Feb 28, 2018 · newsletter
Multi-Task Learning
The common approach in machine learning is to train and optimize one task at a time. In contrast, multitask learning (MTL) trains related tasks in parallel, using a shared representation. One advantage of MTL is improved generalization - using information regarding related tasks prevents a model from being overly focused on a single task, while it is also learning to produce better results.
MTL is an approach, and is not restricted to any particular algorithm. A straightforward application of MTL in a feed-forward network means that the model is trained using multiple tasks. Instead of having one output node to predict a single task, there are multiple output nodes (one for each task). Once trained, the network is used to predict outcome of the task we are most interested in. The prediction for other tasks are ignored but the shared representation (weights and the network architecture) is derived from all tasks used in training. In a decision tree, an MTL approach implies that multiple tasks are taken into consideration when deciding on a split that results in a maximum information gain.
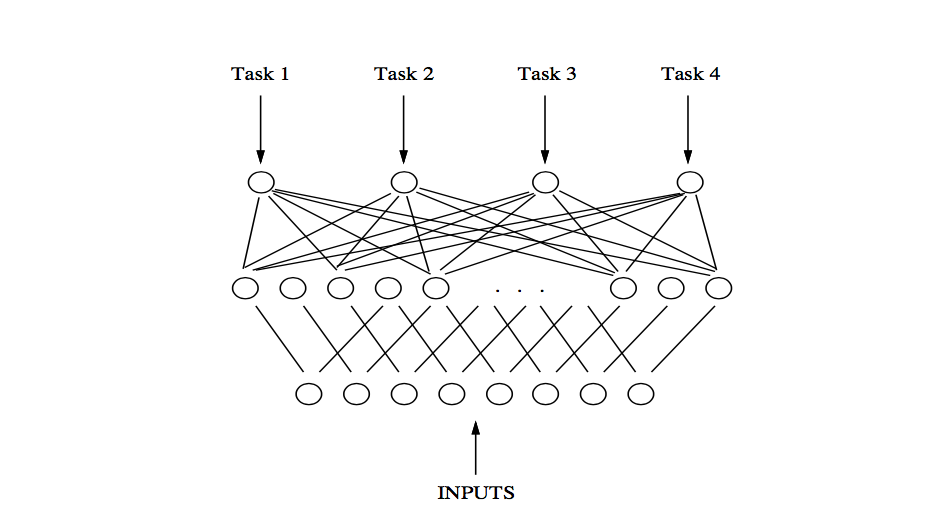
Multitask Network with four tasks. Image credit: Algorithms and Applications for Multitask Learning
Where do we get the training signals for the multiple related tasks (extra tasks)? One possibility is to use future signals to predict the present. In offline systems, we can use future measurements (features that become available after the predictions must be made) as extra tasks during training. For example, results for lab tests administered after hospital admissions can be used as extra tasks when building a model to predict high risk patients at time of admissions. At deployment, predictions for the test results are ignored; test results are only used for training purposes.
Another possibility is to intentionally collect additional labels for each training pattern, and use those as extra tasks. In image recognition, this can be easily accomplished. Instead of annotating an object of interest in an image, a human would also annotate several other objects surrounding it. When we choose to annotate objects that make up a small part of the image (lane markings on roads, for example) and use those as extra tasks, we force the model to focus attention on patterns that it might otherwise ignore.
Are you (thinking about) using MTL in your organization? We would love to hear about use cases and applications!









