Oct 29, 2018 · newsletter
The Decentralized Web
Last week, Sir Tim Berners-Lee announced Solid, a project designed to give users more control over their data. Solid is one of a number of recent attempts to rethink how the web works. As part of an effort to get my head around the goals of these different approaches and, more concretely, what they actually do, I made some notes on what I see as the most interesting approaches.
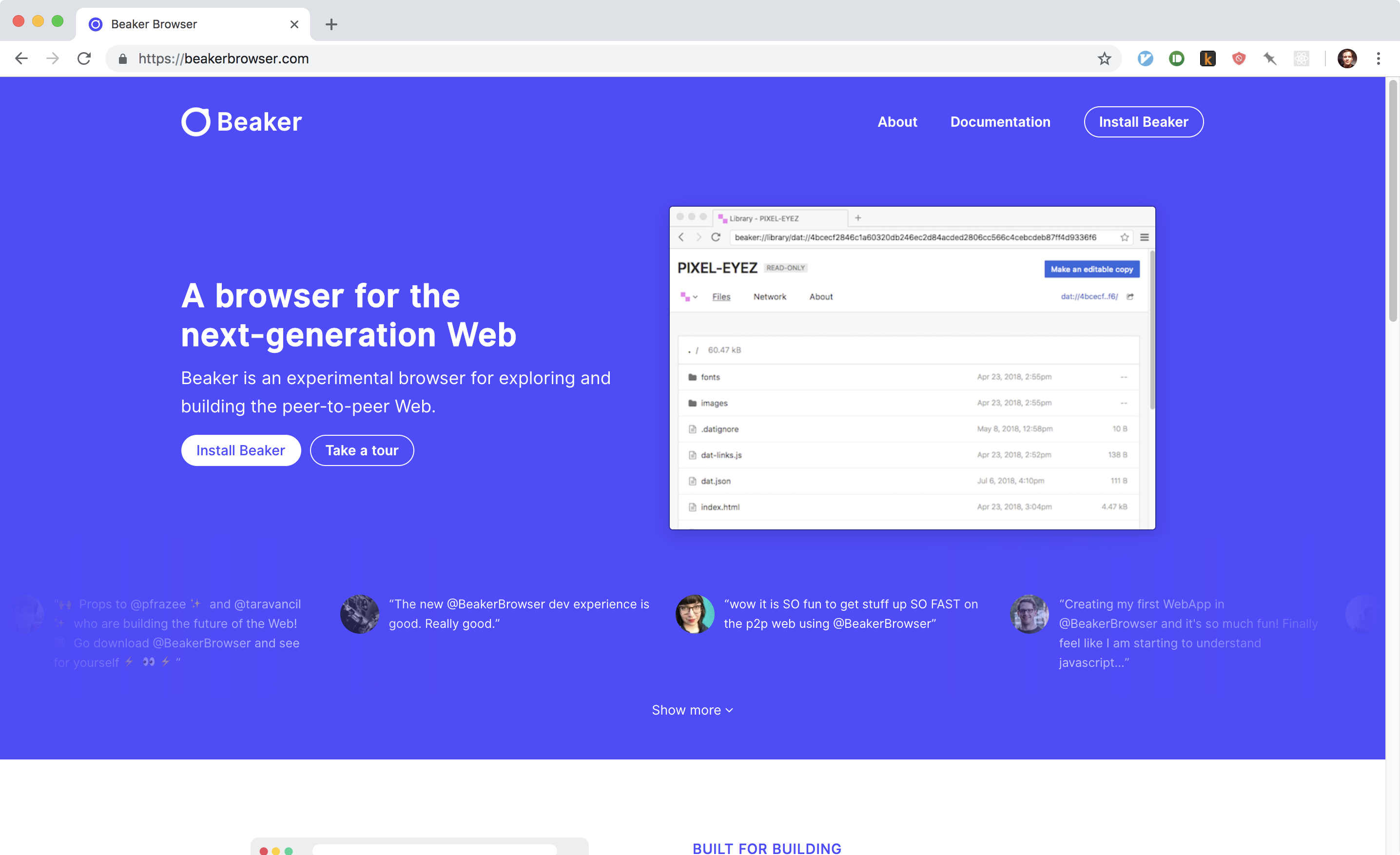
Beaker browser for the peer-to-peer web.
The approach I’ve looked at the most is Beaker Browser. With Beaker you can view and create peer-to-peer websites using the Dat protocol. I got interested in Beaker because I had seen some of the more experimental designer-devs I follow experimenting with it. It’s very easy to get running, and the interface feels immediately familiar (the browser is built on Chomium, the open-source project that underpins Google Chrome). I viewed some peer-to-peer sites and looked at the number of seeders for them — but I didn’t really know where to go beyond that.
I got a much better picture of the goals and capabilities of Beaker through this talk by Tara Vancil, a core member of the Beaker team. Part of the talk is focused on the web we lost: the beginner-friendliness of decipherable view source, and places like Geocities (where anyone could make their own weird web pages). With Beaker, you can make your own website and immediately host it on the peer-to-peer web without having to worry about setting up your own server. This could make it a great fit for demonstrations and classroom settings. To have a peer-to-peer site that stays up even when your computer is shut down and your seeders have run out is a bit more complicated. I found Tom MacWright’s “So you want to decentralize your website” a useful and realistic look at the steps involved.
Tom MacWright’s post “So you want to decentralize your website” web link dat link
One of the most interesting parts of Vancil’s talk comes at the end, where she talks about the possibility of a Twitter-like site where each user can fork and modify the appearance and interface at will. She also talks about each user storing their identity locally (through a JSON file) and thereby maintaining control of their data. That vision for control of your data (that services connect to) is also the promise of Berners-Lee’s Solid project. Solid, however, is built on top of the web, rather than being a new protocol.
Beyond trying to understand just what everybody is up to, I find these projects really interesting for the implicit theories about why the web is like it is. For Beaker, they believe lowering barriers to entry will create a weirder, more interesting network. Solid seems more aimed at offering an alternative to the data-collection and advertising business models of social media. Brave is another attempt to address that business model — an experimental ad-blocking browser with a blockchain-based publisher rewards feature. There are a lot of different approaches and goals swirling around, which is both confusing and kind of fun. Let us know if there is an area related to the decentralized web you think we should be paying attention to.
A few last links:
- You can get a feel for the variety of interests involved by looking through the conference website for the Decentralized Web Summit 2018.
- IPFS is an alternative peer-to-peer protocol.









