Mar 28, 2018 · newsletter
Unemployment vs. Augmentation
In the ongoing debates around whether or not robots are going to take our jobs, listening to those who have a real stake in the technology is critical, and often offers important insights for how we build new technologies, as well as how we talk about what we build. Take, for example, this blog post by Judy Gichoya about the Radiology Society of North America’s annual meeting last December, which provides a useful window into the concerns radiologists have about the ways automation will affect their profession, and how those concerns could be taken into account when building capabilities that impact their domain of expertise. Radiologists are justified in seeing their jobs as directly within the sights of automation, even if the tech is not there yet. (Kaggle’s Data Science Bowl 2017 offered a $1 million prize for submissions that could best detect lung cancer from CT scans, a problem that is squarely within the existing job function of radiologists around the world.) But although the risk is real, the idea that any algorithm will replace all radiologists overnight can be easily dismissed. There is more to radiology than just reading film, questions of liability and responsibility are far from being solved, and image classification tools are not nearly accurate or generalizable enough yet for wide scale deployment.
That said, let’s look at how radiologists are talking about the impact of AI on their occupations for some important insights. The first of these is that zero-sum framing doesn’t help anyone. The blog author points to a Stanford press release that celebrates their researchers’ algorithm that “can diagnose pneumonia better than radiologists.” The adversarial framing of the release is problematic, and not just because the Stanford algorithm had to be tested against radiologist-assigned labels (for a more thorough discussion of the testing and performance comparison methodology, see the original paper). Posing the issue as a man vs. machine problem forecloses a more worthwhile discussion on how image classification can be used to aid radiologists in their work, making them more efficient, accurate, and valuable in the roles they currently hold. This is a point developers could be making from the outset, rather than defaulting to a triumphalist tone of voice, stating that the latest algorithm has defeated humans once and for all.
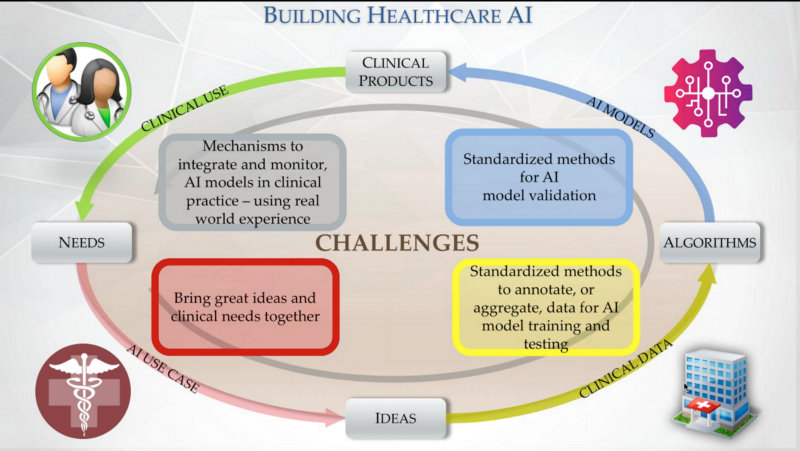
How medical professionals model the AI development workflow. Image Credit: Becominghuman.ai
Collaborations between domain experts and developers can be built into the very earliest stages of a project. Radiologists know their workflows, what hard problems pertain to their field, where advances are needed, and where automation can help (rather than displace) their expertise. The same principle applies to other roles and industries as well, and this conversation among radiologists illustrates how people in general can respond to advances in AI that affect their domains. Radiologists are already planning how to be useful to the development of AI technology; developers can certainly welcome them to the conversation, and we hope the same will happen across the board.
For a thorough examination of how radiologists work, not just in using their expertise to read films, but to ally with techs and other diagnostic specialists, care for patients, and function within the hospital setting, “CT Suite: The Work of Diagnosis in the Age of Noninvasive Cutting” by Barry F. Saunders is a fascinating read that addresses the history of radiology, the epistemology of diagnosis, and the work of medicine in ways that offer valuable insights for anyone building medical technology.









