Mar 10, 2017 · interview
Trees, Layers, and Speed: Talking Optimization with Patrick Hayes
In a modern twist on Claude Shannon’s Theseus, SigOpt explains optimization by teaching a mouse to solve a randomly generated maze
The learning of machine learning refers to the process of updating and tuning the parameters of a model. For example, if we take the function f(x) = ax^2 + bx + c, learning would mean to change the values of a, b, and c so that our function does a better job describing our data.
But what if we zoom out and focus on higher level model properties? Instead of learning coefficients for a function to best fit our data, is it possible to learn how many layers to put in a neural network or how many trees to put in a random forest model?
The machine learning community calls this hyperparameter optimization. There are a few competing optimization approaches available today, and SigOpt, a San Francisco startup, is the first company we know of that offers a platform to automate optimization work for just about any machine learning project and pipeline.
SigOpt has an excellent technical blog on this topic if you’d like to dig in further. To start you off, we recently interviewed SigOpt Co-founder and VP of Engineering Patrick Hayes. Keep reading for highlights!
You studied math and computer science at the University of Waterloo, which has a unique Co-op Program where students alternate between four-month study terms at university and four-month work terms in business, industry, or government. How did this experience shape your interests?
I did six internships during my undergraduate degree, at companies like Blackberry, Sybase, Facebook, and Bloomberg, so left school with a good level of practical experience under my belt While many of these companies were large, I had some experience working on a small team at Wish, a mobile commerce company, where even as a junior engineer I was able to work on topic analysis using a Naive Bayes bag-of-words model. While many data scientists come from statistics or physics backgrounds, I studied pure math, which sculpted the way I approach problems. That said, it’s my training in computer science, not math, that has really impacted my practical day-to-day work. I think people from different intellectual backgrounds can succeed in data science. At SigOpt, we combine expertise in applied math, full stack engineering, and machine learning, and love having such diversity to attack problems from different directions.
Did you prefer working in a big or small company?
The different environments develop a different set of skills. I liked working at a smaller company like Wish because it gave me the opportunity to work on bigger projects. I had more ownership over my work and was able to wear different hats. I liked having a wide array of experiences early in my career to learn what I like to do, as well as what I don’t like to do, building skills to make big impact later in my career. That said, big companies offer some nice benefits, like having more support structures and processes and the ability and time to do a deep dive into a given project.
Why did you found SigOpt and what’s it been like working with your investors?
My co-founder, Scott Clark, researched hyperparameter optimization in his PhD work at Cornell. Hyperparameters are the higher-level properties of a model such as its complexity (e.g., number of layers in a neural network or trees in a random forest) or learning rate, and are usually fixed before model training begins rather than tweaked over time to improve performance. I had a lot of respect for Scott, having worked with him in the past, and felt turning this research into a product could make differences across many industries and problem sets. We started in Y Combinator at the beginning of 2015, and later received investment from Andreessen Horowitz. Y Combinator helped us stay focused in the early days. As Scott and I are both technical founders, they helped us learn how to run a business: our ability pitch to investors or sell to customers was like night and day after a few months! The Y Combinator network, including fellow cohort founders and alumni, was also critical to our early success. Andreessen Horowitz took us to the next step by introducing us to prospects, helping us hire new talent, and helping us grow into executives. I’ve personally learned a lot in these experiences. I came in as an engineer and was in my comfort zone writing code and solving problems. But to build a business, I had to spend 14 hours a day doing stuff I used to be bad at, like sales, marketing, hiring, and managing! It’s great to watch our team progressing on these activities.
How does the product work?
SigOpt is an optimization platform for any machine learning pipeline: our API includes various optimization technologies for hyperparameters, feature selection, machine learning model selection, or even algorithmic trading strategies.The goal is to enable our users to have the best version of their model as possible. We recently published a paper demonstrating that our methods outperform other common approaches to this problem, like random search and grid search.
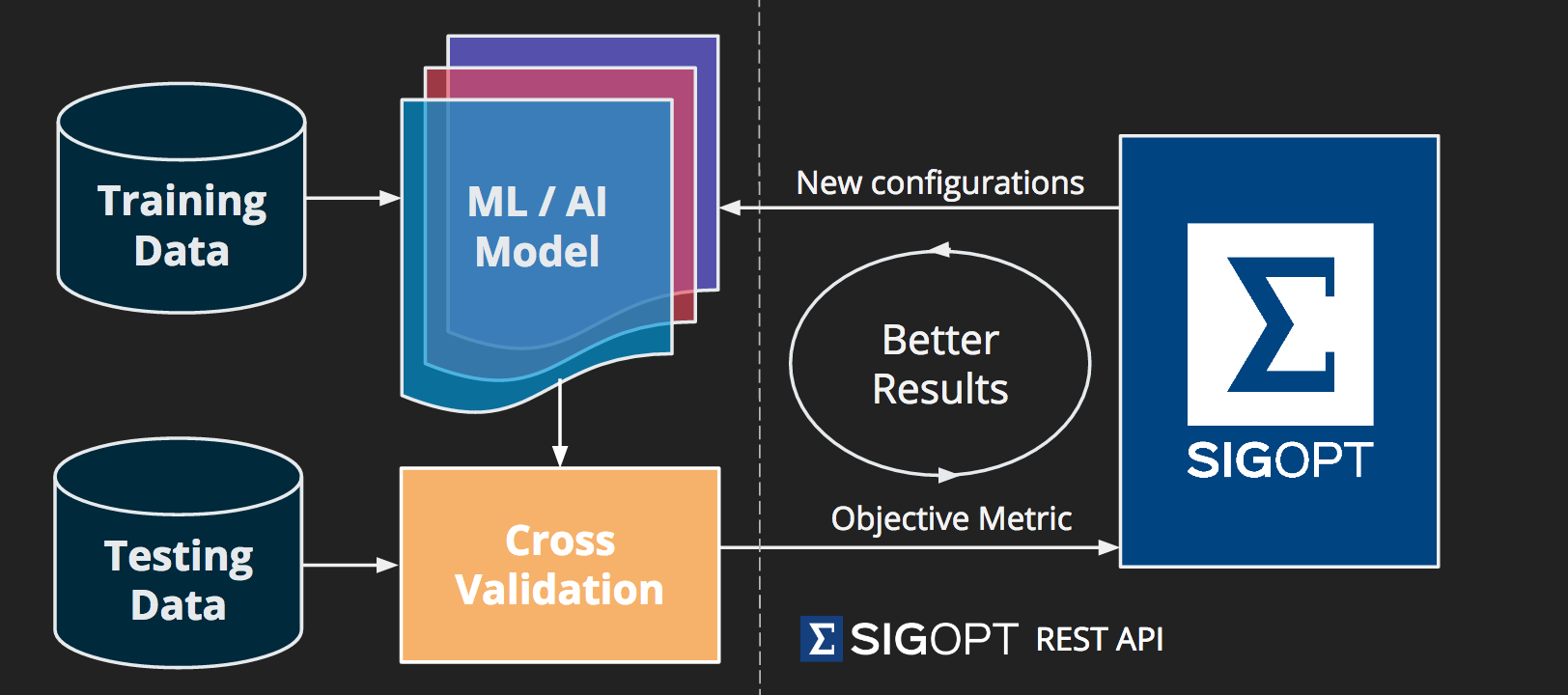
SigOpt focuses on Bayesian optimization ensembles. What does that mean and how do Bayesian techniques support parameter optimization?
There’s a solid 2015 paper that gives an introduction to Bayesian optimization. Mathematically, optimization solves the problem of finding a global maximum (or minimum) for some function f. Global is important here because we don’t get stuck where things may look good locally: we only need to observe the function f through unbiased point-wise observations. What makes the techniques Bayesian is that we start with a prior belief over possible responses of the objective functions we’re optimizing for, and sequentially refine this model as data are observed, i.e., we update our posterior. We can then leverage the uncertainty baked into our Bayesian posterior to guide further exploration and exploitation to optimize the function: exploration is learning more about areas where we have greater uncertainty, and exploitation is going deeper in areas where we are confident the model performs well.
The term ensemble refers to the fact that there are a variety of ways to do black-box optimization. As with all applied AI, it’s a balance between different factors: some techniques are accurate but slow, others are less accurate but fast; some perform better on functions with many parameters and others on functions with fewer parameters. Our product does the work of selecting which strategy will perform best for the problem at hand so our customers don’t have to select which optimizer to use.
What are some interesting use cases?
We’ve seen pretty strong adoption in algorithmic trading to help quants tune their models faster when they discover a new feature or as the data changes. There have also been a few interesting physical use cases, like optimizing the chemical composition in shaving cream or the process parameters for making beer. It can be expensive for companies to make something new that might fail, so they really need to get the best version as soon as possible. These experiments are often solved by trial and error, but optimization software helps make domain experts more efficient.
Can SigOpt help organizations with long-term operation and maintenance of models? A common challenge companies face is that the models their data scientists build are only relevant at one point in time. Do you have tips for productionalization of models in your experience as an engineer?
It’s true that models are built and optimized for a given setting, and as your data changes or you add more features, they quickly become outdated. SigOpt can help upkeep model performance even in the face of a changing landscape or ongoing product development. We want to encourage people to treat optimization as a first-class citizen in their machine learning and AI pipeline. Our algorithmic trading customers do this well, as they need an automated process to get their model ready to perform and only have 16 hours between trading hours to do this. Necessity, as they say, is the mother of invention.
How will tools like SigOpt change the work and skill set of data scientists over the next few years? Will it be possible to automate feature engineering, for example?
I don’t think feature engineering will be automated any time in the near future. Hyperparameter optimization is another example of letting machines do what machines do best, and enabling humans to focus on more creative and critical thinking activities. Our brains aren’t made to optimize 20-dimensional functions in our head, but they are made to explore aspects of a data set to frame a problem worth solving. I’d advise aspiring data scientists to make sure they understand the full machine learning pipeline, from collection and processing, through model building, through engineering and shipping the model. You can’t be satisfied with just part of the process. Production machine learning requires a different skill set than theoretical data science. There’s certain ways of thinking and behaving you can only learn by doing, by getting your hands dirty on the job, by working with real, messy data and making a model scale on real infrastructure.
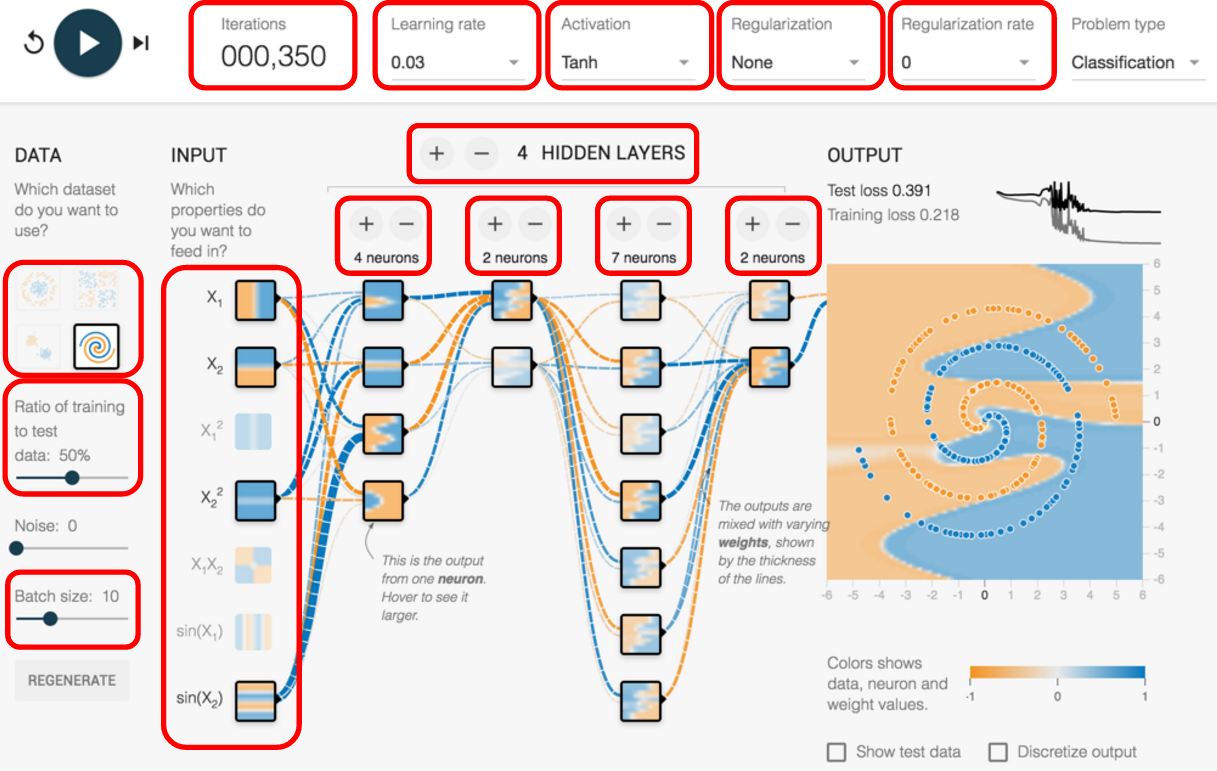
Optimization can be a powerful tool for complex neural network architecture
What book or article has had the greatest influence on you recently?
Susan Fowler’s article about her experience at Uber. It’s important we continue to support diversity in the tech industry, to make sure everyone in the field feels comfortable and supported in their work environment. We think a lot about culture at SigOpt, and all work to cultivate an environment of respect that can support a diverse team.









