Sep 17, 2018 · post
Deep learning made easier with transfer learning
Deep learning has provided extraordinary advances in problem spaces that are poorly solved by other approaches. This success is due to several key departures from traditional machine learning that allow it to excel when applied to unstructured data. Today, deep learning models can play games, detect cancer, talk to humans, and drive cars.
But the differences that make deep learning powerful also make it costly. You may have heard that deep learning success requires massive data, expensive hardware, and even more expensive elite engineering talent.
At Cloudera Fast Forward Labs, we’re particularly excited about innovations that lessen these challenges. Our latest research report goes in depth on multi-task learning, an approach that allows machine learning models to learn from multiple tasks at once. Among its many benefits, this approach can reduce training data requirements.
In this article, we’re going to look at transfer learning, a related technique that enables the transfer of knowledge from one task to another. Rather than developing an entirely customized solution to your problem, transfer learning allows you to transfer knowledge from related problems to help solve your custom problem more easily. By transferring that knowledge, you are taking advantage of the expensive resources that were used to acquire it - training data, hardware, researchers - without the incurring the cost. Let’s see how and when this approach is effective.
Why deep learning is different
Transfer learning is not a new technique, nor is it specific to deep learning, but it is newly exciting in light of the recent progress in deep learning. So first, it’s important to spell out the ways in which deep learning is different than traditional machine learning.
Deep learning operates at a lower level of abstraction
Machine learning is a way for machines to automatically learn functions which assign predictions or labels to numerical inputs, i.e. data.
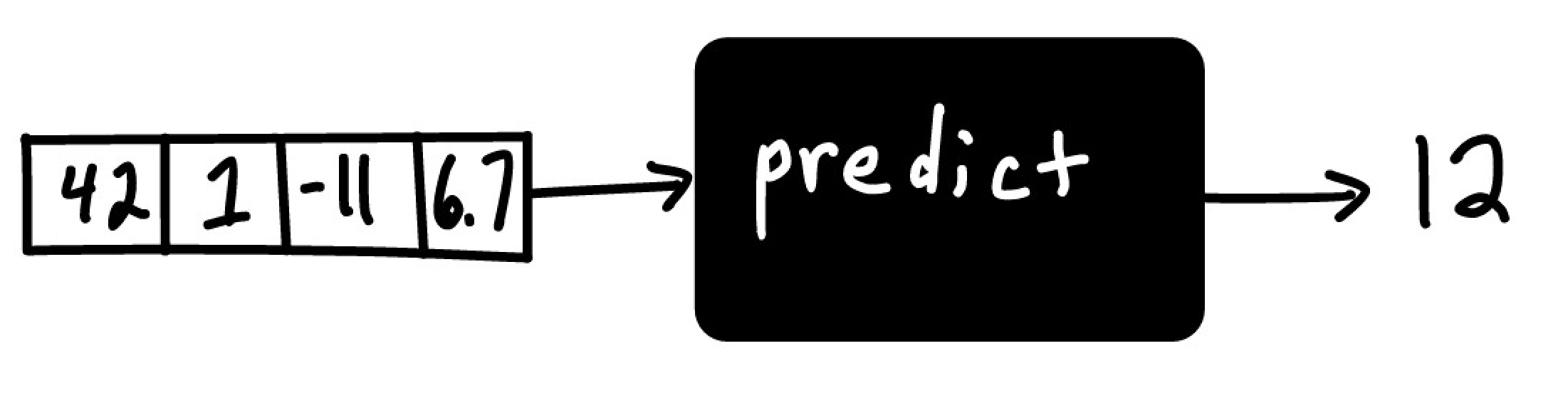
The difficult part here is determining exactly how the function produces the output from the provided input. Without any restrictions on the function, the possibilities (and complexities) are endless. In order to simplify this task, we usually impose some type of structure on the function - based on the type of problem we’re solving, domain expertise, or simply trial and error. That structure defines a type of machine learning model.
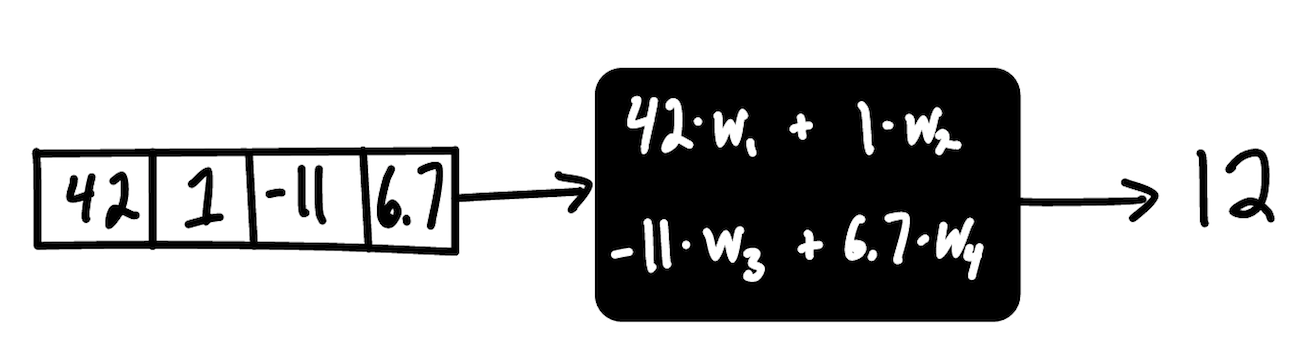
In theory, there are an infinity of possible structures, but in practice most machine learning use cases can be solved by applying one of only a handful of structures: linear models, ensembles of trees, and support vector machines make up a solid core. The data scientist’s job is then to choose the correct structure from this small set of possible structures.
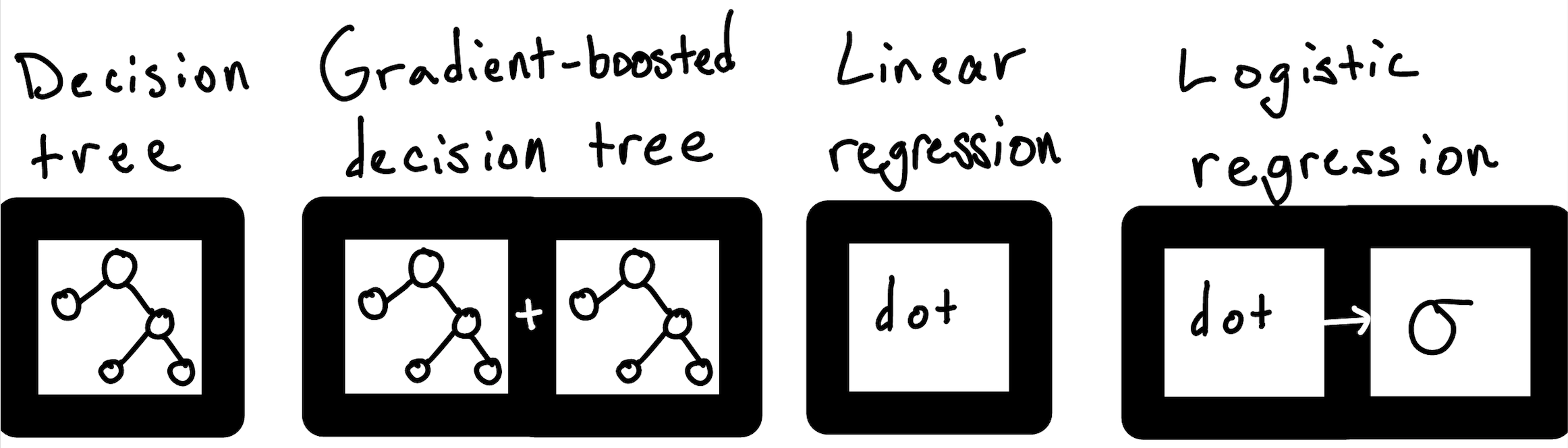
These models are available as black box objects from a variety of mature machine learning libraries, and can be trained in just a few lines of code. For example, you can train a random forest model using Python’s scikit-learn like this:
clf = RandomForestClassifier()
clf.fit(past_data, labels)
predictions = clf.predict(future_data)
Or a linear regression model in R:
linearModel <- lm(y ~ X, data=pastData)
predictions <- predict(linearModel, futureData)
Deep learning, however, operates at a lower level. Rather than choosing among a small, finite set of model structures, deep learning allows practitioners to compose arbitrary structures. The building blocks are modules or layers that can be thought of as basic, fundamental data transformations. This means that we need to open up the black box when applying deep learning, instead of treating it as fixed by the algorithm.
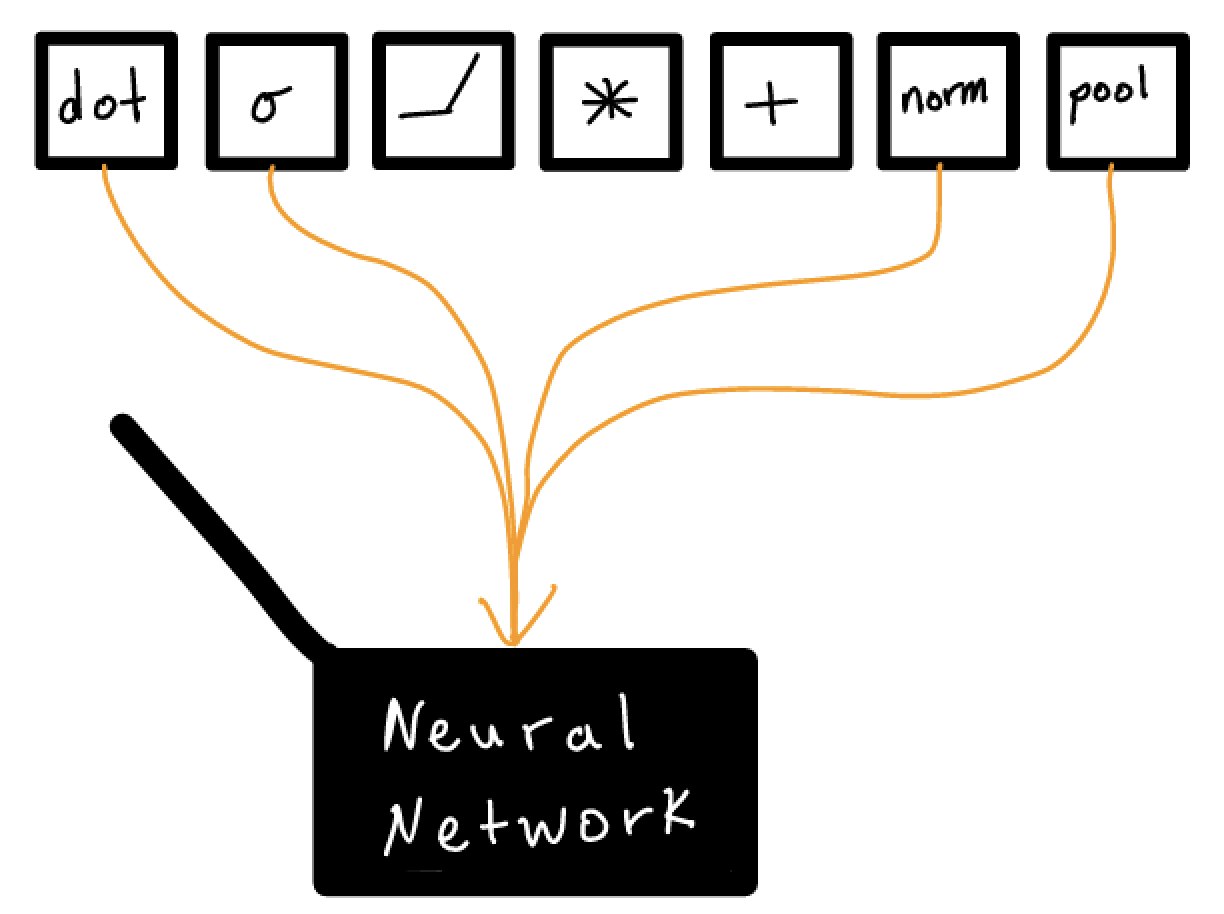
This allows more powerful models to be built, but it also adds an entirely new dimension to the model building process. Composing these transformations effectively can be a difficult process, despite the volume of published deep learning research, practical guidelines and folk wisdom.
Consider an extremely simple Convolutional Neural Network image classifier, defined here in the popular deep learning library PyTorch.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
Source: PyTorch
Because we are working with low level building blocks, we can change a
single component of the model (e.g. F.relu to F.sigmoid, for instance).
This gives us an entirely new model architecture that may yield dramatically
different results. And the possibilities are literally endless.
Deep learning is not yet well-understood
Even given a fixed neural network architecture, training is notoriously difficult. First, deep learning loss functions are not in general convex, which means that training does not necessarily yield the best possible solution. Second, deep learning is still very new and many of its components are not well-understood. For example, batch normalization has received attention recently because its inclusion in some models seems to be critical for good results, but experts cannot agree on why. Researcher Ali Rahimi caused some controversy when he went so far as to liken deep learning to alchemy at a recent machine learning conference.
Automatic Feature Engineering
The added complexity in deep learning enables a technique called representation learning, which is why it’s often stated that neural networks do “automatic feature engineering.” In short, instead of having a human hand-engineer helpful features from a dataset, we build models in such a way that they can learn whatever features are necessary and helpful for the task at hand. Offloading feature engineering onto the model is immensely powerful, but comes with the cost of models that require massive amounts of data and, consequently, massive computing power.
What you can do about it
Deep learning is so complex in comparison to other machine learning methods, that it can seem too overwhelming to incorporate into your business. For resource-constrained organizations, this feeling is magnified.
For organizations that truly need to operate on the bleeding edge, it may indeed be necessary to hire experts and purchase specialized hardware. But this is not necessary in many cases. There are ways to apply it effectively without making enormous investments. This is where transfer learning comes in.
Transfer learning enables the transfer of knowledge from one machine learning model to another. These models may be the result of years of research into model structure, trained on colossal datasets, and optimized over years of compute time. With transfer learning you can get much of the benefit of this work for none of the cost!
What is transfer learning?
Most machine learning tasks start with zero knowledge, meaning that the structure and parameters of the model begins as random guesses. This is what we mean when we say a model is learned from scratch.
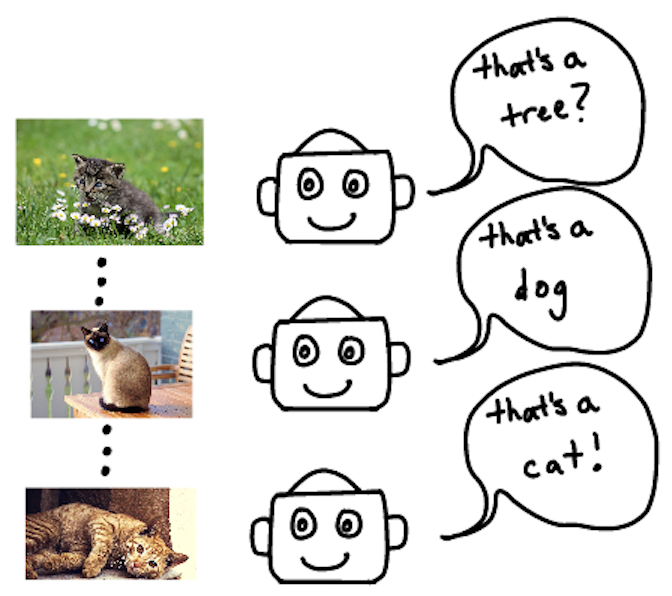
A cat detector model trained from scratch starts by guessing. It gradually learns what a cat is by aggregating common patterns across the many different cats it has seen.
In this situation, everything the model learns comes from the data that you show it. But is this the only way of solving a problem? In some cases, it might seem like it.
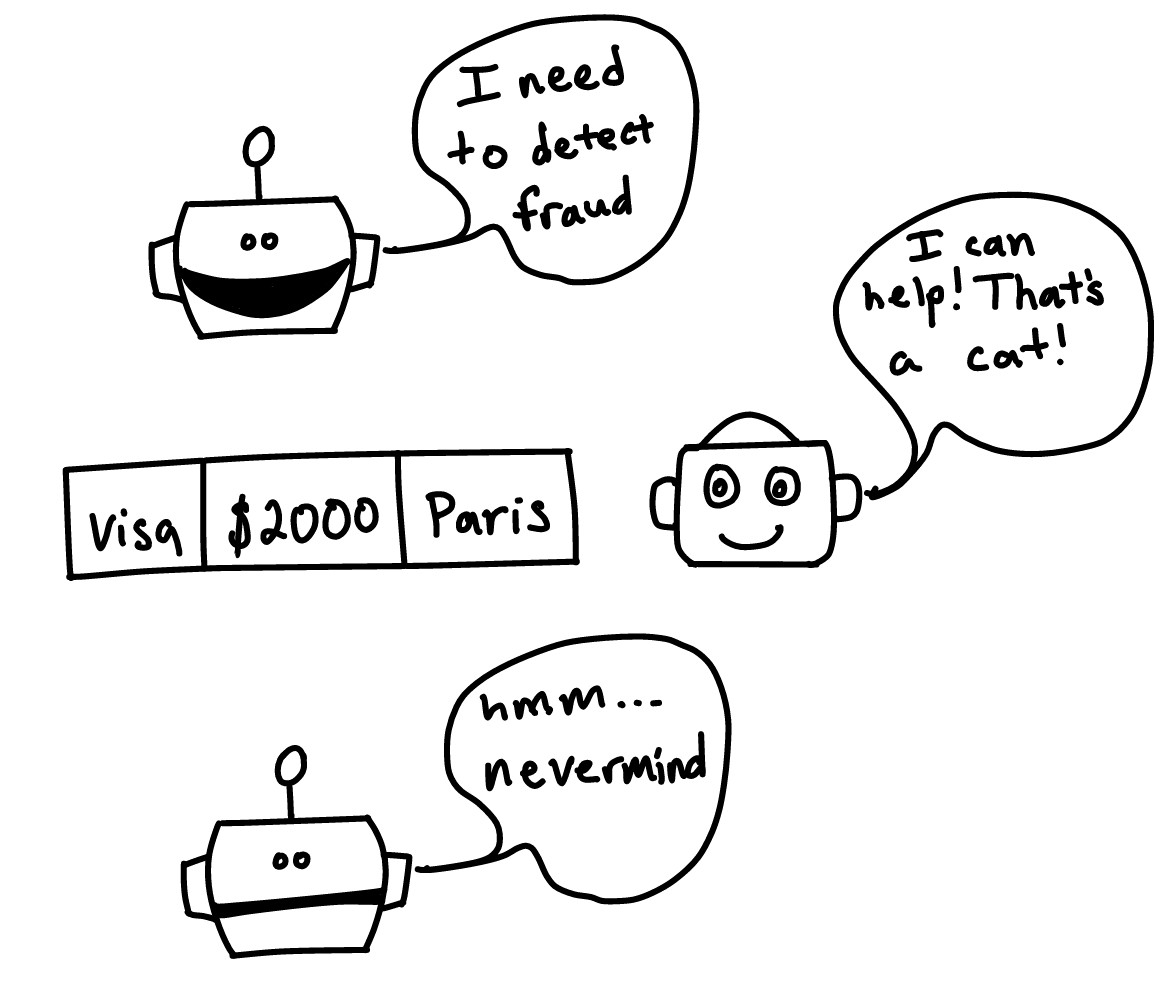
A cat detector model is likely useless in unrelated applications, like fraud detection. It only knows how to make sense of cat pictures, not credit card transactions.
But in other cases, it seems like we should be able to share information between tasks.
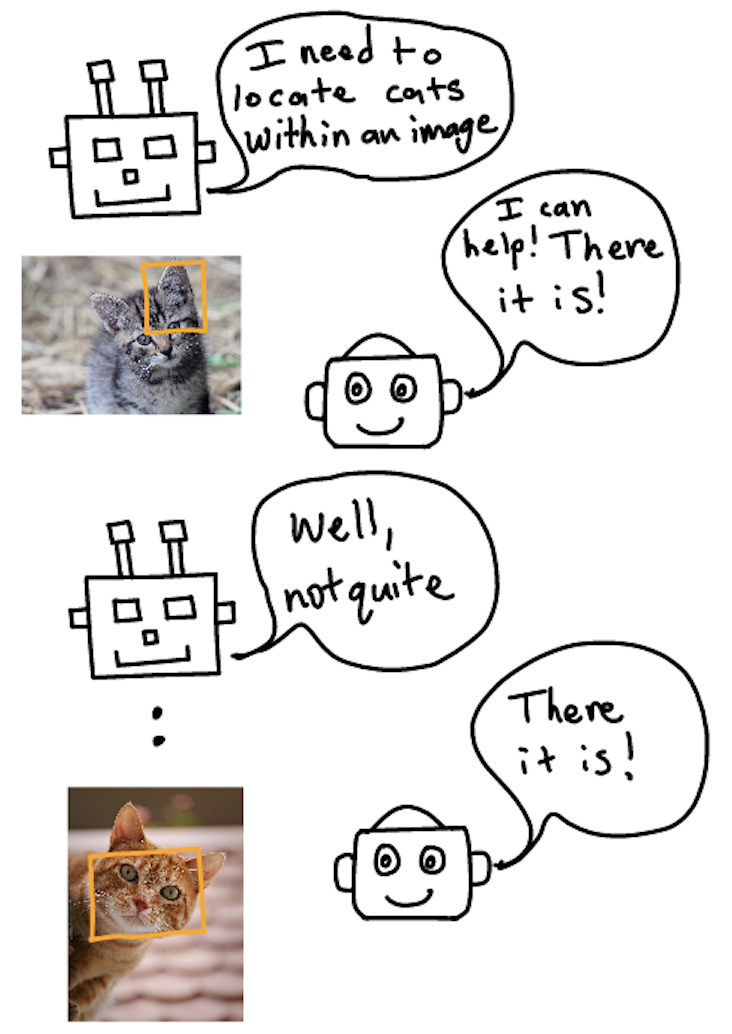
A cat detector is helpful in related tasks, like cat facial location. The detector should already know how to detect whiskers, noses, and eyes - all things that are useful in locating the cat’s face.
This is the essence of transfer learning: taking a model that has learned how to do one task very well and transferring some (or all) of that knowledge to a related task.
This makes sense when we examine our own learning experiences; we regularly transfer skills learned in the past to more quickly learn new skills. For example, someone who has learned to throw a baseball does not need to completely re-learn the mechanics of throwing a projectile to learn how to throw a football. These things are inherently related, and the ability to do one of them well naturally translates into the ability to do the other.
In the machine learning world, there is perhaps no better example than the field of computer vision over the last five years. It is now exceedingly rare to train an image model from scratch. Instead, we start with a pretrained model that already knows how to classify simple objects such as cats and dogs and umbrellas. Models that learn to classify images do so by first learning to detect general image features, such as edges, shapes, text, and faces. The pretrained model has these fundamental skills (as well as more specific skills, such as distinguishing between dogs and cats).
The pretrained classification model can then be slightly modified by adding layers or retraining on a new dataset, to carry over those expensively acquired fundamental skills to a new specialization. This is transfer learning.
The benefits of this approach are far-reaching.
Transfer learning needs less training data
When you re-use your favorite cat detection model in a new, cat-related task, your model already has “the wisdom of one million cats,” which means that you don’t need to use nearly as many cat pictures to train the new task. Reducing the size of training data can enable you to train in settings where there is very little data available and where more data may be expensive or impossible to obtain, and can also allow you to train models faster on cheaper hardware.
Models learned by transfer learning generalize better
Transfer learning improves generalization, or the ability of the model to perform well on data that it wasn’t trained on. This is because pre-trained models are purposefully trained on tasks that force the model to learn generic features that are useful in related contexts. When the model is transferred to a new task, it will be difficult to overfit to the new training data, since the model will only learn incrementally from a very general knowledge base. Building a model that generalizes well is one of the hardest and most important parts of machine learning.
The transfer learning training process is less brittle
Starting with a pre-trained model also helps overcome the frustrating, brittle, and confusing process of training a complex model with millions of parameters. Transfer learning reduces the number of trainable parameters by as much as 100%, making training more stable and easier to debug.
Transfer learning makes deep learning easier
Finally, transfer learning helps make deep learning more accessible, since you don’t need to be an expert yourself to obtain expert level results. Consider the popular image classification model Resnet-50.

How was that particular architecture chosen? It is the result of years of research and experimentation from various deep learning experts. Within this complicated structure there are 25 million weights, and optimizing these weights from scratch can be near impossible without extensive knowledge of each of the model’s components. Fortunately, with transfer learning you can re-use both the complicated structure and optimized weights, significantly lowering the barrier to entry for deep learning.
What about multi-task learning?
Transfer learning is one of a family of knowledge sharing techniques for training machine learning models that has proven to be extremely effective. Currently, the two most interesting of these techniques are transfer and multi-task learning. In transfer learning, a model is trained on a single task and then used as a starting point for a related task. In learning the related task, the original transferred model will learn to specialize in the new task, without concern of how that affects its performance on the original task. In multi-task learning, a single model learns to do multiple tasks at once, and the evaluation of its performance depends on how well it learns to do all those tasks. For a more detailed discussion on the benefits of multi-task learning and when it may be useful, see our latest research on multi-task learning.
Conclusion
Transfer learning is a knowledge-sharing technique that reduces the amount of training data, computing power, and engineering talent needed to build deep learning models. And since deep learning can provide significant improvements over its counterparts from traditional machine learning, transfer learning is an essential tool.









