Dec 28, 2018 · newsletter
The business case for federated learning
Last month, we released Federated Learning, the latest report and prototype from Cloudera Fast Forward Labs.
Federated learning makes it possible to build machine learning systems without direct access to training data. The data remains in its original location, which helps to ensure privacy and reduces communication costs.
Federated learning in a nutshell
To train a machine learning model you usually need to move all the data to a single machine or, failing that, to a cluster of machines in a data center.
This can be difficult for two reasons.
First, the creator of the data may simply not want to share it with you. Maybe the data is baby photos, or competitively sensitive manufacturing data, or legally protected medical data. We’ll give more examples below.
Second, there are often practical communication challenges. A huge amount of valuable training data is created on hardware at the edges of slow and unreliable networks, such as smartphones, IoT devices, or equipment in far-flung industrial facilities, such as mines and oil rigs. Communication with such devices can be slow and expensive.
The solution is federated learning. This is when a server coordinates a network of nodes, each of which has training data that it cannot or will not share directly. The nodes each train a local model, and it is that model which they share with the server. The server merges the models into a single federated model, sends the merged model back out to the nodes, and another round of local training takes place. (For much more technical detail, see our article on the Fast Forward Labs blog.)
Crucially: The server never has direct access to the training data. By moving models rather than training data, federated learning helps to ensure privacy and minimizes communication costs.
Let’s now look at some examples of what you can do with federated learning.
Smartphones
Machine learning has huge potential to improve the user experience on smartphones. Apps could learn to spot good baby photos and proactively offer to share them with friends and family. They could make it easier to write emails that are more likely to receive quick replies. And they could make composing text messages even quicker and easier by accurately suggesting the next phrase, whatever the language.
But aside from the practical challenge of getting this data off a device with a slow connection, the personal aspect of some of this data (what people type, where they travel, what websites they visit) makes it problematic. Users are reluctant to share this sensitive data, and possessing it exposes technology companies to security risks and regulatory burdens. These characteristics make it a great fit for federated learning. The use case is so compelling that it comes as no surprise that Google researchers are usually credited with its invention, and Samsung engineers have also contributed significant ideas.
Healthcare
The healthcare industry offers huge financial incentives to develop effective
treatments and predict outcomes. But the training data required to apply
machine learning to these problems is of course extremely sensitive. The
consequences of actual and potential privacy violations can be serious.
By keeping the training data in the hands of patients or providers, federated learning has the potential to make it possible to collaboratively build models that save lives and generate huge value. Paris-based Owkin is among the most ambitious users of federated learning that we spoke to during our research. They provide a platform that allows healthcare providers to collaborate on a wide range of healthcare problems.
Predictive maintenance
Suppose a manufacturer wants to develop a predictive maintenance model for a piece of equipment they sell. This model needs training data—but testing lots of turbines until they fail in order to acquire that data would be expensive for the manufacturer. It would be less costly for the manufacturer if its customers were to send it such data. More importantly, the failures actual customers experience will be more representative of real-world use than those the manufacturer would see in factory experiments. In short, training data acquired from customers would be cheaper and better.
But there are several problems. Some of their customers are reluctant to share details about equipment failures with vendors or competitors. Some operate in countries such as China, where industrial facilities can be legally prevented from exporting data. And, as a practical matter, the volume of data can be enormous, which makes streaming it back to the manufacturer an engineering challenge.
This too is a great fit for federated learning! If the manufacturer takes this approach, they can train a better model with less expense. And customers get access to a model that is better than one they could train on their own, without compromising the security of their data.
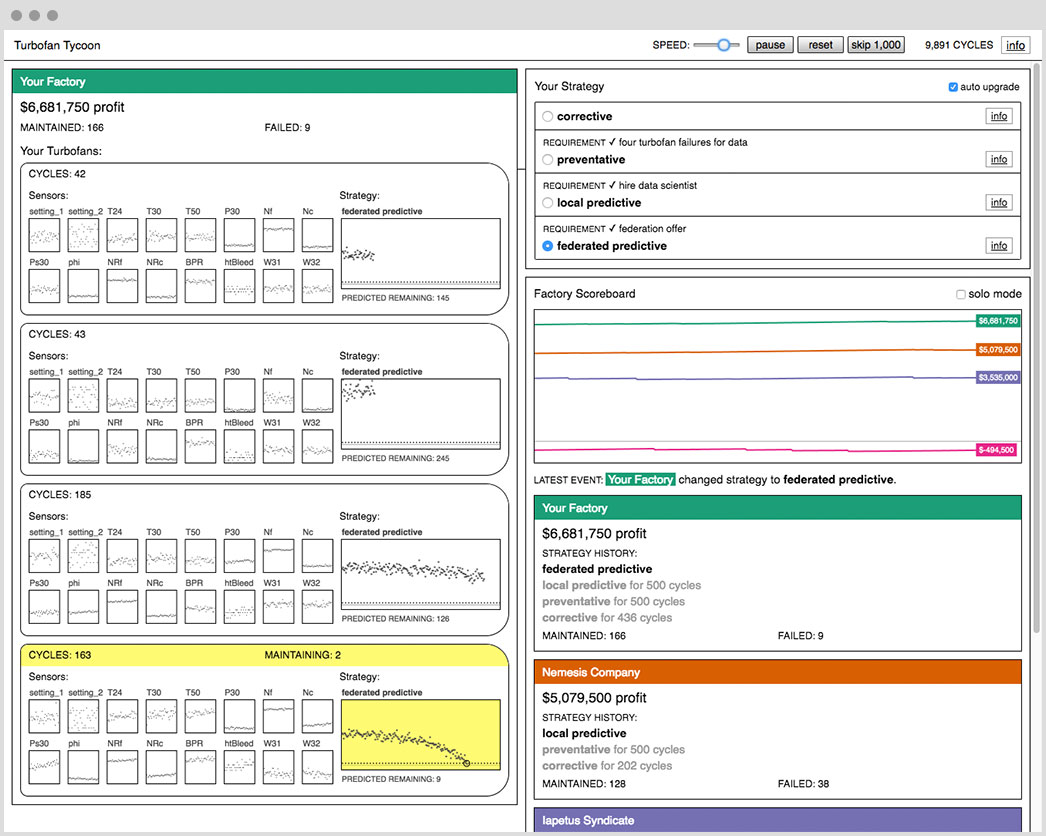
This situation is the focus of our interactive prototype, Turbofan Tycoon. In that, you play a user of industrial equipment who can adopt various maintenance strategies. Spoiler alert: the optimal strategy is federated learning, and the ROI relative to the alternatives huge!
Conclusion
In moving the majority of the work to the edge, federated learning is part of the trend to move machine learning out of the data center, for reasons that include speed and cost. But in federated learning, the edge nodes create and improve the model (rather than merely applying it). In this sense, federated learning goes far beyond what people usually mean when they talk about edge AI.
Federated learning makes it easier, safer and cheaper to apply machine learning in the world’s most regulated, competitive, and profitable industries.
This article only scratches the surface. Our report goes into much more detail, and covers use cases not mentioned here (including video analytics and corporate IT). And of course we get into the technical details, including systems and networking issues, libraries and frameworks, and practical recommendations based on our experience building Turbofan Tycoon.









