May 31, 2018 · newsletter
Rules to Learn By
Longtime readers of this newsletter know that we follow the Fairness, Accountability, and Transparency in Machine Learning conversation closely (see here and here). These conversations address and attempt to mitigate the potential for technical systems to produce unfairness. Much of this unfairness arises from how algorithmic systems might perpetuate historical inequalities or otherwise produce discriminatory effects. This conversation is broader than could be encapsulated in any newsletter, but we want to point to some recommendations that have come out of this conversation to demonstrate how we think through the challenges of building models that don’t learn or perpetuate bias. We embrace these challenges not just because of an overriding ethical commitment to build safely, but also because addressing these challenges helps us build things that work better than they otherwise might.
Joanna Bryson identifies three sources of bias, and offers recommendations for how to fix the the problems they pose. With the intention of generalizing Bryson’s analysis to all machine learning, we’d like to restate her argument slightly by identifying the sources of bias as 1) bias in the training data (with the assumption that historical biases tend to be represented in datasets), 2) bias in the assumptions and intuitions that guide our model, and 3) the bias of unintended consequences. Taking these as three sources of bias leads to three recommendations that are also best practices for machine learning.
Bias in the real world (and therefore in the data available for training an algorithm) can be thought of as a class imbalance, regardless of where it comes from. There are acute disparities in how members of different populations are represented in datasets, due to historical social and economic inequities, but rather than perpetuating this disparate representation in machine learning, data can be balanced at the training step and thereby produce a more balanced representation in the model. This is true of all data as well; we still strive to produce balanced representations in any model we build. For an image classifier, if photographs of, say, “hamburgers with fries” are underrepresented in the training data set, the classifier might not work as well across all food items as it might if trained on balanced classes. While humans and hamburgers are very different things, ethically speaking, any machine learning model should learn robust, balanced representations.
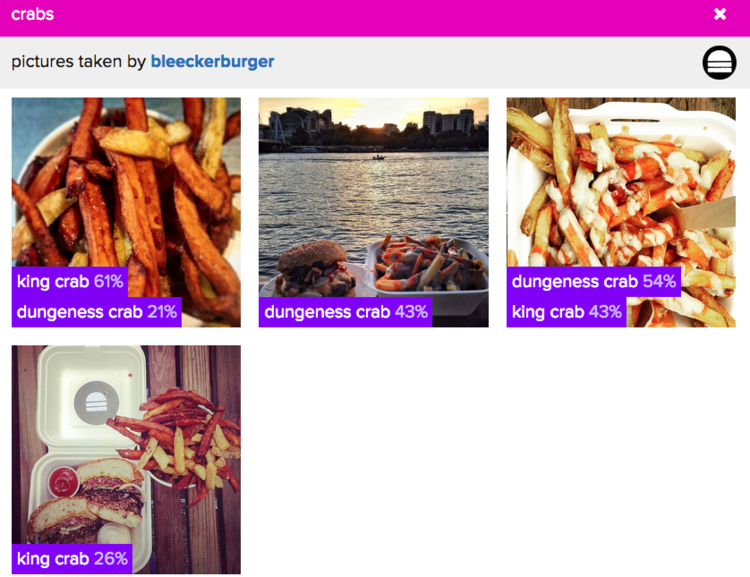
Bias in the assumptions and intuitions that guide our models arises from how we ask and answer questions in machine learning. Bryson refers to this source of bias as “poorly reasoned rules,” but this source of bias can also arise from a lack of robust product testing. Because our own life experience and domain expertise is necessarily partial, we cannot necessarily account for all the ways in which a system might not work as expected. Bryson gives the example of facial recognition not working well for people with dark skin: if we don’t ask whether or not our system works well for all skin tones, it may not work as expected (see Joy Buolamwini’s project on this). One solution to this problem is to develop robust testing pipelines prior to deployment; another solution is to bring in people with diverse sources of expertise and lived experiences to inform the assumptions that guide development and testing; a third solution is to think deeply and broadly about the world in which systems will be deployed. They may work exactly as designed when in ‘the lab,’ but produce unexpected results when deployed. The rules we have in mind about how the world behaves should correspond with the actual world beyond the lab.
The bias of unintended consequences is closely related to the causes of unexpected results, and arises in part from uninterpretable and opaque black box models. When models don’t behave as expected it can be difficult to understand why they misbehaved. Developing (and utilizing) tools that enable interpretability (such as LIME) and auditing algorithms with them can help developers and users understand why a certain result was returned, can identify sources of bias in a model that can then be fixed, and can even result in new and useful insights that have value as products. Bias, in the sense that Joanna Bryson discusses it, perpetuates some of the most harmful tendencies in society. Correcting for that bias is of profound ethical value to society - in machine learning, it also focuses our attention on the things we want to be able to learn (for example, how to create more robust representations of risk factors for disease without overfitting a model to signals that distract from the end goal).









