Aug 29, 2018 · newsletter
Hyperparameter Tuning and Meta-Interpretability: Track All Your Experiments!
From random forest to neural networks, many modern machine learning algorithms involve a number of parameters that have to be fixed before training the algorithm. These parameters, in contrast to the ones learned by the algorithm during training, are called hyperparameters. The performance of a model on a task given data depends on the specific values of these hyperparameters.
Hyperparamter tuning is the process of determining the hyperparameter values that maximize model performance on a task given data. The tuning of hyperparameters is done by machine learning experts, or increasingly, software packages (e.g., HyperOpt, auto-sklearn, SMAC). The aim of these libraries is to turn hyperparameter tuning from a “black art”, requiring expert expertise and sometimes brute-force search, into a reproducible science - reducing the need for expert knowledge, whilst keeping computational complexity at bay (e.g.,Snoek, Larochelle, & Adams; 2012).
Traditionally, hyperparameter tuning is done using grid search. Grid search requires that we choose a set of values for each hyperparameter and evaluate every possible combination of hyperparameter values. Grid search suffers from the curse of dimensionality; the number of joint values grows exponentially with the number of hyperparameters.
In 2012, Bergstra and Bengio showed that random hyperparameter search is more efficient than grid search, a perhaps counter-intuitive result. This is because only a few hyperparameters tend to really matter for the performance of a model on a task given data. Grid search tends to spend more time in regions of the hyperparameter space that are low-performing compared to random search. What’s more, random search allows one to easily add more experiments that explore even more sets of hyperparameter values without (expensive) adjustment of the grid (most recently, sequential approaches have shown great promise).
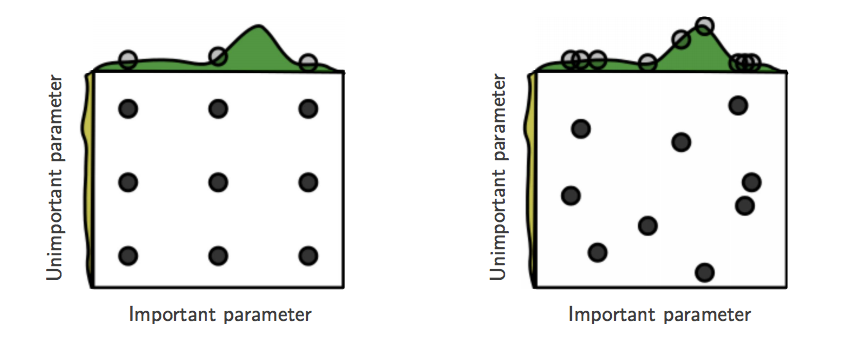
Grid (left) and random (right) search for nine experiments. With random search, all nine trials explore distinct values of the hyperparameters. Random search is more efficient. (Picture taken from Bergstra and Bengio, 2012)
If only a few hyperparameter values really matter, for a given model on a task given data, what are those parameters and what are their values? Current software libraries for hyperparameter tuning do not tend to discriminate important from unimportant hyperparameters and/or do not expose important parameters and their values. This limits insights into the workings of a model - which is important for a variety of reasons, as we explain in depth in our report on model interpretability; interpretability allows us to verify, for example, that a model gives high quality predictions for the right, and not the wrong, reasons.
A series of recent papers tackles this “meta-interpretability” problem: what
hyperparameters matter for model performance on a task given data? In
Hyperparameter Importance Across
Datasets, Jan van Rijn and Frank Hutter
first evaluate a model on a task given data and a set of randomly chosen
hyperparameters to assess model performance. They then use these
hyperparameters as inputs to a model, a so-called surrogate model, that they
train to predict the oberved performance. Given a trained surrogate model, they
predict model performance for hyperparameters not previously included in their
experiments. Finally, they conduct an analysis of variance (ANOVA) to determine
how much of the predicted model performance by the surrogate model can be
explained by each hyperparameter or combination of hyperparameters. To draw
conclusions across data sets, a more generalizable result, the authors repeat
this procedure across several data sets. For random forests, for example, they
find that only the minimum samples per leaf and the maximum numbers of features really matter. This finding is consistent with expert knowledge,
which is great: it validates the method; we can use it to study more
complex models for which we have no such intuition yet while it helps beginners
to get started.
Using a related approach also based on surrogate models, Philipp Probst, Bernd Bischl, and Anne-Laure Boulesteix demonstrate that some default values of hyperparameters as set by software packages (e.g., scikit-learn) lie outside the range of hyperparameter values that tend to yield optimal model performance across tasks and data; we can use solutions to the meta-interpretability problem to define better default values, or to define prior distributions for even more efficient random hyperparameter search (Bergtra and Bengio sample from a uniform distribution which we can replace by a “more informed” distribution).
Within organizations, these results suggest that one should track and store the results of hyperparameter tuning - not only the set of parameters that result in the best performing model, but all results. These results can be used to train surrogate models that allow us insight into the importance of hyperparameter values and increase the efficiency of hyperparameter tuning by defining sensible default values (or distributions) for the classes of problems tackled by data teams at these organizations.









