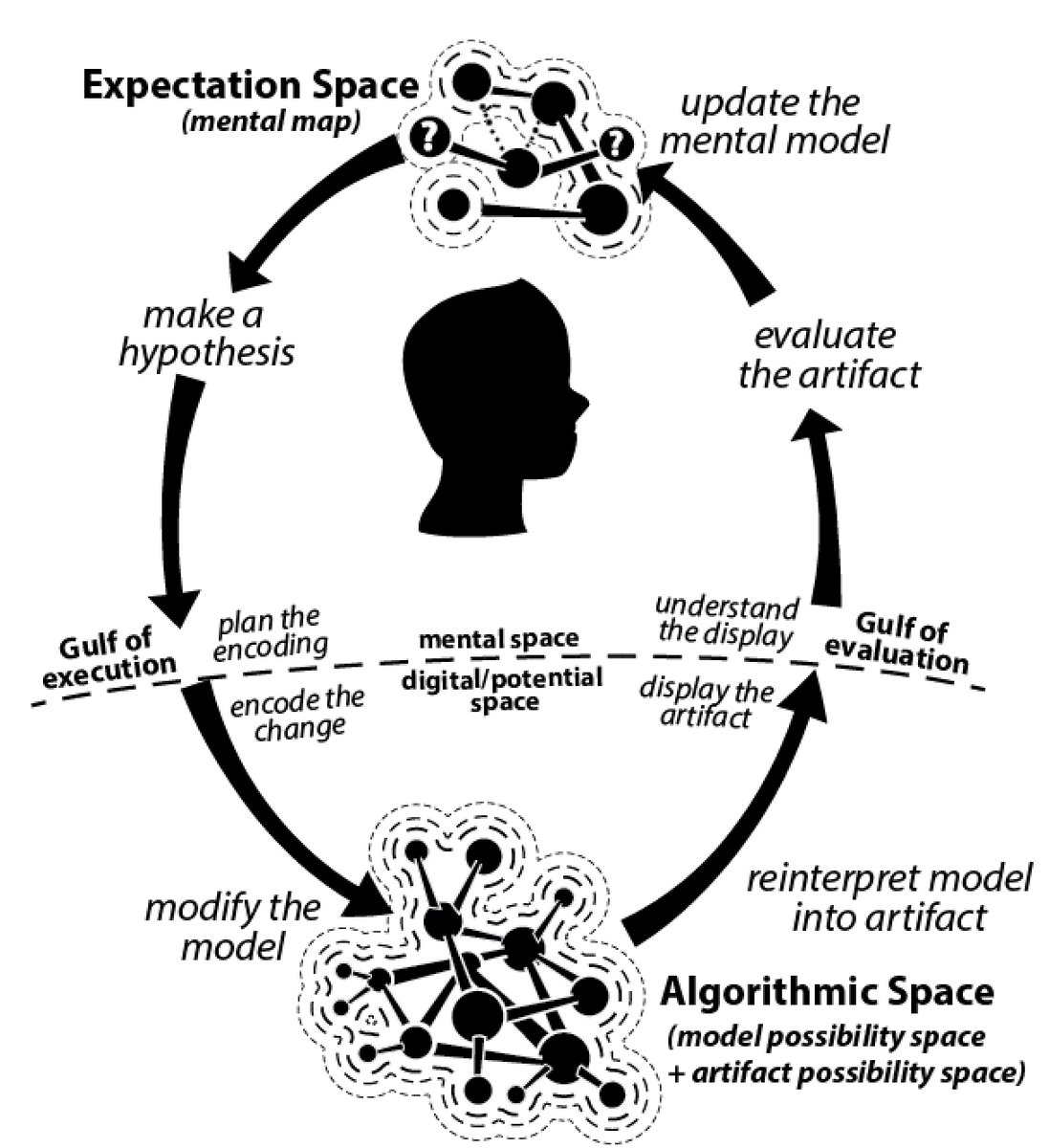
“How we understand a generative space” by Kate Compton. Understanding a generative space requires moving between the digital space (where the code is and the results are displayed) and the mental space (where we evaluate the display and make guesses about how it works).
As app creators, we tend to focus on the parts we can see: the user interface and the code that determines app behavior. Those are the parts that we can directly control. Compton’s diagram is a great reminder that there’s another dimension at work in a user’s experience of an app: their mental model of how the application works. We have much less direct control over a user’s mental model.
The mental model is the user’s “parallel universe” reconstruction of the logic behind an application. As app creators, we try to shepherd the user so their mental model usefully aligns with our own. We employ metaphors, often based on familiar patterns from the physical world or other applications - but there’s always going to be slippage. Part of the fun of designing an application is figuring out how to minimize this slippage, and providing lots of entry points, so that if a user’s mental model gets really misaligned, there are spots within the application where expectations can be reset. As Compton’s diagram shows, one of the best ways to encourage alignment of a mental model and the model itself is to allow the user to make changes and quickly see the results. Enabling that sort of iterative play taps into the human impulse to poke things in order to figure out how they work.
Understanding the interplay between a user’s mental model and an application will be especially important for creating machine learning tools that open up new creative possibilities. Because of their complexity, it may not be feasible for users to develop a comprehensive mental model of how an ML model works. It will then be up to application creators to guide users towards a simplified or alternate mental model that helps them collaborate fruitfully with the application.









