Jun 26, 2018 · post
Supercharging Classification - The Value of Multi-task Learning
Today’s machines can identify objects in photographs, predict loan repayments or defaults, write short summaries of long articles, or recommend movies you may like. Up until now, machines have achieved mastery through laser-like focus; most machine learning algorithms today train models to master one task, and one task only. We are excited to introduce multi-task learning in our upcoming webinar, report, and prototype. Multi-task learning is an approach to machine learning that goes beyond single-task approaches and supercharges classification by allowing algorithms to master more than one task at once and in parallel.
The basic idea in multi-task learning is that learning several tasks at once allows models to benefit from relationships between tasks for improved performance (alongside other benefits we will cover in the webinar and report). At an intuitive level, this makes sense. A child learning to read is supported by learning the shapes of letters and learning how to talk. Similarly, a machine learning model that is learning to understand language benefits from learning to identify parts of speech while concurrently learning to identify the semantic role words play in a sentence.
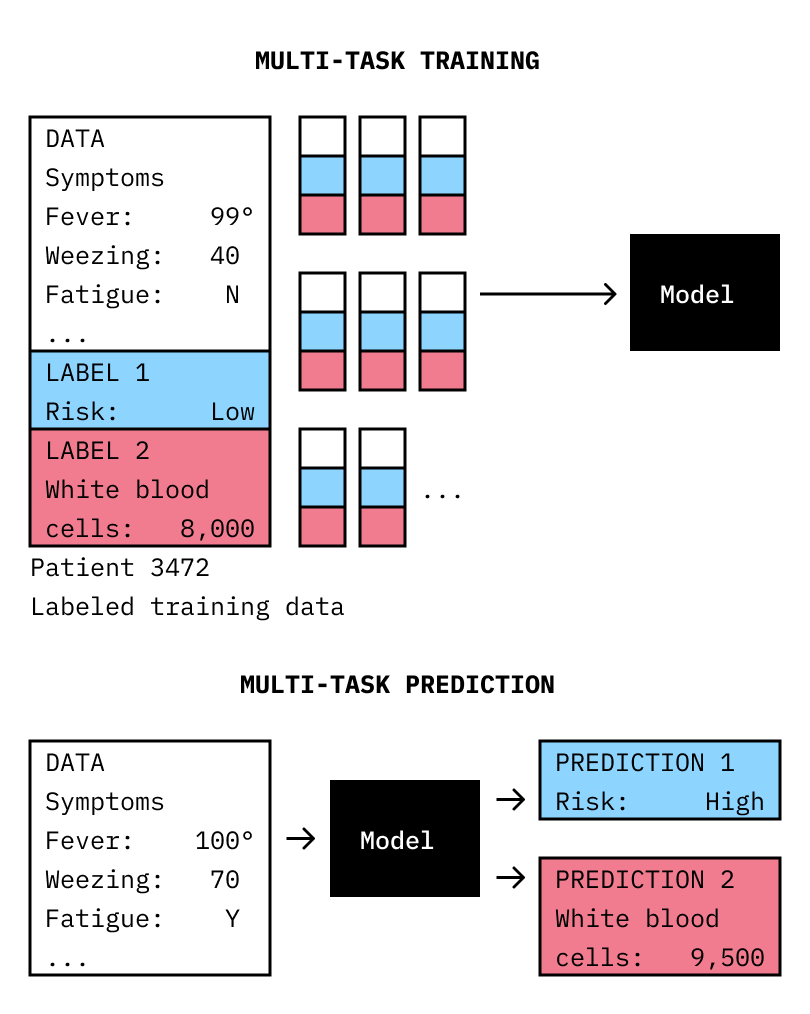
Multi-task Learning can improve the prediction of two variables (e.g. “risk factor” and “white blood cell count”)at the same time that it improves overall performance.
Recently, multi-task learning was shown to improve the prediction of diabetic retinopathy. A team at Google Brain, using ophthalmology databases that store thousands of retinal images, was able to train a multi-task neural network to predict a variety of diagnostic attributes, from trivially easy (‘left’ or ‘right’ eye) to surprisingly difficult (‘male’ or ‘female’ patient), in addition to the main task: the prediction of diabetic retinopathy. The outcome? Even trained ophthalmologists were surprised by the network’s performance. The prediction of the diabetic retinopathy task benefited from the addition of other tasks, showing that seemingly less important tasks can be added to a single-task algorithm (turning it into a multi-task algorithm) to support a primary, difficult task.
Similarly, researchers have improved the ability of a model trained on hospital records to predict patient mortality by adding length-of-stay as a second target variable. Agronomists have improved soil chemistry detection by training a model to learn multiple chemical signatures simultaneously. Roboticists, in a twist on concept learning, have trained a robotic arm with MTL to satisfy both intermediate and end goals concurrently in a way that better supports that end goal. Radiologists have used images labeled as ‘normal’ or ‘abnormal’ alongside pixel-level labels for regions-of-interest that show the location of the abnormality to improve disease detection from imagery. And, under the hood, AlphaGo is using multi-task learning. Thus, multi-task learning has proven value in many practical settings.
Multi-task learning works only if tasks are related, of course, and not all tasks are. If unrelated tasks are included, they may degrade the performance of multi-task models. Tasks are likely related if they are drawn from the same domain. The startup Cardiogr.am trained a multi-task model to predict hypertension and sleep apnea from data recorded by wearable heart rate sensors, and found beneficial effects. These beneficial effects may be rooted in shared biology; the autonomic nervous system links your heart with your brain, stomach, esophagus, liver, intestines, pancreas, and, importantly, your blood vessels. The algorithm likely learned heart rate variability as a predictive feature for both tasks; two independent studies showed associations between heart rate variability and hypertension and heart rate variabiliy and sleep apnea. Their results highlight one of the fundamental benefits of multi-task learning: multi-task models learn, in unsupervised fashion, the relation between tasks and extract features that can support not just one but all tasks. Models trained to learn these more abstract features tend to generalize better to new data and (related) tasks. In “machine-learning speak,” multi-task learning prevents overfitting and helps with model transfer.
Multi-task learning also offers a potential savings in processing time, power, and training data. Multi-task learning is a way of training a model to do more than one thing at a time; it can also be used to do the same thing for more than one set of data. Using multi-task learning in such a way allows for data augmentation: learning from several smaller datasets what one would otherwise need a single large dataset to do. While a single-task model might be able to find meaningful patterns in a large clinical data set (as long as the clinical data was collected under a single protocol), a multi-task model can find meaningful patterns across data collected under multiple protocols.
Given the value of a multi-task approach, we are likely to see more applications of multi-task learning across a range of industries and uses cases. Already, we have seen the following:
- Medical Imagery - Disease detection from medical imagery can be made more accurate with less data.
- Aerial Imagery - More accurate structure footprints can be learned using multi-task learning, facilitating property value estimates.
- Agriculture - In-field spectroscopy detects multiple chemical profiles at once, and has made precision farming more efficient.
- Drug Discovery - The ability of compounds to bind to several different kinds of receptor sites can be predicted concurrently.
- Genomics - Using multi-task learning for data augmentation allows for learning across multiple cohorts of research subjects, which can ensure that any findings generalize better to a broader population.
- Healthcare - models trained by multi-task learning outperformed several (though not all) single-task learning models at predicting hospital stay length, mortality rate, disease phenotype (specific medical problem), and decompensation (organ failure).
- Robotics - multi-task learning enables learning complex operations as multiple, related, tasks that eventually culminate in a final goal for a robotic device.
- Natural Language Processing - multi-task learning has improved the detection of mental health issues based on social media data.
We invite anyone interested in supercharging their classification algorithms using multi-task learning to our upcoming webinar.










{kind=link}