Jul 31, 2018 · newsletter
Progress in machine learning interpretability
Our goal when we do research is to address capabilities and technologies that we expect to become production-ready in one to two years. That focus on fast-moving areas means that new algorithmic ideas sometimes come along that allow our clients to extend or improve upon the work in our reports.
We published our report on machine learning interpretability last year. The technical focus of our report was LIME, a tool that computes locally correct explanations of a model’s behaviour. If a model is good, LIME’s explanations can offer completely new insights. (We saw this in our prototype, which models customer churn using traditional machine learning techniques, but then uses LIME to say precisely what it is about a customer that makes them a churn risk.) And if a model is bad, LIME can help you understand why.
This all sounds great, but we had to leave three issues unresolved in our report. Progress since last year has begun to address those concerns.
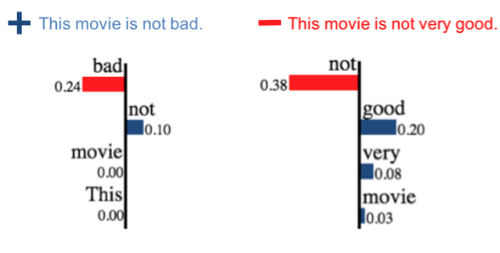
LIME explanations of sentiment classification. “Not” is a positive word in one example, but not in another. Image credit: Anchors.
Firstly, LIME’s explanations are local. For example, a LIME explanation may (correctly) tell you that “This movie is not bad” has positive sentiment because it contains the word “not.” But because LIME’s explanations are local, a user is not generally entitled to conclude from this that the word “not” always indicates positive sentiment. This makes sense: the presence of “not” in “this movie is not very good” does not tell you its sentiment is positive! But how local is “local”? How similar to the original sentence does a new sentence need to be for LIME’s explanation to apply?
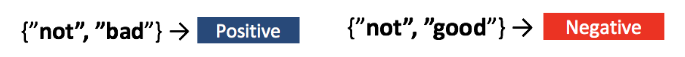
Anchors explanations of sentiment classification. “Not” is a positive word in combination with “bad.” Image credit: Anchors.
The creators of LIME offer an answer to this question in the form of Anchors: High-Precision Model-Agnostic Explanations(PDF, 2.7MB).” Anchors works like LIME in that it probes the behaviour of the black-box model by perturbing the original example. But it takes a very different approach to constructing a human-friendly explanation. Rather than fit a locally correct linear model (which raises the question: how local?), it constructs a set of rules. For the “this movie is not bad” example above, the rule might be “sentence contains ‘not’ and ‘bad’". Such black and white rules are easier for many people to understand than quantitative weights. And they implicitly define locality: if the sentence doesn’t contain “not” or “bad,” the rule (and the explanation) doesn’t apply. The Anchors code is publicly available.

SHAP explanation of a prediction for a model of the Boston house price dataset.
Secondly, LIME’s choice of perturbation strategy and its local linear model are heuristics – which is to say they feel a little arbitrary, and it’s reasonable to wonder whether they are optimal in practice. In A Unified Approach to Interpreting Model Predictions Lundberg and Lee carefully define what we mean by optimal, and show that LIME is a specific example of a more general class of explanation tools they call “additive feature attribution methods.” This class includes the classical “Shapley” feature importance measure familiar to economists, and DeepLIFT, a neural network interpretability tool. They unify this class in a provably optimal way they call SHAP. The code is public, and is highly optimized for the particular case of tree-based methods such as XGboost. One thing we really like about SHAP is that the built-in visualization tools are very nice! This seemingly minor point is surprisingly important to the adoption of new tools, and we’re glad to see these authors spend time on this aspect of their code.
Finally, how do we test explanations? How do we know whether an explanation is evidence of a problem with the model or a surprising insight? Patrick Hall and colleagues at H2O.ai sum up the current situation very well in a new article for O’Reilly Testing machine learning interpretability techniques. The conclusion is: “use more than one type of tool to explain your machine learning models, and look for consistent results across different explanatory methods.” We agree, and we’re glad to see new options such as Anchors and SHAP that make this easy!
So, a year after our report, machine learning interpretability remains not only a very useful business capability, but a vibrant area of research.









