Jul 8, 2019 · post
Taking Snorkel for a spin
Active learning, which we explored in our report on Learning with Limited Labeled Data, makes it possible to build machine learning models with a small set of labeled data. The typical simplified workflow when tackling a supervised machine learning problem is to i) locate the data, ii) create labels for all available data (the more the merrier), and iii) build a model. Instead of labeling all available data, active learning takes advantage of collaboration between humans and machines to smartly pick a small subset of data to be labeled. A machine learning model is then built using this small subset of data.
At the heart of active learning is the ability to identify difficult datapoints. Once identified, a human steps in to provide precise, high quality labels. But instead of asking a human to provide labels, can we write a function to programmatically create the labels? It turns out that the function that we are able to write does not always do a good job of labeling complex classification problems - the labeling function is typically based on heuristics and guesses. A single labeling function then, is not powerful enough. But what if we combine many such functions, and use the agreements and disagreements between them to figure out what the most likely label is; would that work?
This is the premise of Snorkel - a weak supervision framework.
The general idea of Snorkel
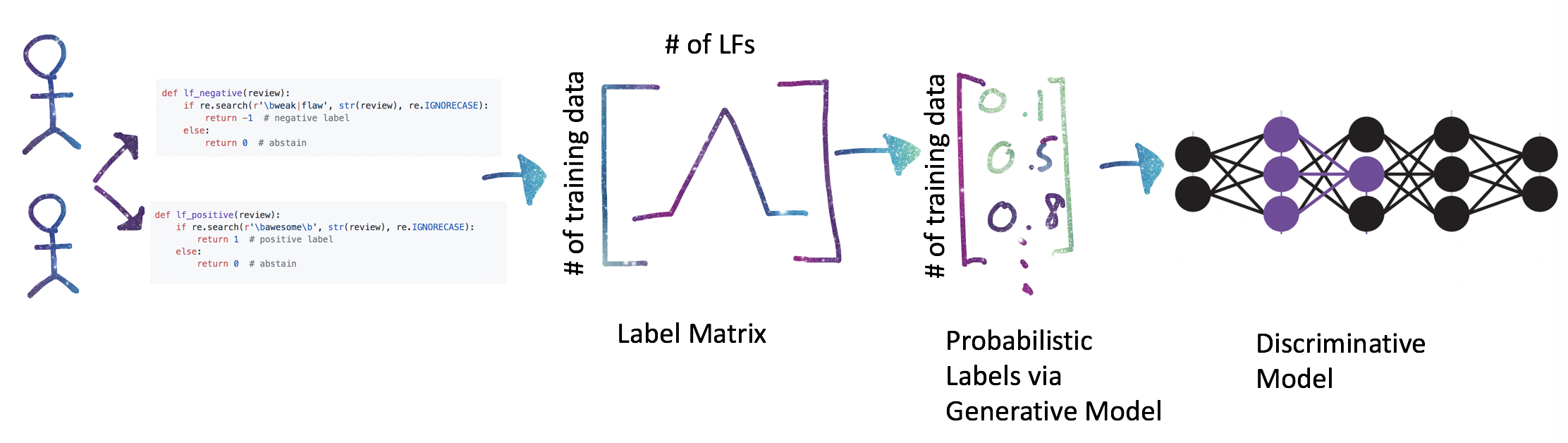
Let’s take a look at the components of Snorkel. To use Snorkel, one first needs to define a candidate. This represents the “thing” we are attempting to label. If we are trying to label whether a relationship exists between two persons, a candidate is a pair of persons. If we are trying to predict sentiment of a movie review, a candidate is just the movie review itself. The preprocessing step for Snorkel then, is to extract all possible candidates from our unlabeled data.
# An example of a candidate for predicting movie sentiment
Review = candidate_subclass('Review', ['review'])
Once we have these candidates, we split them into test, train, and validation sets, as we normally do. At this point, we are ready to write labeling functions. Each labeling function takes in a candidate, and uses heuristics to determine a label. In the binary classification example, the labeling function outputs a 1 (positive), -1 (negative), or 0 (abstain - the labeling function chooses not to label). To label if a relationship exists between two persons, we might look for the word spouse between the person names. To label movie review sentiment, we might look for the word horrible in the review in order to create a negative label. These labeling functions do not need to be precise, and we should write many of them. We can also include labels from crowdsourcing results, knowledge bases, and weak classifiers. We collect all labeling functions, and apply them to each candidate. This will give us a matrix of labels; the size of the matrix is number of candidates x number of labeling functions.
'''
labeling function to look for specific words in a candidate that would cause
it to be labeled as positive.
'''
def lf_positive(review):
if re.search(r'\bawesome\b', str(review), re.IGNORECASE):
return 1 # positive label
else:
return 0 # abstain
'''
labeling function to look for specific words in a candidate that would cause
it to be labeled as negative
'''
def lf_negative(review):
if re.search(r'\bweak|\bflaw', str(review), re.IGNORECASE):
return -1 # negative label
else:
return 0 # abstain
The next step is to train a generative model using this large matrix of labels. The generative model is just a probability distribution over the latent variable (the unobservable true label, since our data is unlabeled). The generative model estimates the accuracy of the labeling function while automatically taking into account the pairwise correlation between these functions and labeling propensity (how often a function actually creates a label). Once the model is trained, it can be used to estimate the true label for each candidate. These labels are numbers between 0 and 1, representing the probability of a positive class, and are known as probabilistic labels.
So far, we haven’t had to use any actual labels (gold labels) yet. Although we can get to the generative model without them, having a small set of labeled data is helpful for refining and iterating over the labeling functions. Once the generative model is trained, we can i) create a label matrix on the validation dataset using all labeling functions, ii) use the generative model on this label matrix to get a set of probabilistic labels, and iii) perform error analysis (precision, recall, F1 scores) by comparing to the gold labels.
Iterating this way implies that our labeling functions can overfit to the validation dataset. Hence, the last step is to feed the probabilistic labels into a discriminative model, which generalizes beyond the information expressed in the labeling functions, and typically increases recall (the proportion of actual positive labels that were identified correctly). We also want the discriminative model to learn more from high-confidence training labels rather than treating the noisy probabilistic labels as ground truth. This just means that the loss function should be the cross-entropy loss between the probabilistic labels and the output of a logistic function. See Step 3 for derivation. In Tensorflow, this can be computed using tf.nn.sigmoid_cross_entropy_with_logits.
Why do we need a generative model?
We could have just used majority voting - the correct label is the one that has the most votes from all the labeling functions. This approach does not capture correlation, redundancy, and other more complex information hidden in the labeling matrix. Imagine the following scenario where you have two labeling functions - a high accuracy function which created labels for ten thousand data points, and a low accuracy function which created labels for one million datapoints. Given the two different labeling propensities, what is the right way to combine them? The generative model weights these functions accordingly.
Using Snorkel to classify complaints
The idea of building a generative model that can tease out complex hidden relationships between labeling functions in order to create a set of probabilistic labels sounds very appealing. Instead of just reading about the approach, we used Snorkel to build a complaint classifier using data from Consumer Financial Protection Bureau. See our notebook for details.
Practical Considerations
Our experience with Snorkel taught us a few things.
The Snorkel project is active and ongoing. The code examples are of immense help, but as with most machine learning packages, there is a learning curve for first-time users. The current state of documentation makes it most suitable for developer data scientists who can explore the nuts and bolts of the underlying code.
Specific to work flow, after using Snorkel to build the generative model, one has a choice of a) using existing noise-aware discriminative models in Snorkel’s library to train a classifier or b) export the probabilistic training labels and use it to train any other model (PyTorch or scikit-learn model, for example). Choosing b) implies that the model needs to be able to handle probabilistic training labels. In addition, the candidates within Snorkel need to be converted into a format that works with the model. Our experiment used the first approach, but we could have made the second approach work relatively quickly.
If you are thinking of using Snorkel in production, the data scientists need to first set up a Snorkel pipeline. This includes defining candidates, creating a few labeling functions, training the generative model, setting up the framework to iterate on labeling functions, and defining the discriminative model. Once this is in place, subject matter experts (SMEs) need to be taught to write labeling functions. Alternatively, SMEs can work together with data scientists to transfer any domain knowledge (including rules or patterns to look for) that will help create labeling functions. These functions generate either positive or negative labels (in the binary classification case) and at times abstain from labeling; they should perform better than a random label generator.
Snorkel has two more major advantages in addition to the ability to incorporate human domain expertise. First, it is good for fast and flexible label generation. In essence, when using Snorkel one can think of training data as “a collection of labeling functions.” If and when the training goal changes, a quick rewrite or modification of those labeling functions will put you back on track. It is also easy to adjust labels since we can quickly modify the labeling function itself. A nice side effect of creating labeling functions is that the classification problem becomes a little more interpretable!
Another advantage of Snorkel is that less precise and low quality labels can now be used. Instead of discarding low quality crowdsourced labels, we can now include them in the large label matrix and rely on the generative model to tease out useful information (although more labeling functions imply longer training times for the generative model). Intuitively, learning the generative model’s parameters is possible when we have sufficient better-than-random weak supervision sources available. Having enough sources allows one to better estimate the true (latent) class labels.
Conclusion
Snorkel and active learning both attempt to enable learning with limited labeled data. Active learning introduces human expertise into the loop to smartly label a small set of data; Snorkel removes humans from the labeling process, but finds a way to smartly combine a large number of noisy, low quality - and, in some cases - automatically generated labels (albeit retaining human domain knowledge). Snorkel provides an interesting take, and leaves us wondering if large fleets of human annotators will be replaced ultimately by a small set of “labeling function creators” who have domain expertise.









