Dec 18, 2018 · newsletter
Fine-tuning for Natural Language Processing
2018 was a fun and exciting year for natural language processing. A series of papers put forth powerful new ideas that improve the way machines understand and work with language. They challenge the standard way of using pretrained word embeddings like word2vec to initialize the first layer of a neural net, while the rest is trained on data of a particular task. Instead, these papers propose better embeddings (feature-based approach) and pre-trained models that can be fine-tuned for a supervised downstream task (fine-tuning approach).
Under feature-based approaches, where fixed features, in the form of vectors, are extracted from the pre-trained model, ELMo provides contextualized embeddings for a word. For example, the word bank in “I want to deposit money into a bank” and “I want to run by the river bank” means different things. ELMo allows the word “bank” to have multiple embeddings depending on the context in which it is used. Under fine-tuning approaches, BERT, ULM-FiT and OpenAI GPT (pdf) propose various model architectures that are pre-trained on a language model objective (i.e., predict the next word). Among these models, BERT stands out because it provides representations that are jointly conditioned on both left and right context in all layers. In other words, it is deeply bidirectional, as opposed to ELMo (shallow bidirectional) and OpenAI GPT (one direction, left to right).
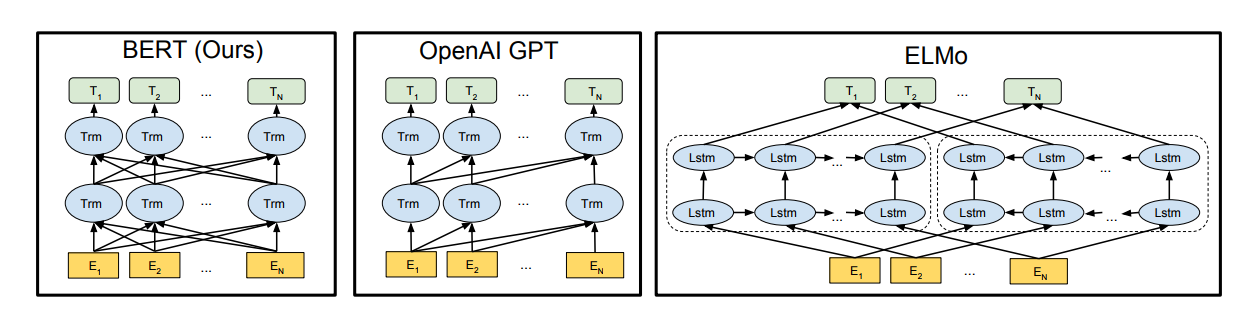
BERT’s architecture is based on a bidirectional Transformer encoder. (We will not go into details of the Tranformer, but the paper is worth a read!) BERT’s input representation is able to represent a single text sentence or a pair of text sentences (the reason will become apparent later on). Each token, or loosely, each word is represented by the summation of its word embedding, a learned positional embedding, and a learned segment embedding. The word embedding used in the paper is WordPiece embeddings. The positional embedding captures the order of the word in the sequence (or sentence). The learned segment embedding associates certain tokens with a particular sentence since the input can be a pair of text sentences.
BERT is not trained using a traditional left-to-right or right-to-left language model. In these approaches, the model is asked to predict the next word, given what it has seen so far either from the left or right. ELMo, for example, trains two models, one left-to-right, the other right-to-left, and concatenates them together. This results in a shallow bidirectional model. It is impossible to train a deep bidirectional model like a normal language model because that would create cycles where words can indirectly “see themselves.” The prediction then becomes trivial. To overcome this, BERT trains using two clever unsupervised prediction tasks. First, it masks a percentage of words from the input and asks the model to predict these masked words from the context. An example would be to ask the model to predict [MASK1] = hairy from the input “my dog is [MASK1]". The second task teaches BERT to understand the relationship between two text sentences by pre-training a binarized next sentence prediction task (see image). This ability is not captured by language modeling, but is important for many important downstream tasks (e.g. Question Answering).

Once BERT is pretrained, task-specific models are formed by adding one additional output layer, so a minimal number of parameters need to be learned from scratch. As an example, a classifier composed of a simple feed forward neural network and a softmax layer can be added to BERT for spam detectionn. This is akin to transfer learning for image recognition. Many of us at CFFL are excited about this capability, and some of our thoughts are captured in this previous newsletter article. BERT can also be used as a feature extractor. By concatenating various hidden layers of the pretrained Transformer, the authors show that the best performing combination is only 0.3 F1 behind fine-tuning the entire model for named entity recognition task. BERT is open sourced, and we cannot wait to see it being used to solve problems outside of the research space!









