Mar 28, 2018 · newsletter
New creative possibilities with machine learning
Machine learning techniques are able to organize large amounts of unstructured data. Combined with dimensionality reduction techniques like t-SNE, this capability opens up new ways for us to interact with creative material including sounds, words, and ideas. In this section we highlight three of our favorite recent experiments.
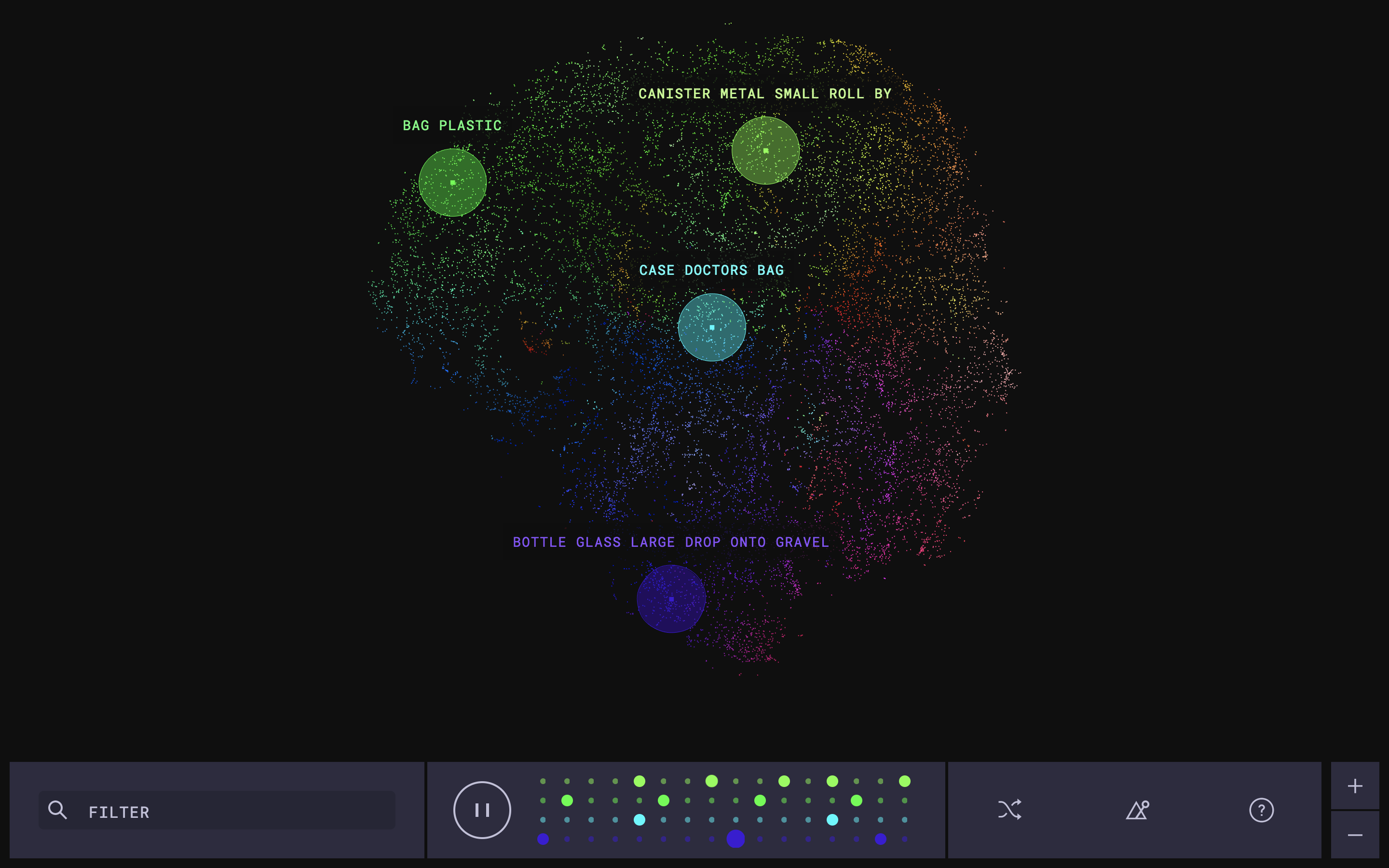
The Infinite Drum Machine is a Google Creative Lab experiment by Manny Tan and Kyle McDonald. It uses machine learning to cluster a large number of samples by similarity of sound. The user then selects clips, which can range from “gravel scoop tin cup” to “casino poker chip,” from a sound map visualization created using t-SNE. The samples feed into a sequencer to create an uncanny drum machine.
Conceptually, the project works because it plays off the long history of hip-hop and electronic musicians using samples from surprising sources (one of Grant’s favorite, kind of gross, examples is Matmos’ “A Chance to Cut is a Chance to Cure”). Sometimes machine learning systems give disappointing results because the system lacks context. In this case, the lack of context is a virtue. It frees the system up to make connections between sounds that humans, with their knowledge of each sound’s source, might never make. It reminds us of first learning to draw, where you have to let go of your idea of what an apple looks like and draw the apple exactly as it appears in front of you.
Samples map well because each sound has a quantifiable (wave) form. Anything involving words gets more complicated. Do you compare on similarity of phoneme, grapheme, or meaning?

In Voyages in Sentence Space, Robin Sloan uses machine learning to explore the possibility space between sentences, which he calls “sentence gradients” (we love that metaphor). Instead of showing the whole map, it focuses on a specific journey from one sentence to another. As for how it does comparisons, Robin tweeted about one illustrative example where, according to the model, ‘“thousand” is more like “three” than it is like “hundred” because of the “th."’
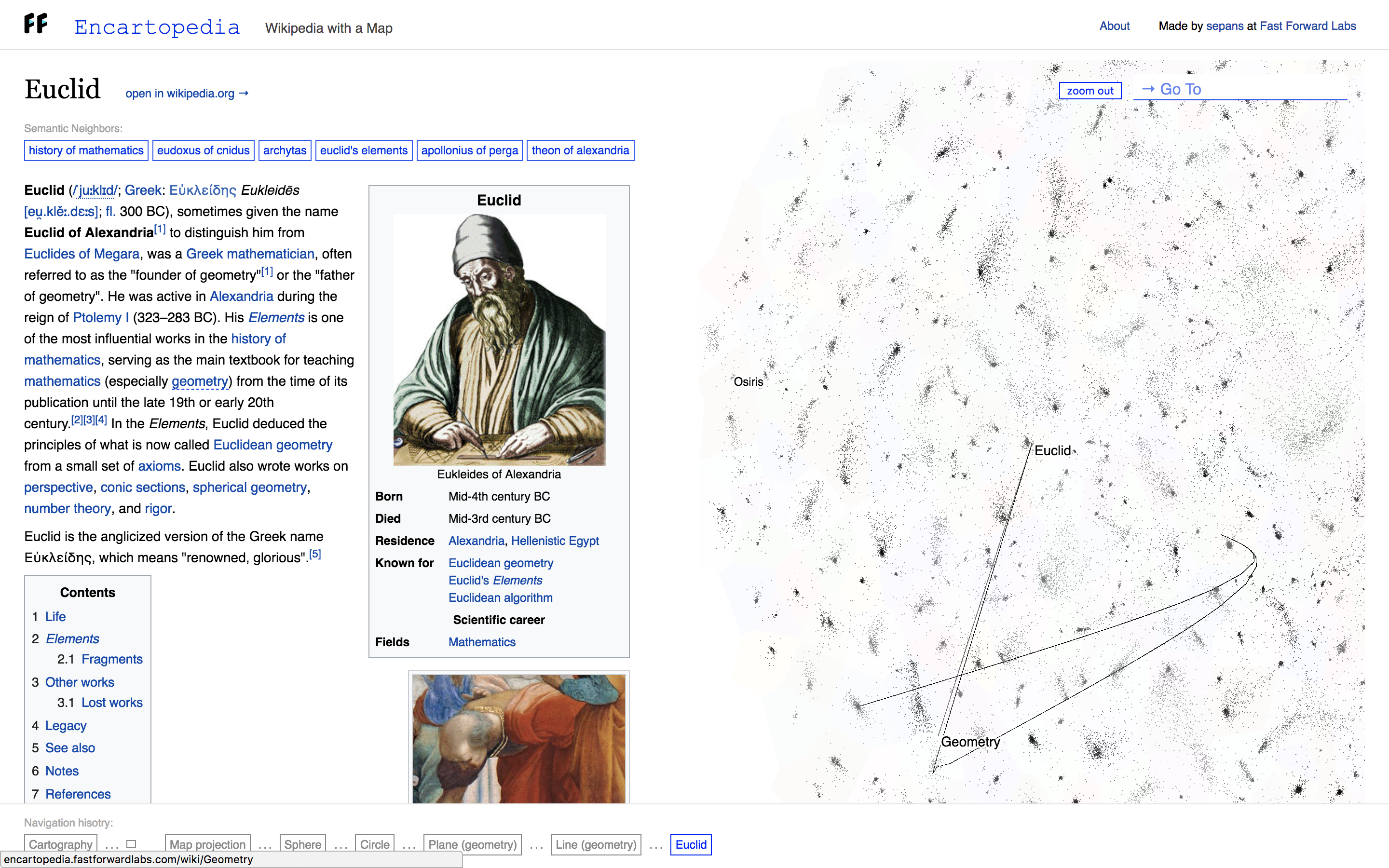
Sepand Ansari’s Encartopedia, which he made while working with us here at CFFL, looks at visualizing Wikipedia articles as an idea map, and plotting the user’s journey through that space. It suggests how new capabilities can help us reflect on our thought process, by showing us how we move through an idea space.









