Mar 9, 2017 · whitepaper
FairML: Auditing Black-Box Predictive Models

Machine learning models are used for important decisions like determining who has access to bail. The aim is to increase efficiency and spot patterns in data that humans would otherwise miss. But how do we know if a machine learning model is fair? And what does fairness in machine learning mean?
In this post, we’ll explore these questions using FairML, a new Python library that audits black-box predictive models and is based on work I did with my advisor while at MIT. We’ll apply it to a hypothetical risk model based on data collected by ProPublica in their investigation of the COMPAS algorithm. We’ll also go over the methodology behind FairML at a conceptual level and describe other work addressing bias in machine learning.
This post is a prelude to our upcoming research report and prototype on algorithmic interpretability, which we’ll release in the next few months. Understanding how algorithms use inputs to inform outputs is, in certain instances, a condition for organizations to adopt machine learning systems. This is particularly salient when algorithms are used for sensitive use cases, like criminal sentencing.
Recidivism & ProPublica
Until recently, judges and legal professionals were the sole arbiters deciding whether to release someone on bail. Legislation and other checks that limit discrimination in this process are designed with human biases in mind. As algorithms influence–or even take over–these types of decisions, it is not clear how to audit the process for fairness and discrimination.
Police and legal professionals in states like Virginia, Arizona, and Florida now use scores from the COMPAS algorithm to support decisions about who to set free, typically regarding bail and/or sentencing. The makers claim the COMPAS algorithm can fairly predict whether a person will re-offend. The exact details and methodology of the COMPAS algorithm are not publicly available, but several studies have assessed its performance.
In a recent investigation, ProPublica analyzed the risk scores produced by the COMPAS model for about 7000 individuals in Broward County, Florida and found that
[COMPAS] correctly predicts recidivism 61 percent of the time. But blacks are almost twice as likely as whites to be labeled a higher risk but not actually re-offend. It makes the opposite mistake among whites: they are much more likely than blacks to be labeled lower risk but go on to commit other crimes.
Multicollinearity and Indirect Effects
In its investigation, ProPublica ran several regression models to quantify how COMPAS risk scores depend on race and other factors. Regressions allow one to use the magnitude and sign of the coefficient estimate obtained as a measure of an model’s dependence on particular attributes. However, indirect effects might still not be accounted for if the attributes used in the regression are co-linear.
The variance inflation factor (VIF) allows us to quantify multicollinearity before running a regression. Despite low VIF scores, a variable correlated with other attributes -even midly- used in the regression can still have indirect effects. Consequently, we need a way to properly account for the issue of multicollinearity and indirect effects for black-box models. FairML provides this capability.
Audit of a Proxy Model
While used for public sentencing, Northpointe’s COMPAS risk assessment algorithm is proprietary, so ProPublica was not able to directly examine its model. Instead, ProPublica manually collected data on the COMPAS risk scores for thousands of cases in Broward, County FL. Using this data, they built regression models that measure the relationship between race and the risk scores COMPAS produces.
For our audit, we used a proxy model. We built a logistic regression proxy model using the attributes collected by ProPublica and assumed this model was an oracle, i.e., a reasonable approximation of the COMPAS model. We then audit this proxy model for bias using FairML. As a sanity check, we also built more sophisticated models using the ProPublica data, and our conclusions remain the same.
FairML
Perturbation
The basic idea behind FairML (and many other attempts to audit or interpret model behavior) is to measure a model’s dependence on its inputs by changing them. If a small change to an input feature dramatically changes the output, the model is sensitive to the feature.
For example, imagine we have a predictive model of income that takes as input attributes age, occupation, and educational level. One way of determining the model’s dependence on age is to see how much the model’s prediction of an individual’s income changes if the individual’s age is slightly perturbed. If the model places high importance on age, then a slight change would result in a big change to the prediction.
But what if the input attributes are correlated? This is certainly true of age and education: there aren’t many 16-year olds with PhDs! This means that perturbing age alone will not provide an accurate measure of the model’s dependency on age. One has to perturb the other input attributes as well.
Orthogonal Projection as a Perturbation Scheme
The trick FairML uses to counter this multicollinearity is orthogonal projection. FairML orthogonally projects the input to measure the dependence of the predictive model on each attribute.
Why does this help? Orthogonal projection is a type of vector projection. A projection maps one vector onto another. If you project a vector a onto vector b, then you get the component of vector a that lies in the direction of vector b.
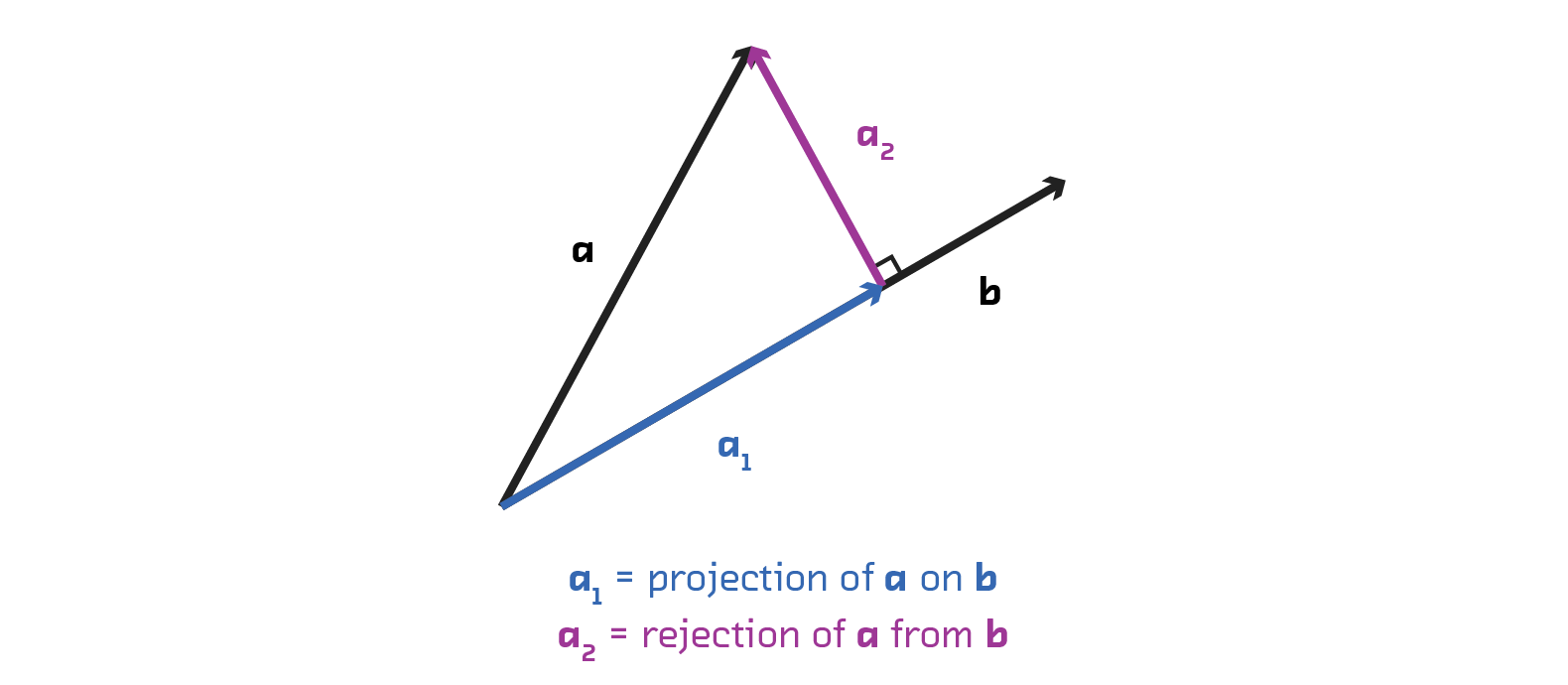
An orthogonal projection is a particular type of vector projection that maps a vector onto a direction orthogonal (or perpendicular) to reference vector. For example, if we orthogonally project vector v onto s (in Euclidean space), we get the component of vector v that is at perpendicular to vector s.
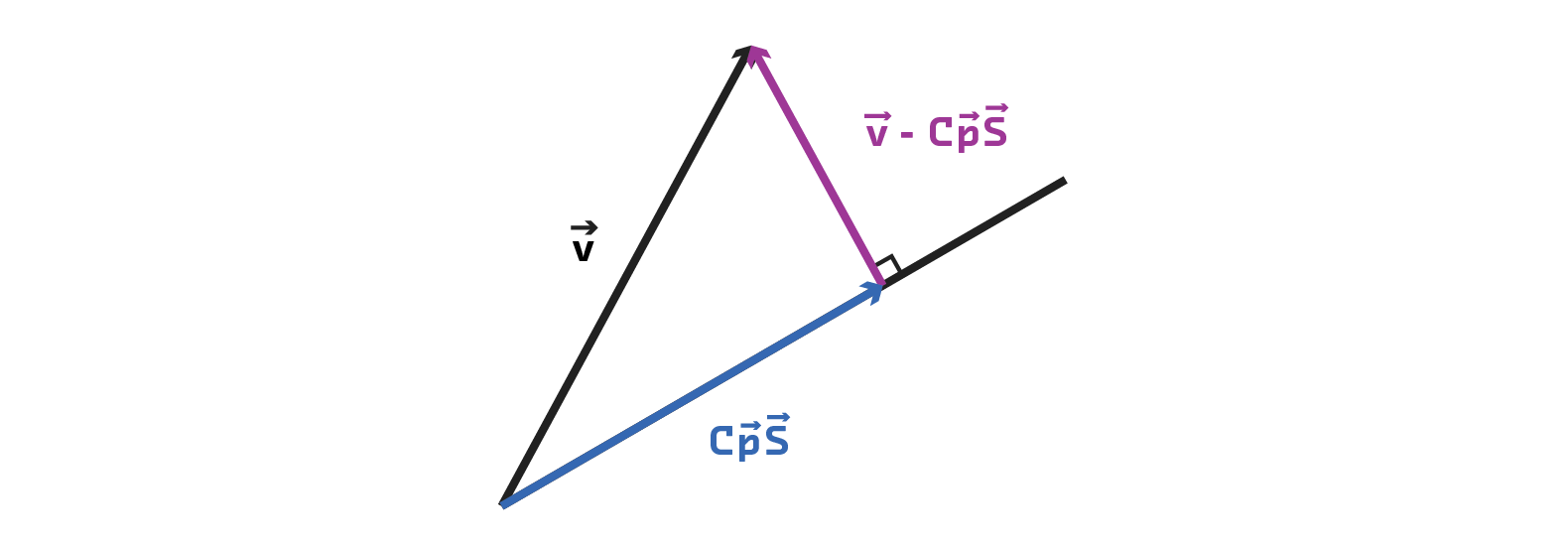
Orthogonal projection of vectors is important for FairML because it allows us to completely remove the linear dependence between attributes. If two vectors are orthogonal to one another, then no linear transformation of one vector can produce the other. This intuition underlies the feature dependence measure in FairML.
More concretely, if we have a model, F, trained on two features x and y, the dependence of model F on x is determined by quantifying the change in output on a transformed input. This transformed input perturbs x, and the other feature y is made orthogonal to x.
The change in output between the perturbed input and the original input indicates the dependence of the model on a given attribute, and we can be confident that there are no hidden collinearity effects.

If you’re familiar with vector projection, you may note that orthogonal projection is a linear transformation. This means it does not account for non-linear dependence among attributes. This is a valid concern. FairML accounts for this by a basis expansion and a greedy search over such expansions (see chapter 4 of thesis, and FairML repo).
FairML - Demo
Finally, here’s how to use the FairML Python package to audit a
black-box model using the audit_model function.
from fairml import audit_model
audit_model takes two required arguments:
- A function that classifies data, i.e., the model of interest.
- Sample data to be perturbed by the querying function (a pandas DataFrame with no missing data). This sample data should represent data the model will encounter in the real world.
It also takes optional keywords that control the mechanics of the auditing process, including
- the number of iterations to perform
- a Boolean flag to enable/disable checking model dependence on interactions
- distance metric to to quantify dependence.
See the FairML repository for a more detailed explanation of how these parameters affect the auditing process.
audit_model returns a dictionary whose keys are the column names of the input
pandas DataFrame and whose values are lists containing model dependence on that
particular feature for each iteration performed.
Let’s use scikit-learn to make a model for FairML to audit. We’re using a
LogisticRegression model here, but one advantage of FairML is that it can audit any
classifier or regressor. FairML only requires that it has a
predict function.
from sklearn.linear_model import LogisticRegression
# Read in the propublica data to be used for our analysis.
propublica_data = pd.read_csv("./doc/example_notebooks/propublica_data_for_fairml.csv")
# Create feature and design matrix for model building.
compas_rating = propublica_data.score_factor.values
propublica_data = propublica_data.drop("score_factor", 1)
# Train simple model
clf = LogisticRegression(penalty='l2', C=0.01)
clf.fit(propublica_data.values, compas_rating)
Now let’s audit the model built with FairML.
importances, _ = audit_model( clf.predict, propublica_data)
print(importances)
Feature: Number_of_Priors, Importance: 0.3608
Feature: Age_Above_FourtyFive, Importance: -0.006805
Feature: Misdemeanor, Importance: -0.05266
Feature: Hispanic, Importance: -0.008425
Feature: Age_Below_TwentyFive, Importance: 0.1533
Feature: Other, Importance: -0.004861
Feature: Two_yr_Recidivism, Importance: 0.2289
Feature: African_American, Importance: 0.2349
Feature: Asian, Importance: -0.00032404
Feature: Female, Importance: 0.045366
Feature: Native_American, Importance: 0.0004861
As a convenience, FairML includes a basic plotting function to visualize these dependencies:
from fairml import plot_dependencies
plot_dependencies(
total.median(),
reverse_values=False,
title="FairML feature dependence"
)
That’s it. FairML allows us to quickly perform an end-to-end audit of a model simply by passing in a predict method and sample data.
Auditing COMPAS
Now that we know how FairML works, let’s use it to audit a hypothetical COMPAS model. Here’s the output of the demo code above.
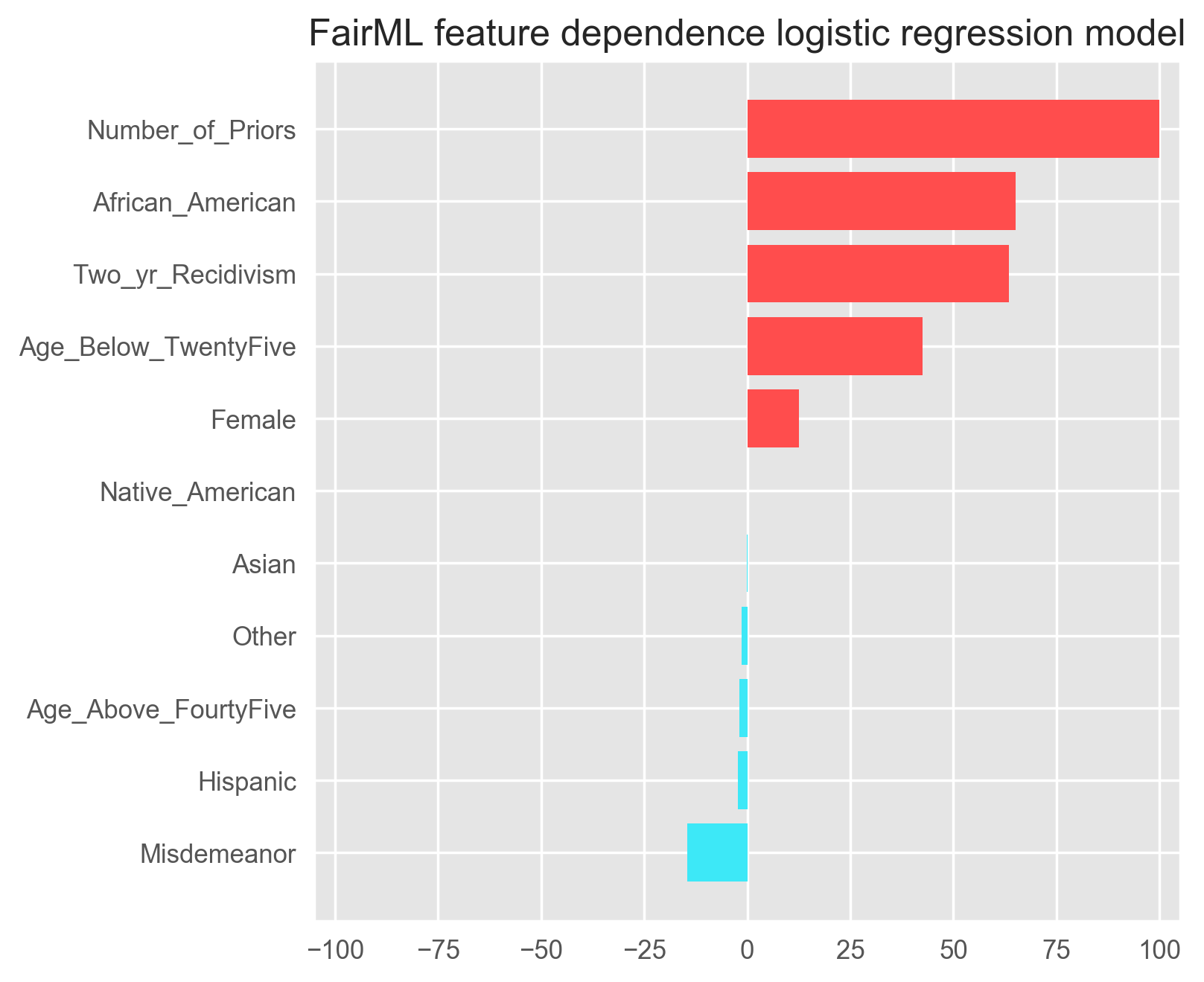
Relative feature dependence ranking obtained from FariML. Red indicates that the factor highly contributes to a high recidivism rating by COMPAS. Note: We omit the intercept term.
Let’s compare the dependence above with that of the logistic regression model obtained in ProPublica’s analysis. Below, we show a bar chart of each attribute and then feature dependence obtained in the two analyses.
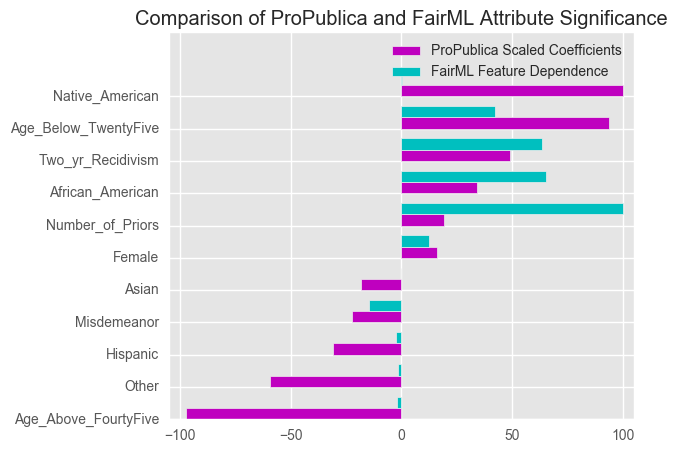
Relative ranking of Logistic Regression Coefficients obtained by ProPublica. Red indicates that the factor highly contributes to a high recidivism rating by COMPAS. Note: We omit the intercept term.
The crucial point to note is: when we account for multicollinearity using FairML, we actually strengthen ProPublica’s claim of bias against African Americans, i.e., we see that the model’s dependence on that attribute increases. FairML shows that the most significant variable is the number of priors an individual has, but this is followed by the attribute African American. In their analysis, ProPublica found that the importance of the African American attribute was not as strong as attributes such as Age, Native American, and Past Recidivism, which differs from the result of our audit.
As noted earlier, our audit results are for the proxy logistic regression model similar to ProPublica’s proxy model. While this audit is not of the original COMPAS model, we, like ProPublica, take the proxy model as an reasonable approximation. Ultimately, to make concrete conclusions, we’ll need access to the COMPAS model. We also built other more complicated models based on this data and audited them. Our results are consistent with the graph shown above.
Other Work
There are many other examples of research about auditing black-box models. All use input perturbation to measure attribute influence on a black-box model, but use different strategies to perturb the input. Two projects stand out: Adler et al. also propose a data perturbation method (whose open source code is available) and Datta et. al. attack the problem of auditing black-box models.
Beyond auditing black box models, the research on fairness and discrimination in machine learning has become a hot button issue. The Fairness, Accountability and Transparency in Machine Learning community is active and dedicated to this line of research. Recent work has articulated new definitions of fairness, and the inherent tradeoffs that different notions of fairness lead to.
Governments and international organizations have become increasingly concerned about algorithmic decision-making too. In fact, the EU recently adopted a resolution that allows for a ‘right to explanation’ of algorithmic decisions that ‘significantly’ affect an individual. The United States White House has also published several reports on big data and discrimination. Developing and deploying ‘artificial intelligence’ in a safe manner is becoming topical among researchers, industry, and government. Going forward, there seems to be dedicated effort on multiple fronts to tackle this issue.










{kind=link}