May 29, 2019 · newsletter
Open-ended Text Generation
The goal in open-ended text generation is to create a coherent portion of text that is a continuation from the given context. For example, given a couple of sentences, this capability makes it possible for machines to self-write a coherent story. One can imagine using such a system for AI-assisted writing, but of course it can also be repurposed to generate misleading (fake) news articles.
Ovid’s Unicorn, written by OpenAI’s GPT-2, offers a glimpse of the state-of-the art. Because it can generate astonishingly human-like passages, the full GPT-2 model was not released initially (in Feb 2019) due to ethical concerns. This decision resulted in a lively debate within the machine learning community. (OpenAI has since decided (in May 2019) to use two mechanisms for responsibly publishing GPT-2: staged release and partnership-based sharing.)
How text generation works
To generate text, we typically use a language model along with a decoder. The language model can be an LSTM, or something based on the Transformer architecture, such as the GPT model. The language model outputs the likelihood of each word in the vocabulary being the next word in the sequence. Ideally, the decoder then picks the best sequence of words that leads to the highest probability (likelihood) based on this information. To do this, one has to search through all the possible sequences of words - this computation is not tractable. As such, two approaches are used in practice: greedy search and beam search.
In greedy search, the decoder picks the word that has the highest likelihood of being the next word in the sequence. It only looks at the next word, and in doing so, is only exploring one path to building a sequence of words.
A better approach is beam search. Rather than exploring a single path, beam search keeps track of multiple paths. While beam search is effective for non-open-ended generation tasks such as machine translation, data-to-text generation, and summarization, it does not work well for open-ended text generation.
Why doesn’t beam search work for open-ended text generation?
Using beam search as a decoder for open-ended generation results in text that is strangely bland and repetitive. This is not because of “search error, where beam search failed to find higher quality sentences to which the model assigns higher probability than to the decoded ones.” Rather, the fundamental problem is the maximum likelihood decoding objective.

Example of degenerate text using beam search. (credit)
It turns out likelihood maximization approaches such as beam search tend to produce sentences that loop repetitively. Further, the probability of forming a loop (“I don’t know, I don’t know, I don’t know”) increases with a longer loop - once looping starts, it is difficult to get out of it. In addition, probability distribution of human-generated text turns out to be very different from machine-generated text. When using a maximum likelihood framework, the machine-generated text is composed of tokens that are highly probable, but human-generated text exhibits much richness and variance.
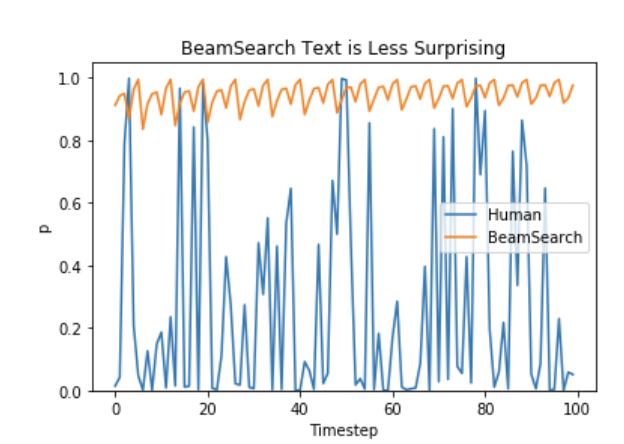
Human text is rich and surprising. (credit)
Randomize!
Recently two approaches based on the idea of randomization have been shown to work much better for open-ended generation. In top-k sampling, the decoder randomly samples from the top-k most likely next words. This is the approach used to generate Ovid’s Unicorn. Another approach is to “select the highest probability tokens whose cumulative probability mass exceeds a pre-chosen threshold”. In other words, instead of selecting k tokens, we select n tokens where the summation of the probability from all n tokens exceed a certain threshold, p. This results in a different number of possible next words (vs k fixed candidates) each time, and can be particularly effective when we have a large number of words with almost equal likelihoods. Using top-5, we would have just picked 5. The remaining (10 for example) will have been left out, even though these words have similar likelihood when compared to the top 5.
We are excited about the technical advances in open-ended text generation, but are cautiously optimistic for these advances to be put to good use for safe and ethical machine learning.









