Oct 29, 2018 · post
Coming Soon: Federated Learning
Federated Learning is a technology that allows you to build machine learning systems when your datacenter can’t get direct access to model training data. The data remains in its original location, which helps to ensure privacy and reduces communication costs.
Privacy and reduced communication makes federated learning a great fit for smartphones and edge hardware, healthcare and other privacy-sensitive use cases, and industrial applications such as predictive maintenance.
What’s the Status Quo?
To train a machine learning model you usually need to move all the data to a single machine or, failing that, to a cluster of machines in a data center.
This can be difficult for two reasons.
First, there can be privacy barriers. A smartphone user may not want to share their baby photos with an application developer. A user of industrial equipment may not want to share sensor data with the manufacturer or a competitor. And healthcare providers are not totally free to share their patients’ data with drug companies.
Second, there are practical engineering challenges. A huge amount of valuable training data is created on hardware at the edges of slow and unreliable networks, such as smartphones, IoT devices, or equipment in far-flung industrial facilities such as mines and oil rigs. Communication with such devices can be slow and expensive.
A Breakthrough Innovation
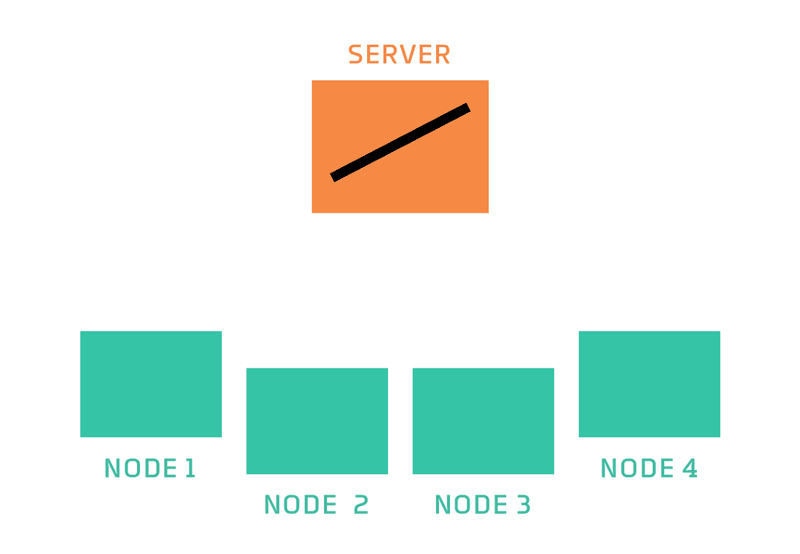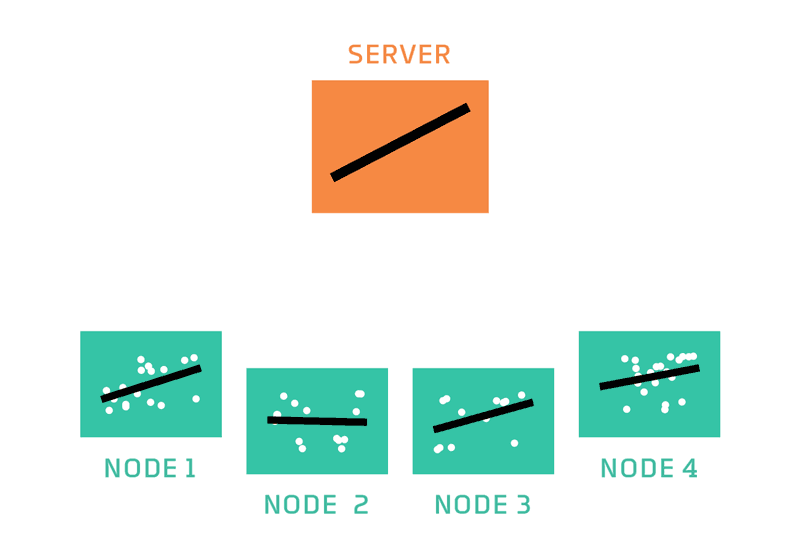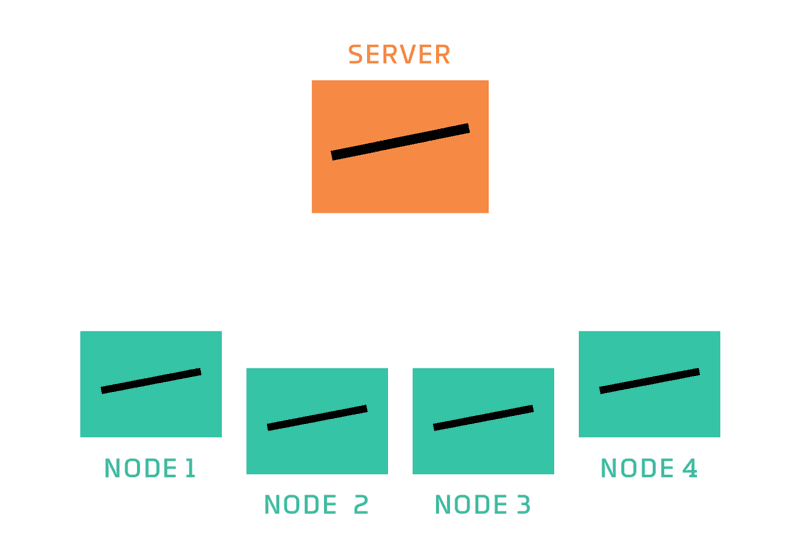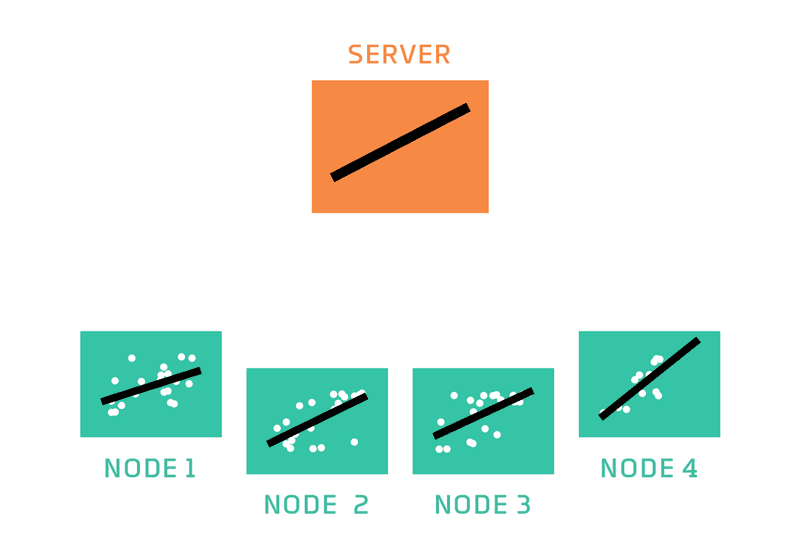
In federated learning, a server coordinates a network of nodes, each of which has training data that it cannot or will not share directly. The nodes each train a model, and it is that model which they share with the server. The server never has direct access to the training data. By moving models instead, federated learning helps to ensure privacy and minimizes communication costs.
In moving the majority of the work to the edge, federated learning is part of the trend to move machine learning out of the data center, for reasons that include speed and cost. But in federated learning, the edge nodes create and improve the model (rather than merely applying it). In this sense, federated learning goes far beyond what people usually mean when they talk about edge AI.
In the Cloudera Fast Forward Labs report, we discuss use cases ranging from smartphones to web browsers to healthcare to corporate IT to video analytics — all situations where privacy and bandwidth create challenges for distributed machine learning.
Our working prototype, Turbofan Tycoon, focuses in particular on industrial predictive maintenance with IoT data, where the training data is a sensitive asset.
The report will be available to corporate subscribers to Cloudera Fast Forward Labs’s advising service from Tuesday, November 13. The prototype will be available to the public the same day.
And all are welcome to join us on Thursday, November 15 at 10AM PT for a live webinar on “Federated Learning: ML with Privacy on the Edge”. Mike Lee Williams of Cloudera Fast Forward Labs will be joined by Andrew Trask (founder of the open source federated learning project OpenMined), Eric Tramel (Senior Research Scientist of healthcare AI startup Owkin), and Virginia Smith (Assistant Professor in Electrical and Computer Engineering at Carnegie Mellon University).
Click here to watch the webinar!









