Oct 26, 2017 · post
AlphaGo Zero's win, what it means
In an almost Freudian twist, a play on Vatermord by an artificial intelligence, AlphaGo Zero has dethroned its “parent,” AlphaGo.
In March 2016, AlphaGo defeated 18-time world Go champion Lee Sedol. At the Future of Go Summit in May 2017, AlphaGo prevailed against China’s top Go players including Ke Jie, who was considered to be the world’s best Go player.
AlphaGo’s reign was short lived. On October 18th 2017, in a tournament to which human players were not invited, AlphaGo Zero beat AlphaGo.
What’s cool about AlphaGo Zero, and what isn’t
Shortly after AlphaGo’s success in May 2016, Andrej Karpathy (Director of AI at Tesla) wrote an insightful post explaining why AlphaGo is cool, and, largely, why it isn’t:
AlphaGo is a narrow AI system that can play Go and that’s it. The ATARI-playing agents from DeepMind do not use the approach taken with AlphaGo. The Neural Turing Machine has little to do with AlphaGo. The Google data center improvements definitely do not use AlphaGo. The Google Search engine is not going to use AlphaGo. Therefore, AlphaGo does not generalize to any problem outside of Go […].
AlphaGo was successful because its DeepMind creators studied the game Go and uncovered (at least) seven characteristics (or “conveniences”) of the game Go, which they then exploited to build an expert AI game-playing agent.
All but one of these characteristics are still at the heart of the success of AlphaGo Zero. Unlike Alpha Go, trained on human game-playing data and through playing against itself, AlphaGo Zero learns only through self-play. Therefore, AlphaGo Zero does not rely on readily available human game-playing data, and - since data on human behavior is not be available for most real-world problems - for moving beyond the world of games, removing that requirement is great.
But, AlphaGo Zero still relies on other characteristics of Go: most importantly, the access to a perfect simulator (the game itself) and (relatively) short games with clear wins and losses. AlphaGo Zero does not have to worry about today’s weather (and make it a part of its simulator); self-driving cars do. Complex decisions have outcomes far beyond the time-horizon of a typical game of Go. In life, there are rarely clear winners and clear losers. AlphaGo Zero, like AlphaGo, is still a narrow AI system.
Karpathy updated his post last week:
Update Oct 18, 2017: AlphaGo Zero was announced. This post refers to the previous version. 95% of it still applies.
Yes.
We encourage you to read Rodney Brooks’ quite amusing account of all the things self-driving cars have to worry about (like being bullied by humans).
Okay, now what’s cool
AlphaGo Zero is cool. AlphaGo has two neural networks, one trained to generate a distribution over likely Go moves and one to generate an evaluation for each move (i.e., how likely it is to lead to a win). AlphaGo Zero has only one neural network trained on a dual objective (move and evaluation prediction) (see the Nature paper); this is a neat application of multi-task learning.
AlphaGo Zero uses a tweaked, simplified, and very clever Monte Carlo Tree Search (MCTS) that relies on the (single) neural network to evaluate positions and sample moves; the neural network guides the MCTS (and therefore MCTS improves with neural network training).
AlphaGo zero also uses a residual learning framework, a framework that makes it easier to train very deep networks.
So, AlphaGo Zero (like AlphaGo) is a very clever combination of known components to achieve a goal better than any known solution for a well-understood problem: it’s cool. And, it follows the (secret) recipe for any successful machine learning or AI product; a thorough understanding of the problem is as important as a good grasp of the tech.
The real awesomeness of AlphaGo Zero, however, is the reduction in computational complexity and required compute power for training due to algorithmic advances and (as so often) hardware improvements. After just three days of self-play training on 4 TPUs, AlphaGo Zero defeated AlphaGo. (For comparison, the first generation of the AlphaGo lineage needed 176 GPUs.) Compute power can be a real bottleneck; the reduction in compute power is impressive.
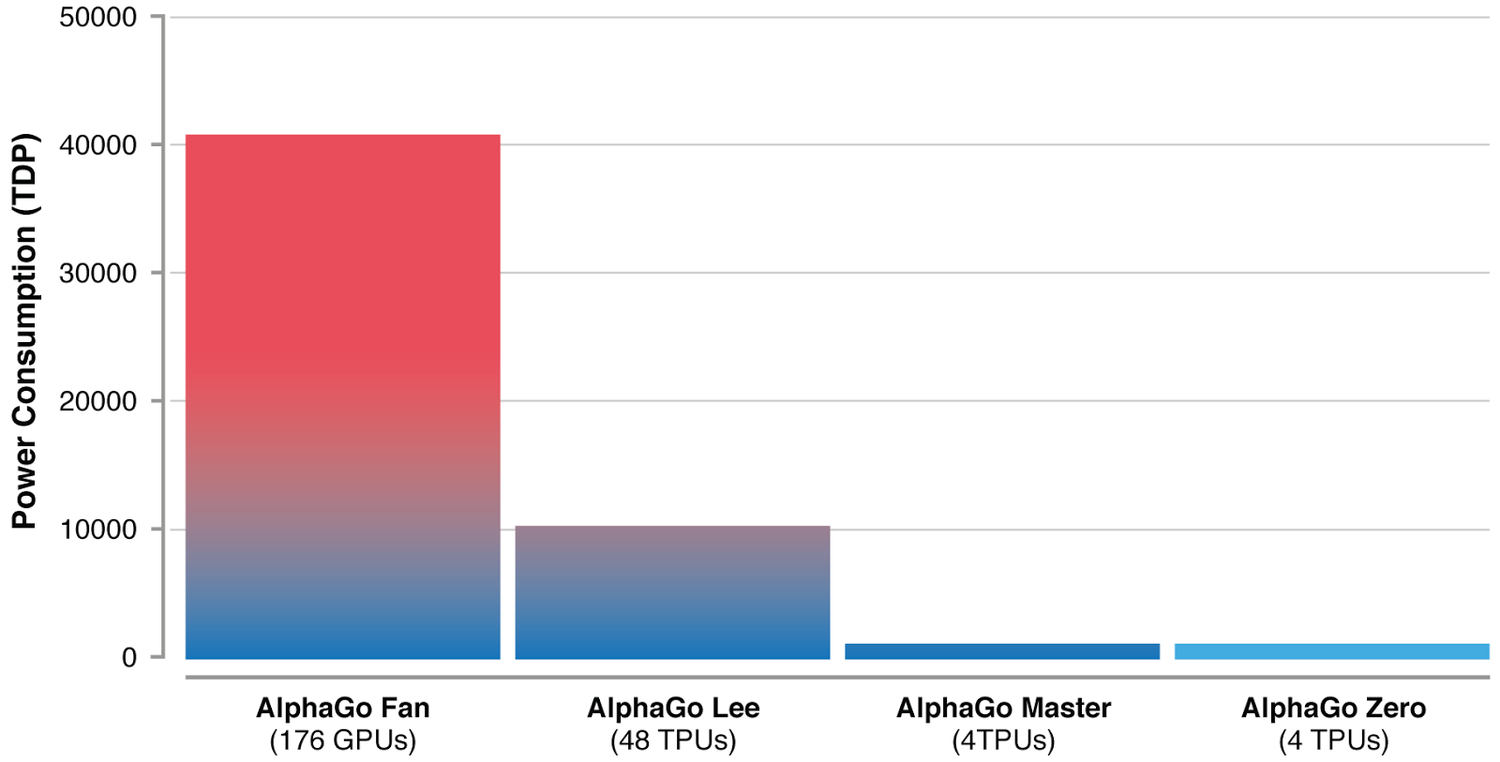
Image Credit: Google DeepMind.
The approach taken by AlphaGo Zero may help solve other problems that are structurally similar to Go (i.e., problems that share characteristics of the game Go). Other games come to mind, and the DeepMind researchers suggest structured problems like protein folding, reducing energy consumption, or searching for revolutionary new materials. The application of AlphaGo Zero to these problems won’t be trivial.
What’s interesting
Through pure self-play without any guidance by human game playing data, AlphaGo Zero learned moves and strategies known to Go players:
AlphaGo Zero rapidly progressed from entirely random moves towards a sophisticated understanding of Go concepts, including fuseki (opening), tesuji (tactics), life-and-death, ko (repeated board situations), yose (endgame), capturing races, sente (initiative), shape, influence and territory, all discovered from first principles.
But what comes easy to humans may not come as easily to an AI:
Surprisingly, shicho (‘ladder’ capture sequences that may span the whole board) — one of the first elements of Go knowledge learned by humans — were only understood by AlphaGo Zero much later in training.
Human Go players may have developed, or stumbled across, strategies to compensate for limits in the brain’s compute power (e.g., limited working memory). Comparing the machine’s to human play may yield insights into the development of strategies for complex games.
Not all the moves the systems learned to make were components of known strategies; it is likely that Go masters will study the moves of AlphaGo Zero to inform their own strategies and future chances of winning.
Rather poetically, Andy Okun and Andrew Jackson from the American Go Association describe the (possible) exchange between human and artificially intelligent AI masters as “a conversation”):
Go players, coming from so many nations, speak to each other with their moves, even when they do not share an ordinary language. They share ideas, intuitions and, ultimately, their values over the board — not only particular openings or tactics, but whether they prefer chaos or order, risk or certainty, and complexity or simplicity. The time when humans can have a meaningful conversation with an AI has always seemed far off and the stuff of science fiction. But for Go players, that day is here.
AlphaGo Zero, welcome!
Parting thoughts
The DeepMind researchers characterize Go (in their paper introducing AlphaGo Zero) as belonging to one of the “most challenging domains in terms of human intellect.” While convenient, a solution is all the more impressive when the problem is extremely difficult. Aren’t there more important problems for us to solve, more challenging problems?
The number of possible configurations on the Go board is greater than the number of atoms in the universe, according to the AlphaGo Movie, but complexity is more than combinatorics.
Complexity is more than combinatorics, the number of possible states in the world (in that sense, and in that sense only, Go is a complex game). As F. Scott Fitzgerald once said:
The test of a first-rate intelligence is the ability to hold two opposed ideas in mind at the same time and still retain the ability to function.
AlphaGo Zero, alongside its other artificially intelligent companions, would suffer; they need a black or white world.









